Compare commits
No commits in common. "master" and "v1.1.0" have entirely different histories.
@ -1,5 +0,0 @@
|
|||||||
aks
|
|
||||||
ec2
|
|
||||||
eks
|
|
||||||
gce
|
|
||||||
gcp
|
|
||||||
1
.github/CODEOWNERS
vendored
1
.github/CODEOWNERS
vendored
@ -1 +0,0 @@
|
|||||||
* @longhorn/dev
|
|
||||||
48
.github/ISSUE_TEMPLATE/bug.md
vendored
48
.github/ISSUE_TEMPLATE/bug.md
vendored
@ -1,48 +0,0 @@
|
|||||||
---
|
|
||||||
name: Bug report
|
|
||||||
about: Create a bug report
|
|
||||||
title: "[BUG]"
|
|
||||||
labels: ["kind/bug", "require/qa-review-coverage", "require/backport"]
|
|
||||||
assignees: ''
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
## Describe the bug (🐛 if you encounter this issue)
|
|
||||||
|
|
||||||
<!--A clear and concise description of what the bug is.-->
|
|
||||||
|
|
||||||
## To Reproduce
|
|
||||||
|
|
||||||
<!--Provide the steps to reproduce the behavior.-->
|
|
||||||
|
|
||||||
## Expected behavior
|
|
||||||
|
|
||||||
<!--A clear and concise description of what you expected to happen.-->
|
|
||||||
|
|
||||||
## Support bundle for troubleshooting
|
|
||||||
|
|
||||||
<!--Provide a support bundle when the issue happens. You can generate a support bundle using the link at the footer of the Longhorn UI. Check [here](https://longhorn.io/docs/latest/advanced-resources/support-bundle/).-->
|
|
||||||
|
|
||||||
## Environment
|
|
||||||
|
|
||||||
<!-- Suggest checking the doc of the best practices of using Longhorn. [here](https://longhorn.io/docs/1.5.1/best-practices)-->
|
|
||||||
- Longhorn version:
|
|
||||||
- Installation method (e.g. Rancher Catalog App/Helm/Kubectl):
|
|
||||||
- Kubernetes distro (e.g. RKE/K3s/EKS/OpenShift) and version:
|
|
||||||
- Number of management node in the cluster:
|
|
||||||
- Number of worker node in the cluster:
|
|
||||||
- Node config
|
|
||||||
- OS type and version:
|
|
||||||
- Kernel version:
|
|
||||||
- CPU per node:
|
|
||||||
- Memory per node:
|
|
||||||
- Disk type(e.g. SSD/NVMe/HDD):
|
|
||||||
- Network bandwidth between the nodes:
|
|
||||||
- Underlying Infrastructure (e.g. on AWS/GCE, EKS/GKE, VMWare/KVM, Baremetal):
|
|
||||||
- Number of Longhorn volumes in the cluster:
|
|
||||||
- Impacted Longhorn resources:
|
|
||||||
- Volume names:
|
|
||||||
|
|
||||||
## Additional context
|
|
||||||
|
|
||||||
<!--Add any other context about the problem here.-->
|
|
||||||
40
.github/ISSUE_TEMPLATE/bug_report.md
vendored
Normal file
40
.github/ISSUE_TEMPLATE/bug_report.md
vendored
Normal file
@ -0,0 +1,40 @@
|
|||||||
|
---
|
||||||
|
name: Bug report
|
||||||
|
about: Create a report to help us improve
|
||||||
|
title: "[BUG]"
|
||||||
|
labels: ''
|
||||||
|
assignees: ''
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
**Describe the bug**
|
||||||
|
A clear and concise description of what the bug is.
|
||||||
|
|
||||||
|
**To Reproduce**
|
||||||
|
Steps to reproduce the behavior:
|
||||||
|
1. Go to '...'
|
||||||
|
2. Click on '....'
|
||||||
|
3. Perform '....'
|
||||||
|
4. See error
|
||||||
|
|
||||||
|
**Expected behavior**
|
||||||
|
A clear and concise description of what you expected to happen.
|
||||||
|
|
||||||
|
**Log**
|
||||||
|
If applicable, add the Longhorn managers' log when the issue happens.
|
||||||
|
|
||||||
|
You can also attach a *Support Bundle* here. You can generate a Support Bundle using the link at the footer of the Longhorn UI.
|
||||||
|
|
||||||
|
**Environment:**
|
||||||
|
- Longhorn version:
|
||||||
|
- Kubernetes distro (e.g. RKE/K3s/EKS/OpenShift) and version:
|
||||||
|
- Node config
|
||||||
|
- OS type and version:
|
||||||
|
- CPU per node:
|
||||||
|
- Memory per node:
|
||||||
|
- Disk type(e.g. SSD/NVMe):
|
||||||
|
- Network bandwidth and latency between the nodes:
|
||||||
|
- Underlying Infrastructure (e.g. on AWS/GCE, EKS/GKE, VMWare/KVM, Baremetal):
|
||||||
|
|
||||||
|
**Additional context**
|
||||||
|
Add any other context about the problem here.
|
||||||
16
.github/ISSUE_TEMPLATE/doc.md
vendored
16
.github/ISSUE_TEMPLATE/doc.md
vendored
@ -1,16 +0,0 @@
|
|||||||
---
|
|
||||||
name: Document
|
|
||||||
about: Create or update document
|
|
||||||
title: "[DOC] "
|
|
||||||
labels: kind/doc
|
|
||||||
assignees: ''
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
## What's the document you plan to update? Why? Please describe
|
|
||||||
|
|
||||||
<!--A clear and concise description of what the document is.-->
|
|
||||||
|
|
||||||
## Additional context
|
|
||||||
|
|
||||||
<!--Add any other context or screenshots about the document request here.-->
|
|
||||||
24
.github/ISSUE_TEMPLATE/feature.md
vendored
24
.github/ISSUE_TEMPLATE/feature.md
vendored
@ -1,24 +0,0 @@
|
|||||||
---
|
|
||||||
name: Feature request
|
|
||||||
about: Suggest an idea/feature
|
|
||||||
title: "[FEATURE] "
|
|
||||||
labels: ["kind/enhancement", "require/lep", "require/doc", "require/auto-e2e-test"]
|
|
||||||
assignees: ''
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
## Is your feature request related to a problem? Please describe (👍 if you like this request)
|
|
||||||
|
|
||||||
<!--A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]-->
|
|
||||||
|
|
||||||
## Describe the solution you'd like
|
|
||||||
|
|
||||||
<!--A clear and concise description of what you want to happen-->
|
|
||||||
|
|
||||||
## Describe alternatives you've considered
|
|
||||||
|
|
||||||
<!--A clear and concise description of any alternative solutions or features you've considered.-->
|
|
||||||
|
|
||||||
## Additional context
|
|
||||||
|
|
||||||
<!--Add any other context or screenshots about the feature request here.-->
|
|
||||||
20
.github/ISSUE_TEMPLATE/feature_request.md
vendored
Normal file
20
.github/ISSUE_TEMPLATE/feature_request.md
vendored
Normal file
@ -0,0 +1,20 @@
|
|||||||
|
---
|
||||||
|
name: Feature request
|
||||||
|
about: Suggest an idea for this project
|
||||||
|
title: "[FEATURE]"
|
||||||
|
labels: ''
|
||||||
|
assignees: ''
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
**Is your feature request related to a problem? Please describe.**
|
||||||
|
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
|
||||||
|
|
||||||
|
**Describe the solution you'd like**
|
||||||
|
A clear and concise description of what you want to happen.
|
||||||
|
|
||||||
|
**Describe alternatives you've considered**
|
||||||
|
A clear and concise description of any alternative solutions or features you've considered.
|
||||||
|
|
||||||
|
**Additional context**
|
||||||
|
Add any other context or screenshots about the feature request here.
|
||||||
24
.github/ISSUE_TEMPLATE/improvement.md
vendored
24
.github/ISSUE_TEMPLATE/improvement.md
vendored
@ -1,24 +0,0 @@
|
|||||||
---
|
|
||||||
name: Improvement request
|
|
||||||
about: Suggest an improvement of an existing feature
|
|
||||||
title: "[IMPROVEMENT] "
|
|
||||||
labels: ["kind/improvement", "require/doc", "require/auto-e2e-test", "require/backport"]
|
|
||||||
assignees: ''
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
## Is your improvement request related to a feature? Please describe (👍 if you like this request)
|
|
||||||
|
|
||||||
<!--A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]-->
|
|
||||||
|
|
||||||
## Describe the solution you'd like
|
|
||||||
|
|
||||||
<!--A clear and concise description of what you want to happen.-->
|
|
||||||
|
|
||||||
## Describe alternatives you've considered
|
|
||||||
|
|
||||||
<!--A clear and concise description of any alternative solutions or features you've considered.-->
|
|
||||||
|
|
||||||
## Additional context
|
|
||||||
|
|
||||||
<!--Add any other context or screenshots about the feature request here.-->
|
|
||||||
24
.github/ISSUE_TEMPLATE/infra.md
vendored
24
.github/ISSUE_TEMPLATE/infra.md
vendored
@ -1,24 +0,0 @@
|
|||||||
---
|
|
||||||
name: Infra
|
|
||||||
about: Create an test/dev infra task
|
|
||||||
title: "[INFRA] "
|
|
||||||
labels: kind/infra
|
|
||||||
assignees: ''
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
## What's the test to develop? Please describe
|
|
||||||
|
|
||||||
<!--A clear and concise description of what test/dev infra you want to develop.-->
|
|
||||||
|
|
||||||
## Describe the items of the test development (DoD, definition of done) you'd like
|
|
||||||
|
|
||||||
<!--
|
|
||||||
Please use a task list for items on a separate line with a clickable checkbox https://docs.github.com/en/issues/tracking-your-work-with-issues/about-task-lists
|
|
||||||
|
|
||||||
- [ ] `item 1`
|
|
||||||
-->
|
|
||||||
|
|
||||||
## Additional context
|
|
||||||
|
|
||||||
<!--Add any other context or screenshots about the test infra request here.-->
|
|
||||||
19
.github/ISSUE_TEMPLATE/question.md
vendored
19
.github/ISSUE_TEMPLATE/question.md
vendored
@ -1,28 +1,23 @@
|
|||||||
---
|
---
|
||||||
name: Question
|
name: Question
|
||||||
about: Have a question
|
about: Question on Longhorn
|
||||||
title: "[QUESTION] "
|
title: "[Question]"
|
||||||
labels: kind/question
|
labels: question
|
||||||
assignees: ''
|
assignees: ''
|
||||||
|
|
||||||
---
|
---
|
||||||
## Question
|
**Question**
|
||||||
|
|
||||||
<!--Suggest to use https://github.com/longhorn/longhorn/discussions to ask questions.-->
|
|
||||||
|
|
||||||
## Environment
|
|
||||||
|
|
||||||
|
**Environment:**
|
||||||
- Longhorn version:
|
- Longhorn version:
|
||||||
- Kubernetes version:
|
- Kubernetes version:
|
||||||
- Node config
|
- Node config
|
||||||
- OS type and version
|
- OS type and version
|
||||||
- Kernel version
|
|
||||||
- CPU per node:
|
- CPU per node:
|
||||||
- Memory per node:
|
- Memory per node:
|
||||||
- Disk type
|
- Disk type
|
||||||
- Network bandwidth and latency between the nodes:
|
- Network bandwidth and latency between the nodes:
|
||||||
- Underlying Infrastructure (e.g. on AWS/GCE, EKS/GKE, VMWare/KVM, Baremetal):
|
- Underlying Infrastructure (e.g. on AWS/GCE, EKS/GKE, VMWare/KVM, Baremetal):
|
||||||
|
|
||||||
## Additional context
|
**Additional context**
|
||||||
|
Add any other context about the problem here.
|
||||||
<!--Add any other context about the problem here.-->
|
|
||||||
|
|||||||
24
.github/ISSUE_TEMPLATE/refactor.md
vendored
24
.github/ISSUE_TEMPLATE/refactor.md
vendored
@ -1,24 +0,0 @@
|
|||||||
---
|
|
||||||
name: Refactor request
|
|
||||||
about: Suggest a refactoring request for an existing implementation
|
|
||||||
title: "[REFACTOR] "
|
|
||||||
labels: kind/refactoring
|
|
||||||
assignees: ''
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
## Is your improvement request related to a feature? Please describe
|
|
||||||
|
|
||||||
<!--A clear and concise description of what the problem is.-->
|
|
||||||
|
|
||||||
## Describe the solution you'd like
|
|
||||||
|
|
||||||
<!--A clear and concise description of what you want to happen.-->
|
|
||||||
|
|
||||||
## Describe alternatives you've considered
|
|
||||||
|
|
||||||
<!--A clear and concise description of any alternative solutions or features you've considered.-->
|
|
||||||
|
|
||||||
## Additional context
|
|
||||||
|
|
||||||
<!--Add any other context or screenshots about the refactoring request here.-->
|
|
||||||
35
.github/ISSUE_TEMPLATE/release.md
vendored
35
.github/ISSUE_TEMPLATE/release.md
vendored
@ -1,35 +0,0 @@
|
|||||||
---
|
|
||||||
name: Release task
|
|
||||||
about: Create a release task
|
|
||||||
title: "[RELEASE]"
|
|
||||||
labels: release/task
|
|
||||||
assignees: ''
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
**What's the task? Please describe.**
|
|
||||||
Action items for releasing v<x.y.z>
|
|
||||||
|
|
||||||
**Describe the sub-tasks.**
|
|
||||||
- Pre-Release
|
|
||||||
- [ ] Regression test plan (manual) - @khushboo-rancher
|
|
||||||
- [ ] Run e2e regression for pre-GA milestones (`install`, `upgrade`) - @yangchiu
|
|
||||||
- [ ] Run security testing of container images for pre-GA milestones - @yangchiu
|
|
||||||
- [ ] Verify longhorn chart PR to ensure all artifacts are ready for GA (`install`, `upgrade`) @chriscchien
|
|
||||||
- [ ] Run core testing (install, upgrade) for the GA build from the previous patch and the last patch of the previous feature release (1.4.2). - @yangchiu
|
|
||||||
- Release
|
|
||||||
- [ ] Release longhorn/chart from the release branch to publish to ArtifactHub
|
|
||||||
- [ ] Release note
|
|
||||||
- [ ] Deprecation note
|
|
||||||
- [ ] Upgrade notes including highlighted notes, deprecation, compatible changes, and others impacting the current users
|
|
||||||
- Post-Release
|
|
||||||
- [ ] Create a new release branch of manager/ui/tests/engine/longhorn instance-manager/share-manager/backing-image-manager when creating the RC1
|
|
||||||
- [ ] Update https://github.com/longhorn/longhorn/blob/master/deploy/upgrade_responder_server/chart-values.yaml @PhanLe1010
|
|
||||||
- [ ] Add another request for the rancher charts for the next patch release (`1.5.1`) @rebeccazzzz
|
|
||||||
- Rancher charts: verify the chart is able to install & upgrade - @khushboo-rancher
|
|
||||||
- [ ] rancher/image-mirrors update @weizhe0422 (@PhanLe1010 )
|
|
||||||
- https://github.com/rancher/image-mirror/pull/412
|
|
||||||
- [ ] rancher/charts 2.7 branches for rancher marketplace @weizhe0422 (@PhanLe1010)
|
|
||||||
- `dev-2.7`: https://github.com/rancher/charts/pull/2766
|
|
||||||
|
|
||||||
cc @longhorn/qa @longhorn/dev
|
|
||||||
24
.github/ISSUE_TEMPLATE/task.md
vendored
24
.github/ISSUE_TEMPLATE/task.md
vendored
@ -1,24 +0,0 @@
|
|||||||
---
|
|
||||||
name: Task
|
|
||||||
about: Create a general task
|
|
||||||
title: "[TASK] "
|
|
||||||
labels: kind/task
|
|
||||||
assignees: ''
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
## What's the task? Please describe
|
|
||||||
|
|
||||||
<!--A clear and concise description of what the task is.-->
|
|
||||||
|
|
||||||
## Describe the sub-tasks
|
|
||||||
|
|
||||||
<!--
|
|
||||||
Please use a task list for items on a separate line with a clickable checkbox https://docs.github.com/en/issues/tracking-your-work-with-issues/about-task-lists
|
|
||||||
|
|
||||||
- [ ] `item 1`
|
|
||||||
-->
|
|
||||||
|
|
||||||
## Additional context
|
|
||||||
|
|
||||||
<!--Add any other context or screenshots about the task request here.-->
|
|
||||||
24
.github/ISSUE_TEMPLATE/test.md
vendored
24
.github/ISSUE_TEMPLATE/test.md
vendored
@ -1,24 +0,0 @@
|
|||||||
---
|
|
||||||
name: Test
|
|
||||||
about: Create or update test
|
|
||||||
title: "[TEST] "
|
|
||||||
labels: kind/test
|
|
||||||
assignees: ''
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
## What's the test to develop? Please describe
|
|
||||||
|
|
||||||
<!--A clear and concise description of what test you want to develop.-->
|
|
||||||
|
|
||||||
## Describe the tasks for the test
|
|
||||||
|
|
||||||
<!--
|
|
||||||
Please use a task list for items on a separate line with a clickable checkbox https://docs.github.com/en/issues/tracking-your-work-with-issues/about-task-lists
|
|
||||||
|
|
||||||
- [ ] `item 1`
|
|
||||||
-->
|
|
||||||
|
|
||||||
## Additional context
|
|
||||||
|
|
||||||
<!--Add any other context or screenshots about the test request here.-->
|
|
||||||
34
.github/mergify.yml
vendored
34
.github/mergify.yml
vendored
@ -1,34 +0,0 @@
|
|||||||
pull_request_rules:
|
|
||||||
- name: automatic merge after review
|
|
||||||
conditions:
|
|
||||||
- check-success=continuous-integration/drone/pr
|
|
||||||
- check-success=DCO
|
|
||||||
- check-success=CodeFactor
|
|
||||||
- check-success=codespell
|
|
||||||
- "#approved-reviews-by>=1"
|
|
||||||
- approved-reviews-by=@longhorn/maintainer
|
|
||||||
- label=ready-to-merge
|
|
||||||
actions:
|
|
||||||
merge:
|
|
||||||
method: rebase
|
|
||||||
|
|
||||||
- name: ask to resolve conflict
|
|
||||||
conditions:
|
|
||||||
- conflict
|
|
||||||
actions:
|
|
||||||
comment:
|
|
||||||
message: This pull request is now in conflicts. Could you fix it @{{author}}? 🙏
|
|
||||||
|
|
||||||
# Comment on the PR to trigger backport. ex: @Mergifyio copy stable/3.1 stable/4.0
|
|
||||||
- name: backport patches to stable branch
|
|
||||||
conditions:
|
|
||||||
- base=master
|
|
||||||
actions:
|
|
||||||
backport:
|
|
||||||
title: "[BACKPORT][{{ destination_branch }}] {{ title }}"
|
|
||||||
body: |
|
|
||||||
This is an automatic backport of pull request #{{number}}.
|
|
||||||
|
|
||||||
{{cherry_pick_error}}
|
|
||||||
assignees:
|
|
||||||
- "{{ author }}"
|
|
||||||
63
.github/stale.yml
vendored
Normal file
63
.github/stale.yml
vendored
Normal file
@ -0,0 +1,63 @@
|
|||||||
|
# Configuration for probot-stale - https://github.com/probot/stale
|
||||||
|
|
||||||
|
# Number of days of inactivity before an Issue or Pull Request becomes stale
|
||||||
|
daysUntilStale: 60
|
||||||
|
|
||||||
|
# Number of days of inactivity before an Issue or Pull Request with the stale label is closed.
|
||||||
|
# Set to false to disable. If disabled, issues still need to be closed manually, but will remain marked as stale.
|
||||||
|
daysUntilClose: 7
|
||||||
|
|
||||||
|
# Only issues or pull requests with all of these labels are check if stale. Defaults to `[]` (disabled)
|
||||||
|
onlyLabels: []
|
||||||
|
|
||||||
|
# Issues or Pull Requests with these labels will never be considered stale. Set to `[]` to disable
|
||||||
|
exemptLabels:
|
||||||
|
- bug
|
||||||
|
- doc
|
||||||
|
- enhancement
|
||||||
|
- poc
|
||||||
|
- refactoring
|
||||||
|
|
||||||
|
# Set to true to ignore issues in a project (defaults to false)
|
||||||
|
exemptProjects: true
|
||||||
|
|
||||||
|
# Set to true to ignore issues in a milestone (defaults to false)
|
||||||
|
exemptMilestones: true
|
||||||
|
|
||||||
|
# Set to true to ignore issues with an assignee (defaults to false)
|
||||||
|
exemptAssignees: true
|
||||||
|
|
||||||
|
# Label to use when marking as stale
|
||||||
|
staleLabel: wontfix
|
||||||
|
|
||||||
|
# Comment to post when marking as stale. Set to `false` to disable
|
||||||
|
markComment: >
|
||||||
|
This issue has been automatically marked as stale because it has not had
|
||||||
|
recent activity. It will be closed if no further activity occurs. Thank you
|
||||||
|
for your contributions.
|
||||||
|
|
||||||
|
# Comment to post when removing the stale label.
|
||||||
|
# unmarkComment: >
|
||||||
|
# Your comment here.
|
||||||
|
|
||||||
|
# Comment to post when closing a stale Issue or Pull Request.
|
||||||
|
# closeComment: >
|
||||||
|
# Your comment here.
|
||||||
|
|
||||||
|
# Limit the number of actions per hour, from 1-30. Default is 30
|
||||||
|
limitPerRun: 30
|
||||||
|
|
||||||
|
# Limit to only `issues` or `pulls`
|
||||||
|
# only: issues
|
||||||
|
|
||||||
|
# Optionally, specify configuration settings that are specific to just 'issues' or 'pulls':
|
||||||
|
# pulls:
|
||||||
|
# daysUntilStale: 30
|
||||||
|
# markComment: >
|
||||||
|
# This pull request has been automatically marked as stale because it has not had
|
||||||
|
# recent activity. It will be closed if no further activity occurs. Thank you
|
||||||
|
# for your contributions.
|
||||||
|
|
||||||
|
# issues:
|
||||||
|
# exemptLabels:
|
||||||
|
# - confirmed
|
||||||
40
.github/workflows/add-to-projects.yml
vendored
40
.github/workflows/add-to-projects.yml
vendored
@ -1,40 +0,0 @@
|
|||||||
name: Add-To-Projects
|
|
||||||
on:
|
|
||||||
issues:
|
|
||||||
types: [ opened, labeled ]
|
|
||||||
jobs:
|
|
||||||
community:
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
steps:
|
|
||||||
- name: Is Longhorn Member
|
|
||||||
uses: tspascoal/get-user-teams-membership@v1.0.4
|
|
||||||
id: is-longhorn-member
|
|
||||||
with:
|
|
||||||
username: ${{ github.event.issue.user.login }}
|
|
||||||
organization: longhorn
|
|
||||||
GITHUB_TOKEN: ${{ secrets.CUSTOM_GITHUB_TOKEN }}
|
|
||||||
- name: Add To Community Project
|
|
||||||
if: fromJSON(steps.is-longhorn-member.outputs.teams)[0] == null
|
|
||||||
uses: actions/add-to-project@v0.3.0
|
|
||||||
with:
|
|
||||||
project-url: https://github.com/orgs/longhorn/projects/5
|
|
||||||
github-token: ${{ secrets.CUSTOM_GITHUB_TOKEN }}
|
|
||||||
|
|
||||||
qa:
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
steps:
|
|
||||||
- name: Is Longhorn Member
|
|
||||||
uses: tspascoal/get-user-teams-membership@v1.0.4
|
|
||||||
id: is-longhorn-member
|
|
||||||
with:
|
|
||||||
username: ${{ github.event.issue.user.login }}
|
|
||||||
organization: longhorn
|
|
||||||
GITHUB_TOKEN: ${{ secrets.CUSTOM_GITHUB_TOKEN }}
|
|
||||||
- name: Add To QA & DevOps Project
|
|
||||||
if: fromJSON(steps.is-longhorn-member.outputs.teams)[0] != null
|
|
||||||
uses: actions/add-to-project@v0.3.0
|
|
||||||
with:
|
|
||||||
project-url: https://github.com/orgs/longhorn/projects/4
|
|
||||||
github-token: ${{ secrets.CUSTOM_GITHUB_TOKEN }}
|
|
||||||
labeled: kind/test, area/infra
|
|
||||||
label-operator: OR
|
|
||||||
50
.github/workflows/close-issue.yml
vendored
50
.github/workflows/close-issue.yml
vendored
@ -1,50 +0,0 @@
|
|||||||
name: Close-Issue
|
|
||||||
on:
|
|
||||||
issues:
|
|
||||||
types: [ unlabeled ]
|
|
||||||
jobs:
|
|
||||||
backport:
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
if: contains(github.event.label.name, 'backport/')
|
|
||||||
steps:
|
|
||||||
- name: Get Backport Version
|
|
||||||
uses: xom9ikk/split@v1
|
|
||||||
id: split
|
|
||||||
with:
|
|
||||||
string: ${{ github.event.label.name }}
|
|
||||||
separator: /
|
|
||||||
- name: Check if Backport Issue Exists
|
|
||||||
uses: actions-cool/issues-helper@v3
|
|
||||||
id: if-backport-issue-exists
|
|
||||||
with:
|
|
||||||
actions: 'find-issues'
|
|
||||||
token: ${{ github.token }}
|
|
||||||
title-includes: |
|
|
||||||
[BACKPORT][v${{ steps.split.outputs._1 }}]${{ github.event.issue.title }}
|
|
||||||
- name: Close Backport Issue
|
|
||||||
if: fromJSON(steps.if-backport-issue-exists.outputs.issues)[0] != null
|
|
||||||
uses: actions-cool/issues-helper@v3
|
|
||||||
with:
|
|
||||||
actions: 'close-issue'
|
|
||||||
token: ${{ github.token }}
|
|
||||||
issue-number: ${{ fromJSON(steps.if-backport-issue-exists.outputs.issues)[0].number }}
|
|
||||||
|
|
||||||
automation:
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
if: contains(github.event.label.name, 'require/automation-e2e')
|
|
||||||
steps:
|
|
||||||
- name: Check if Automation Issue Exists
|
|
||||||
uses: actions-cool/issues-helper@v3
|
|
||||||
id: if-automation-issue-exists
|
|
||||||
with:
|
|
||||||
actions: 'find-issues'
|
|
||||||
token: ${{ github.token }}
|
|
||||||
title-includes: |
|
|
||||||
[TEST]${{ github.event.issue.title }}
|
|
||||||
- name: Close Automation Test Issue
|
|
||||||
if: fromJSON(steps.if-automation-issue-exists.outputs.issues)[0] != null
|
|
||||||
uses: actions-cool/issues-helper@v3
|
|
||||||
with:
|
|
||||||
actions: 'close-issue'
|
|
||||||
token: ${{ github.token }}
|
|
||||||
issue-number: ${{ fromJSON(steps.if-automation-issue-exists.outputs.issues)[0].number }}
|
|
||||||
23
.github/workflows/codespell.yml
vendored
23
.github/workflows/codespell.yml
vendored
@ -1,23 +0,0 @@
|
|||||||
name: Codespell
|
|
||||||
|
|
||||||
on:
|
|
||||||
push:
|
|
||||||
pull_request:
|
|
||||||
branches:
|
|
||||||
- master
|
|
||||||
- "v*.*.*"
|
|
||||||
|
|
||||||
jobs:
|
|
||||||
codespell:
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
steps:
|
|
||||||
- name: Checkout
|
|
||||||
uses: actions/checkout@v3
|
|
||||||
with:
|
|
||||||
fetch-depth: 1
|
|
||||||
- name: Check code spell
|
|
||||||
uses: codespell-project/actions-codespell@v1
|
|
||||||
with:
|
|
||||||
check_filenames: true
|
|
||||||
ignore_words_file: .codespellignore
|
|
||||||
skip: "*/**.yaml,*/**.yml,*/**.tpl,./deploy,./dev,./scripts,./uninstall"
|
|
||||||
114
.github/workflows/create-issue.yml
vendored
114
.github/workflows/create-issue.yml
vendored
@ -1,114 +0,0 @@
|
|||||||
name: Create-Issue
|
|
||||||
on:
|
|
||||||
issues:
|
|
||||||
types: [ labeled ]
|
|
||||||
jobs:
|
|
||||||
backport:
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
if: contains(github.event.label.name, 'backport/')
|
|
||||||
steps:
|
|
||||||
- name: Is Longhorn Member
|
|
||||||
uses: tspascoal/get-user-teams-membership@v1.0.4
|
|
||||||
id: is-longhorn-member
|
|
||||||
with:
|
|
||||||
username: ${{ github.actor }}
|
|
||||||
organization: longhorn
|
|
||||||
GITHUB_TOKEN: ${{ secrets.CUSTOM_GITHUB_TOKEN }}
|
|
||||||
- name: Get Backport Version
|
|
||||||
if: fromJSON(steps.is-longhorn-member.outputs.teams)[0] != null
|
|
||||||
uses: xom9ikk/split@v1
|
|
||||||
id: split
|
|
||||||
with:
|
|
||||||
string: ${{ github.event.label.name }}
|
|
||||||
separator: /
|
|
||||||
- name: Check if Backport Issue Exists
|
|
||||||
if: fromJSON(steps.is-longhorn-member.outputs.teams)[0] != null
|
|
||||||
uses: actions-cool/issues-helper@v3
|
|
||||||
id: if-backport-issue-exists
|
|
||||||
with:
|
|
||||||
actions: 'find-issues'
|
|
||||||
token: ${{ github.token }}
|
|
||||||
issue-state: 'all'
|
|
||||||
title-includes: |
|
|
||||||
[BACKPORT][v${{ steps.split.outputs._1 }}]${{ github.event.issue.title }}
|
|
||||||
- name: Get Milestone Object
|
|
||||||
if: fromJSON(steps.is-longhorn-member.outputs.teams)[0] != null && fromJSON(steps.if-backport-issue-exists.outputs.issues)[0] == null
|
|
||||||
uses: longhorn/bot/milestone-action@master
|
|
||||||
id: milestone
|
|
||||||
with:
|
|
||||||
token: ${{ github.token }}
|
|
||||||
repository: ${{ github.repository }}
|
|
||||||
milestone_name: v${{ steps.split.outputs._1 }}
|
|
||||||
- name: Get Labels
|
|
||||||
if: fromJSON(steps.is-longhorn-member.outputs.teams)[0] != null && fromJSON(steps.if-backport-issue-exists.outputs.issues)[0] == null
|
|
||||||
id: labels
|
|
||||||
run: |
|
|
||||||
RAW_LABELS="${{ join(github.event.issue.labels.*.name, ' ') }}"
|
|
||||||
RAW_LABELS="${RAW_LABELS} kind/backport"
|
|
||||||
echo "RAW LABELS: $RAW_LABELS"
|
|
||||||
LABELS=$(echo "$RAW_LABELS" | sed -r 's/\s*backport\S+//g' | sed -r 's/\s*require\/auto-e2e-test//g' | xargs | sed 's/ /, /g')
|
|
||||||
echo "LABELS: $LABELS"
|
|
||||||
echo "labels=$LABELS" >> $GITHUB_OUTPUT
|
|
||||||
- name: Create Backport Issue
|
|
||||||
if: fromJSON(steps.is-longhorn-member.outputs.teams)[0] != null && fromJSON(steps.if-backport-issue-exists.outputs.issues)[0] == null
|
|
||||||
uses: dacbd/create-issue-action@v1
|
|
||||||
id: new-issue
|
|
||||||
with:
|
|
||||||
token: ${{ github.token }}
|
|
||||||
title: |
|
|
||||||
[BACKPORT][v${{ steps.split.outputs._1 }}]${{ github.event.issue.title }}
|
|
||||||
body: |
|
|
||||||
backport ${{ github.event.issue.html_url }}
|
|
||||||
labels: ${{ steps.labels.outputs.labels }}
|
|
||||||
milestone: ${{ fromJSON(steps.milestone.outputs.data).number }}
|
|
||||||
assignees: ${{ join(github.event.issue.assignees.*.login, ', ') }}
|
|
||||||
- name: Get Repo Id
|
|
||||||
if: fromJSON(steps.is-longhorn-member.outputs.teams)[0] != null && fromJSON(steps.if-backport-issue-exists.outputs.issues)[0] == null
|
|
||||||
uses: octokit/request-action@v2.x
|
|
||||||
id: repo
|
|
||||||
with:
|
|
||||||
route: GET /repos/${{ github.repository }}
|
|
||||||
env:
|
|
||||||
GITHUB_TOKEN: ${{ github.token }}
|
|
||||||
- name: Add Backport Issue To Release
|
|
||||||
if: fromJSON(steps.is-longhorn-member.outputs.teams)[0] != null && fromJSON(steps.if-backport-issue-exists.outputs.issues)[0] == null
|
|
||||||
uses: longhorn/bot/add-zenhub-release-action@master
|
|
||||||
with:
|
|
||||||
zenhub_token: ${{ secrets.ZENHUB_TOKEN }}
|
|
||||||
repo_id: ${{ fromJSON(steps.repo.outputs.data).id }}
|
|
||||||
issue_number: ${{ steps.new-issue.outputs.number }}
|
|
||||||
release_name: ${{ steps.split.outputs._1 }}
|
|
||||||
|
|
||||||
automation:
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
if: contains(github.event.label.name, 'require/auto-e2e-test')
|
|
||||||
steps:
|
|
||||||
- name: Is Longhorn Member
|
|
||||||
uses: tspascoal/get-user-teams-membership@v1.0.4
|
|
||||||
id: is-longhorn-member
|
|
||||||
with:
|
|
||||||
username: ${{ github.actor }}
|
|
||||||
organization: longhorn
|
|
||||||
GITHUB_TOKEN: ${{ secrets.CUSTOM_GITHUB_TOKEN }}
|
|
||||||
- name: Check if Automation Issue Exists
|
|
||||||
if: fromJSON(steps.is-longhorn-member.outputs.teams)[0] != null
|
|
||||||
uses: actions-cool/issues-helper@v3
|
|
||||||
id: if-automation-issue-exists
|
|
||||||
with:
|
|
||||||
actions: 'find-issues'
|
|
||||||
token: ${{ github.token }}
|
|
||||||
issue-state: 'all'
|
|
||||||
title-includes: |
|
|
||||||
[TEST]${{ github.event.issue.title }}
|
|
||||||
- name: Create Automation Test Issue
|
|
||||||
if: fromJSON(steps.is-longhorn-member.outputs.teams)[0] != null && fromJSON(steps.if-automation-issue-exists.outputs.issues)[0] == null
|
|
||||||
uses: dacbd/create-issue-action@v1
|
|
||||||
with:
|
|
||||||
token: ${{ github.token }}
|
|
||||||
title: |
|
|
||||||
[TEST]${{ github.event.issue.title }}
|
|
||||||
body: |
|
|
||||||
adding/updating auto e2e test cases for ${{ github.event.issue.html_url }} if they can be automated
|
|
||||||
|
|
||||||
cc @longhorn/qa
|
|
||||||
labels: kind/test
|
|
||||||
28
.github/workflows/stale.yaml
vendored
28
.github/workflows/stale.yaml
vendored
@ -1,28 +0,0 @@
|
|||||||
name: 'Close stale issues and PRs'
|
|
||||||
|
|
||||||
on:
|
|
||||||
workflow_call:
|
|
||||||
workflow_dispatch:
|
|
||||||
schedule:
|
|
||||||
- cron: '30 1 * * *'
|
|
||||||
|
|
||||||
jobs:
|
|
||||||
stale:
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
steps:
|
|
||||||
- uses: actions/stale@v4
|
|
||||||
with:
|
|
||||||
stale-issue-message: 'This issue is stale because it has been open 30 days with no activity. Remove stale label or comment or this will be closed in 5 days.'
|
|
||||||
stale-pr-message: 'This PR is stale because it has been open 45 days with no activity. Remove stale label or comment or this will be closed in 10 days.'
|
|
||||||
close-issue-message: 'This issue was closed because it has been stalled for 5 days with no activity.'
|
|
||||||
close-pr-message: 'This PR was closed because it has been stalled for 10 days with no activity.'
|
|
||||||
days-before-stale: 30
|
|
||||||
days-before-pr-stale: 45
|
|
||||||
days-before-close: 5
|
|
||||||
days-before-pr-close: 10
|
|
||||||
stale-issue-label: 'stale'
|
|
||||||
stale-pr-label: 'stale'
|
|
||||||
exempt-all-assignees: true
|
|
||||||
exempt-issue-labels: 'kind/bug,kind/doc,kind/enhancement,kind/poc,kind/refactoring,kind/test,kind/task,kind/backport,kind/regression,kind/evaluation'
|
|
||||||
exempt-draft-pr: true
|
|
||||||
exempt-all-milestones: true
|
|
||||||
3
.gitignore
vendored
3
.gitignore
vendored
@ -2,6 +2,3 @@
|
|||||||
.idea
|
.idea
|
||||||
*.iml
|
*.iml
|
||||||
*.ipr
|
*.ipr
|
||||||
|
|
||||||
# python venv for dev scripts
|
|
||||||
.venv
|
|
||||||
@ -1,283 +0,0 @@
|
|||||||
## Release Note
|
|
||||||
**v1.4.0 released!** 🎆
|
|
||||||
|
|
||||||
This release introduces many enhancements, improvements, and bug fixes as described below about stability, performance, data integrity, troubleshooting, and so on. Please try it and feedback. Thanks for all the contributions!
|
|
||||||
|
|
||||||
- [Kubernetes 1.25 Support](https://github.com/longhorn/longhorn/issues/4003) [[doc]](https://longhorn.io/docs/1.4.0/deploy/important-notes/#pod-security-policies-disabled--pod-security-admission-introduction)
|
|
||||||
In the previous versions, Longhorn relies on Pod Security Policy (PSP) to authorize Longhorn components for privileged operations. From Kubernetes 1.25, PSP has been removed and replaced with Pod Security Admission (PSA). Longhorn v1.4.0 supports opt-in PSP enablement, so it can support Kubernetes versions with or without PSP.
|
|
||||||
|
|
||||||
- [ARM64 GA](https://github.com/longhorn/longhorn/issues/4206)
|
|
||||||
ARM64 has been experimental from Longhorn v1.1.0. After receiving more user feedback and increasing testing coverage, ARM64 distribution has been stabilized with quality as per our regular regression testing, so it is qualified for general availability.
|
|
||||||
|
|
||||||
- [RWX GA](https://github.com/longhorn/longhorn/issues/2293) [[lep]](https://github.com/longhorn/longhorn/blob/master/enhancements/20220727-dedicated-recovery-backend-for-rwx-volume-nfs-server.md)[[doc]](https://longhorn.io/docs/1.4.0/advanced-resources/rwx-workloads/)
|
|
||||||
RWX has been experimental from Longhorn v1.1.0, but it lacks availability support when the Longhorn Share Manager component behind becomes unavailable. Longhorn v1.4.0 supports NFS recovery backend based on Kubernetes built-in resource, ConfigMap, for recovering NFS client connection during the fail-over period. Also, the NFS client hard mode introduction will further avoid previous potential data loss. For the detail, please check the issue and enhancement proposal.
|
|
||||||
|
|
||||||
- [Volume Snapshot Checksum](https://github.com/longhorn/longhorn/issues/4210) [[lep]](https://github.com/longhorn/longhorn/blob/master/enhancements/20220922-snapshot-checksum-and-bit-rot-detection.md)[[doc]](https://longhorn.io/docs/1.4.0/references/settings/#snapshot-data-integrity)
|
|
||||||
Data integrity is a continuous effort for Longhorn. In this version, Snapshot Checksum has been introduced w/ some settings to allow users to enable or disable checksum calculation with different modes.
|
|
||||||
|
|
||||||
- [Volume Bit-rot Protection](https://github.com/longhorn/longhorn/issues/3198) [[lep]](https://github.com/longhorn/longhorn/blob/master/enhancements/20220922-snapshot-checksum-and-bit-rot-detection.md)[[doc]](https://longhorn.io/docs/1.4.0/references/settings/#snapshot-data-integrity)
|
|
||||||
When enabling the Volume Snapshot Checksum feature, Longhorn will periodically calculate and check the checksums of volume snapshots, find corrupted snapshots, then fix them.
|
|
||||||
|
|
||||||
- [Volume Replica Rebuilding Speedup](https://github.com/longhorn/longhorn/issues/4783)
|
|
||||||
When enabling the Volume Snapshot Checksum feature, Longhorn will use the calculated snapshot checksum to avoid needless snapshot replication between nodes for improving replica rebuilding speed and resource consumption.
|
|
||||||
|
|
||||||
- [Volume Trim](https://github.com/longhorn/longhorn/issues/836) [[lep]](https://github.com/longhorn/longhorn/blob/master/enhancements/20221103-filesystem-trim.md)[[doc]](https://longhorn.io/docs/1.4.0/volumes-and-nodes/trim-filesystem/#trim-the-filesystem-in-a-longhorn-volume)
|
|
||||||
Longhorn engine supports UNMAP SCSI command to reclaim space from the block volume.
|
|
||||||
|
|
||||||
- [Online Volume Expansion](https://github.com/longhorn/longhorn/issues/1674) [[doc]](https://longhorn.io/docs/1.4.0/volumes-and-nodes/expansion)
|
|
||||||
Longhorn engine supports optional parameters to pass size expansion requests when updating the volume frontend to support online volume expansion and resize the filesystem via CSI node driver.
|
|
||||||
|
|
||||||
- [Local Volume via Data Locality Strict Mode](https://github.com/longhorn/longhorn/issues/3957) [[lep]](https://github.com/longhorn/longhorn/blob/master/enhancements/20200819-keep-a-local-replica-to-engine.md)[[doc]](https://longhorn.io/docs/1.4.0/references/settings/#default-data-locality)
|
|
||||||
Local volume is based on a new Data Locality setting, Strict Local. It will allow users to create one replica volume staying in a consistent location, and the data transfer between the volume frontend and engine will be through a local socket instead of the TCP stack to improve performance and reduce resource consumption.
|
|
||||||
|
|
||||||
- [Volume Recurring Job Backup Restore](https://github.com/longhorn/longhorn/issues/2227) [[lep]](https://github.com/longhorn/longhorn/blob/master/enhancements/20201002-allow-recurring-backup-detached-volumes.md)[[doc]](https://longhorn.io/docs/1.4.0/snapshots-and-backups/backup-and-restore/restore-recurring-jobs-from-a-backup/)
|
|
||||||
Recurring jobs binding to a volume can be backed up to the remote backup target together with the volume backup metadata. They can be restored back as well for a better operation experience.
|
|
||||||
|
|
||||||
- [Volume IO Metrics](https://github.com/longhorn/longhorn/issues/2406) [[doc]](https://longhorn.io/docs/1.4.0/monitoring/metrics/#volume)
|
|
||||||
Longhorn enriches Volume metrics by providing real-time IO stats including IOPS, latency, and throughput of R/W IO. Users can set up a monotoning solution like Prometheus to monitor volume performance.
|
|
||||||
|
|
||||||
- [Longhorn System Backup & Restore](https://github.com/longhorn/longhorn/issues/1455) [[lep]](https://github.com/longhorn/longhorn/blob/master/enhancements/20220913-longhorn-system-backup-restore.md)[[doc]](https://longhorn.io/docs/1.4.0/advanced-resources/system-backup-restore/)
|
|
||||||
Users can back up the longhorn system to the remote backup target. Afterward, it's able to restore back to an existing cluster in place or a new cluster for specific operational purposes.
|
|
||||||
|
|
||||||
- [Support Bundle Enhancement](https://github.com/longhorn/longhorn/issues/2759) [[lep]](https://github.com/longhorn/longhorn/blob/master/enhancements/20221109-support-bundle-enhancement.md)
|
|
||||||
Longhorn introduces a new support bundle integration based on a general [support bundle kit](https://github.com/rancher/support-bundle-kit) solution. This can help us collect more complete troubleshooting info and simulate the cluster environment.
|
|
||||||
|
|
||||||
- [Tunable Timeout between Engine and Replica](https://github.com/longhorn/longhorn/issues/4491) [[doc]](https://longhorn.io/docs/1.4.0/references/settings/#engine-to-replica-timeout)
|
|
||||||
In the current Longhorn versions, the default timeout between the Longhorn engine and replica is fixed without any exposed user settings. This will potentially bring some challenges for users having a low-spec infra environment. By exporting the setting configurable, it will allow users adaptively tune the stability of volume operations.
|
|
||||||
|
|
||||||
## Installation
|
|
||||||
|
|
||||||
> **Please ensure your Kubernetes cluster is at least v1.21 before installing Longhorn v1.4.0.**
|
|
||||||
|
|
||||||
Longhorn supports 3 installation ways including Rancher App Marketplace, Kubectl, and Helm. Follow the installation instructions [here](https://longhorn.io/docs/1.4.0/deploy/install/).
|
|
||||||
|
|
||||||
## Upgrade
|
|
||||||
|
|
||||||
> **Please ensure your Kubernetes cluster is at least v1.21 before upgrading to Longhorn v1.4.0 from v1.3.x. Only support upgrading from 1.3.x.**
|
|
||||||
|
|
||||||
Follow the upgrade instructions [here](https://longhorn.io/docs/1.4.0/deploy/upgrade/).
|
|
||||||
|
|
||||||
## Deprecation & Incompatibilities
|
|
||||||
|
|
||||||
- Pod Security Policy is an opt-in setting. If installing Longhorn with PSP support, need to enable it first.
|
|
||||||
- The built-in CSI Snapshotter sidecar is upgraded to v5.0.1. The v1beta1 version of Volume Snapshot custom resource is deprecated but still supported. However, it will be removed after upgrading CSI Snapshotter to 6.1 or later versions in the future, so please start using v1 version instead before the deprecated version is removed.
|
|
||||||
|
|
||||||
## Known Issues after Release
|
|
||||||
|
|
||||||
Please follow up on [here](https://github.com/longhorn/longhorn/wiki/Outstanding-Known-Issues-of-Releases) about any outstanding issues found after this release.
|
|
||||||
|
|
||||||
## Highlights
|
|
||||||
|
|
||||||
- [FEATURE] Reclaim/Shrink space of volume ([836](https://github.com/longhorn/longhorn/issues/836)) - @yangchiu @derekbit @smallteeths @shuo-wu
|
|
||||||
- [FEATURE] Backup/Restore Longhorn System ([1455](https://github.com/longhorn/longhorn/issues/1455)) - @c3y1huang @khushboo-rancher
|
|
||||||
- [FEATURE] Online volume expansion ([1674](https://github.com/longhorn/longhorn/issues/1674)) - @shuo-wu @chriscchien
|
|
||||||
- [FEATURE] Record recurring schedule in the backups and allow user choose to use it for the restored volume ([2227](https://github.com/longhorn/longhorn/issues/2227)) - @yangchiu @mantissahz
|
|
||||||
- [FEATURE] NFS support (RWX) GA ([2293](https://github.com/longhorn/longhorn/issues/2293)) - @derekbit @chriscchien
|
|
||||||
- [FEATURE] Support metrics for Volume IOPS, throughput and latency real time ([2406](https://github.com/longhorn/longhorn/issues/2406)) - @derekbit @roger-ryao
|
|
||||||
- [FEATURE] Support bundle enhancement ([2759](https://github.com/longhorn/longhorn/issues/2759)) - @c3y1huang @chriscchien
|
|
||||||
- [FEATURE] Automatic identifying of corrupted replica (bit rot detection) ([3198](https://github.com/longhorn/longhorn/issues/3198)) - @yangchiu @derekbit
|
|
||||||
- [FEATURE] Local volume for distributed data workloads ([3957](https://github.com/longhorn/longhorn/issues/3957)) - @derekbit @chriscchien
|
|
||||||
- [IMPROVEMENT] Support K8s 1.25 by updating removed deprecated resource versions like PodSecurityPolicy ([4003](https://github.com/longhorn/longhorn/issues/4003)) - @PhanLe1010 @chriscchien
|
|
||||||
- [IMPROVEMENT] Faster resync time for fresh replica rebuilding ([4092](https://github.com/longhorn/longhorn/issues/4092)) - @yangchiu @derekbit
|
|
||||||
- [FEATURE] Introduce checksum for snapshots ([4210](https://github.com/longhorn/longhorn/issues/4210)) - @derekbit @roger-ryao
|
|
||||||
- [FEATURE] Update K8s version support and component/pkg/build dependencies ([4239](https://github.com/longhorn/longhorn/issues/4239)) - @yangchiu @PhanLe1010
|
|
||||||
- [BUG] data corruption due to COW and block size not being aligned during rebuilding replicas ([4354](https://github.com/longhorn/longhorn/issues/4354)) - @PhanLe1010 @chriscchien
|
|
||||||
- [IMPROVEMENT] Adjust the iSCSI timeout and the engine-to-replica timeout settings ([4491](https://github.com/longhorn/longhorn/issues/4491)) - @yangchiu @derekbit
|
|
||||||
- [IMPROVEMENT] Using specific block size in Longhorn volume's filesystem ([4594](https://github.com/longhorn/longhorn/issues/4594)) - @derekbit @roger-ryao
|
|
||||||
- [IMPROVEMENT] Speed up replica rebuilding by the metadata such as ctime of snapshot disk files ([4783](https://github.com/longhorn/longhorn/issues/4783)) - @yangchiu @derekbit
|
|
||||||
|
|
||||||
## Enhancements
|
|
||||||
|
|
||||||
- [FEATURE] Configure successfulJobsHistoryLimit of CronJobs ([1711](https://github.com/longhorn/longhorn/issues/1711)) - @weizhe0422 @chriscchien
|
|
||||||
- [FEATURE] Allow customization of the cipher used by cryptsetup in volume encryption ([3353](https://github.com/longhorn/longhorn/issues/3353)) - @mantissahz @chriscchien
|
|
||||||
- [FEATURE] New setting to limit the concurrent volume restoring from backup ([4558](https://github.com/longhorn/longhorn/issues/4558)) - @c3y1huang @chriscchien
|
|
||||||
- [FEATURE] Make FS format options configurable in storage class ([4642](https://github.com/longhorn/longhorn/issues/4642)) - @weizhe0422 @chriscchien
|
|
||||||
|
|
||||||
## Improvement
|
|
||||||
|
|
||||||
- [IMPROVEMENT] Change the script into a docker run command mentioned in 'recovery from longhorn backup without system installed' doc ([1521](https://github.com/longhorn/longhorn/issues/1521)) - @weizhe0422 @chriscchien
|
|
||||||
- [IMPROVEMENT] Improve 'recovery from longhorn backup without system installed' doc. ([1522](https://github.com/longhorn/longhorn/issues/1522)) - @weizhe0422 @roger-ryao
|
|
||||||
- [IMPROVEMENT] Dump NFS ganesha logs to pod stdout ([2380](https://github.com/longhorn/longhorn/issues/2380)) - @weizhe0422 @roger-ryao
|
|
||||||
- [IMPROVEMENT] Support failed/obsolete orphaned backup cleanup ([3898](https://github.com/longhorn/longhorn/issues/3898)) - @mantissahz @chriscchien
|
|
||||||
- [IMPROVEMENT] liveness and readiness probes with longhorn csi plugin daemonset ([3907](https://github.com/longhorn/longhorn/issues/3907)) - @c3y1huang @roger-ryao
|
|
||||||
- [IMPROVEMENT] Longhorn doesn't reuse failed replica on a disk with full allocated space ([3921](https://github.com/longhorn/longhorn/issues/3921)) - @PhanLe1010 @chriscchien
|
|
||||||
- [IMPROVEMENT] Reduce syscalls while reading and writing requests in longhorn-engine (engine <-> replica) ([4122](https://github.com/longhorn/longhorn/issues/4122)) - @yangchiu @derekbit
|
|
||||||
- [IMPROVEMENT] Reduce read and write calls in liblonghorn (tgt <-> engine) ([4133](https://github.com/longhorn/longhorn/issues/4133)) - @derekbit
|
|
||||||
- [IMPROVEMENT] Replace the GCC allocator in liblonghorn with a more efficient memory allocator ([4136](https://github.com/longhorn/longhorn/issues/4136)) - @yangchiu @derekbit
|
|
||||||
- [DOC] Update Helm readme and document ([4175](https://github.com/longhorn/longhorn/issues/4175)) - @derekbit
|
|
||||||
- [IMPROVEMENT] Purging a volume before rebuilding starts ([4183](https://github.com/longhorn/longhorn/issues/4183)) - @yangchiu @shuo-wu
|
|
||||||
- [IMPROVEMENT] Schedule volumes based on available disk space ([4185](https://github.com/longhorn/longhorn/issues/4185)) - @yangchiu @c3y1huang
|
|
||||||
- [IMPROVEMENT] Recognize default toleration and node selector to allow Longhorn run on the RKE mixed cluster ([4246](https://github.com/longhorn/longhorn/issues/4246)) - @c3y1huang @chriscchien
|
|
||||||
- [IMPROVEMENT] Support bundle doesn't collect the snapshot yamls ([4285](https://github.com/longhorn/longhorn/issues/4285)) - @yangchiu @PhanLe1010
|
|
||||||
- [IMPROVEMENT] Avoid accidentally deleting engine images that are still in use ([4332](https://github.com/longhorn/longhorn/issues/4332)) - @derekbit @chriscchien
|
|
||||||
- [IMPROVEMENT] Show non-JSON error from backup store ([4336](https://github.com/longhorn/longhorn/issues/4336)) - @c3y1huang
|
|
||||||
- [IMPROVEMENT] Update nfs-ganesha to v4.0 ([4351](https://github.com/longhorn/longhorn/issues/4351)) - @derekbit
|
|
||||||
- [IMPROVEMENT] show error when failed to init frontend ([4362](https://github.com/longhorn/longhorn/issues/4362)) - @c3y1huang
|
|
||||||
- [IMPROVEMENT] Too many debug-level log messages in engine instance-manager ([4427](https://github.com/longhorn/longhorn/issues/4427)) - @derekbit @chriscchien
|
|
||||||
- [IMPROVEMENT] Add prep work for fixing the corrupted filesystem using fsck in KB ([4440](https://github.com/longhorn/longhorn/issues/4440)) - @derekbit
|
|
||||||
- [IMPROVEMENT] Prevent users from accidentally uninstalling Longhorn ([4509](https://github.com/longhorn/longhorn/issues/4509)) - @yangchiu @PhanLe1010
|
|
||||||
- [IMPROVEMENT] add possibility to use nodeSelector on the storageClass ([4574](https://github.com/longhorn/longhorn/issues/4574)) - @weizhe0422 @roger-ryao
|
|
||||||
- [IMPROVEMENT] Check if node schedulable condition is set before trying to read it ([4581](https://github.com/longhorn/longhorn/issues/4581)) - @weizhe0422 @roger-ryao
|
|
||||||
- [IMPROVEMENT] Review/consolidate the sectorSize in replica server, replica volume, and engine ([4599](https://github.com/longhorn/longhorn/issues/4599)) - @yangchiu @derekbit
|
|
||||||
- [IMPROVEMENT] Reorganize longhorn-manager/k8s/patches and auto-generate preserveUnknownFields field ([4600](https://github.com/longhorn/longhorn/issues/4600)) - @yangchiu @derekbit
|
|
||||||
- [IMPROVEMENT] share-manager pod bypasses the kubernetes scheduler ([4789](https://github.com/longhorn/longhorn/issues/4789)) - @joshimoo @chriscchien
|
|
||||||
- [IMPROVEMENT] Unify the format of returned error messages in longhorn-engine ([4828](https://github.com/longhorn/longhorn/issues/4828)) - @derekbit
|
|
||||||
- [IMPROVEMENT] Longhorn system backup/restore UI ([4855](https://github.com/longhorn/longhorn/issues/4855)) - @smallteeths
|
|
||||||
- [IMPROVEMENT] Replace the modTime (mtime) with ctime in snapshot hash ([4934](https://github.com/longhorn/longhorn/issues/4934)) - @derekbit @chriscchien
|
|
||||||
- [BUG] volume is stuck in attaching/detaching loop with error `Failed to init frontend: device...` ([4959](https://github.com/longhorn/longhorn/issues/4959)) - @derekbit @PhanLe1010 @chriscchien
|
|
||||||
- [IMPROVEMENT] Affinity in the longhorn-ui deployment within the helm chart ([4987](https://github.com/longhorn/longhorn/issues/4987)) - @mantissahz @chriscchien
|
|
||||||
- [IMPROVEMENT] Allow users to change volume.spec.snapshotDataIntegrity on UI ([4994](https://github.com/longhorn/longhorn/issues/4994)) - @yangchiu @smallteeths
|
|
||||||
- [IMPROVEMENT] Backup and restore recurring jobs on UI ([5009](https://github.com/longhorn/longhorn/issues/5009)) - @smallteeths @chriscchien
|
|
||||||
- [IMPROVEMENT] Disable `Automatically Delete Workload Pod when The Volume Is Detached Unexpectedly` for RWX volumes ([5017](https://github.com/longhorn/longhorn/issues/5017)) - @derekbit @chriscchien
|
|
||||||
- [IMPROVEMENT] Enable fast replica rebuilding by default ([5023](https://github.com/longhorn/longhorn/issues/5023)) - @derekbit @roger-ryao
|
|
||||||
- [IMPROVEMENT] Upgrade tcmalloc in longhorn-engine ([5050](https://github.com/longhorn/longhorn/issues/5050)) - @derekbit
|
|
||||||
- [IMPROVEMENT] UI show error when backup target is empty for system backup ([5056](https://github.com/longhorn/longhorn/issues/5056)) - @smallteeths @khushboo-rancher
|
|
||||||
- [IMPROVEMENT] System restore job name should be Longhorn prefixed ([5057](https://github.com/longhorn/longhorn/issues/5057)) - @c3y1huang @khushboo-rancher
|
|
||||||
- [BUG] Error in logs while restoring the system backup ([5061](https://github.com/longhorn/longhorn/issues/5061)) - @c3y1huang @chriscchien
|
|
||||||
- [IMPROVEMENT] Add warning message to when deleting the restoring backups ([5065](https://github.com/longhorn/longhorn/issues/5065)) - @smallteeths @khushboo-rancher @roger-ryao
|
|
||||||
- [IMPROVEMENT] Inconsistent name convention across volume backup restore and system backup restore ([5066](https://github.com/longhorn/longhorn/issues/5066)) - @smallteeths @roger-ryao
|
|
||||||
- [IMPROVEMENT] System restore should proceed to restore other volumes if restoring one volume keeps failing for a certain time. ([5086](https://github.com/longhorn/longhorn/issues/5086)) - @c3y1huang @khushboo-rancher @roger-ryao
|
|
||||||
- [IMPROVEMENT] Support customized number of replicas of webhook and recovery-backend ([5087](https://github.com/longhorn/longhorn/issues/5087)) - @derekbit @chriscchien
|
|
||||||
- [IMPROVEMENT] Simplify the page by placing some configuration items in the advanced configuration when creating the volume ([5090](https://github.com/longhorn/longhorn/issues/5090)) - @yangchiu @smallteeths
|
|
||||||
- [IMPROVEMENT] Support replica sync client timeout setting to stabilize replica rebuilding ([5110](https://github.com/longhorn/longhorn/issues/5110)) - @derekbit @chriscchien
|
|
||||||
- [IMPROVEMENT] Set a newly created volume's data integrity from UI to `ignored` rather than `Fast-Check`. ([5126](https://github.com/longhorn/longhorn/issues/5126)) - @yangchiu @smallteeths
|
|
||||||
|
|
||||||
## Performance
|
|
||||||
|
|
||||||
- [BUG] Turn a node down and up, workload takes longer time to come back online in Longhorn v1.2.0 ([2947](https://github.com/longhorn/longhorn/issues/2947)) - @yangchiu @PhanLe1010
|
|
||||||
- [TASK] RWX volume performance measurement and investigation ([3665](https://github.com/longhorn/longhorn/issues/3665)) - @derekbit
|
|
||||||
- [TASK] Verify spinning disk/HDD via the current e2e regression ([4182](https://github.com/longhorn/longhorn/issues/4182)) - @yangchiu
|
|
||||||
- [BUG] test_csi_snapshot_snap_create_volume_from_snapshot failed when using HDD as Longhorn disks ([4227](https://github.com/longhorn/longhorn/issues/4227)) - @yangchiu @PhanLe1010
|
|
||||||
- [TASK] Disable tcmalloc in data path because newer tcmalloc version leads to performance drop ([5096](https://github.com/longhorn/longhorn/issues/5096)) - @derekbit @chriscchien
|
|
||||||
|
|
||||||
## Stability
|
|
||||||
|
|
||||||
- [BUG] Longhorn won't fail all replicas if there is no valid backend during the engine starting stage ([1330](https://github.com/longhorn/longhorn/issues/1330)) - @derekbit @roger-ryao
|
|
||||||
- [BUG] Every other backup fails and crashes the volume (Segmentation Fault) ([1768](https://github.com/longhorn/longhorn/issues/1768)) - @olljanat @mantissahz
|
|
||||||
- [BUG] Backend sizes do not match 5368709120 != 10737418240 in the engine initiation phase ([3601](https://github.com/longhorn/longhorn/issues/3601)) - @derekbit @chriscchien
|
|
||||||
- [BUG] Somehow the Rebuilding field inside volume.meta is set to true causing the volume to stuck in attaching/detaching loop ([4212](https://github.com/longhorn/longhorn/issues/4212)) - @yangchiu @derekbit
|
|
||||||
- [BUG] Engine binary cannot be recovered after being removed accidentally ([4380](https://github.com/longhorn/longhorn/issues/4380)) - @yangchiu @c3y1huang
|
|
||||||
- [TASK] Disable tcmalloc in longhorn-engine and longhorn-instance-manager ([5068](https://github.com/longhorn/longhorn/issues/5068)) - @derekbit
|
|
||||||
|
|
||||||
## Bugs
|
|
||||||
|
|
||||||
- [BUG] Removing old instance records after the new IM pod is launched will take 1 minute ([1363](https://github.com/longhorn/longhorn/issues/1363)) - @mantissahz
|
|
||||||
- [BUG] Restoring volume stuck forever if the backup is already deleted. ([1867](https://github.com/longhorn/longhorn/issues/1867)) - @mantissahz @chriscchien
|
|
||||||
- [BUG] Duplicated default instance manager leads to engine/replica cannot be started ([3000](https://github.com/longhorn/longhorn/issues/3000)) - @PhanLe1010 @roger-ryao
|
|
||||||
- [BUG] Restore from backup sometimes failed if having high frequent recurring backup job w/ retention ([3055](https://github.com/longhorn/longhorn/issues/3055)) - @mantissahz @roger-ryao
|
|
||||||
- [BUG] Newly created backup stays in `InProgress` when the volume deleted before backup finished ([3122](https://github.com/longhorn/longhorn/issues/3122)) - @mantissahz @chriscchien
|
|
||||||
- [Bug] Degraded volume generate failed replica make volume unschedulable ([3220](https://github.com/longhorn/longhorn/issues/3220)) - @derekbit @chriscchien
|
|
||||||
- [BUG] The default access mode of a restored RWX volume is RWO ([3444](https://github.com/longhorn/longhorn/issues/3444)) - @weizhe0422 @roger-ryao
|
|
||||||
- [BUG] Replica rebuilding failure with error "Replica must be closed, Can not add in state: open" ([3828](https://github.com/longhorn/longhorn/issues/3828)) - @mantissahz @roger-ryao
|
|
||||||
- [BUG] Max length of volume name not consist between frontend and backend ([3917](https://github.com/longhorn/longhorn/issues/3917)) - @weizhe0422 @roger-ryao
|
|
||||||
- [BUG] Can't delete volumesnapshot if backup removed first ([4107](https://github.com/longhorn/longhorn/issues/4107)) - @weizhe0422 @chriscchien
|
|
||||||
- [BUG] A IM-proxy connection not closed in full regression 1.3 ([4113](https://github.com/longhorn/longhorn/issues/4113)) - @c3y1huang @chriscchien
|
|
||||||
- [BUG] Scale replica warning ([4120](https://github.com/longhorn/longhorn/issues/4120)) - @c3y1huang @chriscchien
|
|
||||||
- [BUG] Wrong nodeOrDiskEvicted collected in node monitor ([4143](https://github.com/longhorn/longhorn/issues/4143)) - @yangchiu @derekbit
|
|
||||||
- [BUG] Misleading log "BUG: replica is running but storage IP is empty" ([4153](https://github.com/longhorn/longhorn/issues/4153)) - @shuo-wu @chriscchien
|
|
||||||
- [BUG] longhorn-manager cannot start while upgrading if the configmap contains volume sensitive settings ([4160](https://github.com/longhorn/longhorn/issues/4160)) - @derekbit @chriscchien
|
|
||||||
- [BUG] Replica stuck in buggy state with status.currentState is error and the spec.desireState is running ([4197](https://github.com/longhorn/longhorn/issues/4197)) - @yangchiu @PhanLe1010
|
|
||||||
- [BUG] After updating longhorn to version 1.3.0, only 1 node had problems and I can't even delete it ([4213](https://github.com/longhorn/longhorn/issues/4213)) - @derekbit @c3y1huang @chriscchien
|
|
||||||
- [BUG] Unable to use a TTY error when running environment_check.sh ([4216](https://github.com/longhorn/longhorn/issues/4216)) - @flkdnt @chriscchien
|
|
||||||
- [BUG] The last healthy replica may be evicted or removed ([4238](https://github.com/longhorn/longhorn/issues/4238)) - @yangchiu @shuo-wu
|
|
||||||
- [BUG] Volume detaching and attaching repeatedly while creating multiple snapshots with a same id ([4250](https://github.com/longhorn/longhorn/issues/4250)) - @yangchiu @derekbit
|
|
||||||
- [BUG] Backing image is not deleted and recreated correctly ([4256](https://github.com/longhorn/longhorn/issues/4256)) - @shuo-wu @chriscchien
|
|
||||||
- [BUG] longhorn-ui fails to start on RKE2 with cis-1.6 profile for Longhorn v1.3.0 with helm install ([4266](https://github.com/longhorn/longhorn/issues/4266)) - @yangchiu @mantissahz
|
|
||||||
- [BUG] Longhorn volume stuck in deleting state ([4278](https://github.com/longhorn/longhorn/issues/4278)) - @yangchiu @PhanLe1010
|
|
||||||
- [BUG] the IP address is duplicate when using storage network and the second network is contronllerd by ovs-cni. ([4281](https://github.com/longhorn/longhorn/issues/4281)) - @mantissahz
|
|
||||||
- [BUG] build longhorn-ui image error ([4283](https://github.com/longhorn/longhorn/issues/4283)) - @smallteeths
|
|
||||||
- [BUG] Wrong conditions in the Chart default-setting manifest for Rancher deployed Windows Cluster feature ([4289](https://github.com/longhorn/longhorn/issues/4289)) - @derekbit @chriscchien
|
|
||||||
- [BUG] Volume operations/rebuilding error during eviction ([4294](https://github.com/longhorn/longhorn/issues/4294)) - @yangchiu @shuo-wu
|
|
||||||
- [BUG] longhorn-manager deletes same pod multi times when rebooting ([4302](https://github.com/longhorn/longhorn/issues/4302)) - @mantissahz @w13915984028
|
|
||||||
- [BUG] test_setting_backing_image_auto_cleanup failed because the backing image file isn't deleted on the corresponding node as expected ([4308](https://github.com/longhorn/longhorn/issues/4308)) - @shuo-wu @chriscchien
|
|
||||||
- [BUG] After automatically force delete terminating pods of deployment on down node, data lost and I/O error ([4384](https://github.com/longhorn/longhorn/issues/4384)) - @yangchiu @derekbit @PhanLe1010
|
|
||||||
- [BUG] Volume can not attach to node when engine image DaemonSet pods are not fully deployed ([4386](https://github.com/longhorn/longhorn/issues/4386)) - @PhanLe1010 @chriscchien
|
|
||||||
- [BUG] Error/warning during uninstallation of Longhorn v1.3.1 via manifest ([4405](https://github.com/longhorn/longhorn/issues/4405)) - @PhanLe1010 @roger-ryao
|
|
||||||
- [BUG] can't upgrade engine if a volume was created in Longhorn v1.0 and the volume.spec.dataLocality is `""` ([4412](https://github.com/longhorn/longhorn/issues/4412)) - @derekbit @chriscchien
|
|
||||||
- [BUG] Confusing description the label for replica delition ([4430](https://github.com/longhorn/longhorn/issues/4430)) - @yangchiu @smallteeths
|
|
||||||
- [BUG] Update the Longhorn document in Using the Environment Check Script ([4450](https://github.com/longhorn/longhorn/issues/4450)) - @weizhe0422 @roger-ryao
|
|
||||||
- [BUG] Unable to search 1.3.1 doc by algolia ([4457](https://github.com/longhorn/longhorn/issues/4457)) - @mantissahz @roger-ryao
|
|
||||||
- [BUG] Misleading message "The volume is in expansion progress from size 20Gi to 10Gi" if the expansion is invalid ([4475](https://github.com/longhorn/longhorn/issues/4475)) - @yangchiu @smallteeths
|
|
||||||
- [BUG] Flaky case test_autosalvage_with_data_locality_enabled ([4489](https://github.com/longhorn/longhorn/issues/4489)) - @weizhe0422
|
|
||||||
- [BUG] Continuously rebuild when auto-balance==least-effort and existing node becomes unschedulable ([4502](https://github.com/longhorn/longhorn/issues/4502)) - @yangchiu @c3y1huang
|
|
||||||
- [BUG] Inconsistent system snapshots between replicas after rebuilding ([4513](https://github.com/longhorn/longhorn/issues/4513)) - @derekbit
|
|
||||||
- [BUG] Prometheus metric for backup state (longhorn_backup_state) returns wrong values ([4521](https://github.com/longhorn/longhorn/issues/4521)) - @mantissahz @roger-ryao
|
|
||||||
- [BUG] Longhorn accidentally schedule all replicas onto a worker node even though the setting Replica Node Level Soft Anti-Affinity is currently disabled ([4546](https://github.com/longhorn/longhorn/issues/4546)) - @yangchiu @mantissahz
|
|
||||||
- [BUG] LH continuously reports `invalid customized default setting taint-toleration` ([4554](https://github.com/longhorn/longhorn/issues/4554)) - @weizhe0422 @roger-ryao
|
|
||||||
- [BUG] the values.yaml in the longhorn helm chart contains values not used. ([4601](https://github.com/longhorn/longhorn/issues/4601)) - @weizhe0422 @roger-ryao
|
|
||||||
- [BUG] longhorn-engine integration test test_restore_to_file_with_backing_file failed after upgrade to sles 15.4 ([4632](https://github.com/longhorn/longhorn/issues/4632)) - @mantissahz
|
|
||||||
- [BUG] Can not pull a backup created by another Longhorn system from the remote backup target ([4637](https://github.com/longhorn/longhorn/issues/4637)) - @yangchiu @mantissahz @roger-ryao
|
|
||||||
- [BUG] Fix the share-manager deletion failure if the confimap is not existing ([4648](https://github.com/longhorn/longhorn/issues/4648)) - @derekbit @roger-ryao
|
|
||||||
- [BUG] Updating volume-scheduling-error failure for RWX volumes and expanding volumes ([4654](https://github.com/longhorn/longhorn/issues/4654)) - @derekbit @chriscchien
|
|
||||||
- [BUG] charts/longhorn/questions.yaml include oudated csi-image tags ([4669](https://github.com/longhorn/longhorn/issues/4669)) - @PhanLe1010 @roger-ryao
|
|
||||||
- [BUG] rebuilding the replica failed after upgrading from 1.2.4 to 1.3.2-rc2 ([4705](https://github.com/longhorn/longhorn/issues/4705)) - @derekbit @chriscchien
|
|
||||||
- [BUG] Cannot re-run helm uninstallation if the first one failed and cannot fetch logs of failed uninstallation pod ([4711](https://github.com/longhorn/longhorn/issues/4711)) - @yangchiu @PhanLe1010 @roger-ryao
|
|
||||||
- [BUG] The old instance-manager-r Pods are not deleted after upgrade ([4726](https://github.com/longhorn/longhorn/issues/4726)) - @mantissahz @chriscchien
|
|
||||||
- [BUG] Replica Auto Balance repeatedly delete the local replica and trigger rebuilding ([4761](https://github.com/longhorn/longhorn/issues/4761)) - @c3y1huang @roger-ryao
|
|
||||||
- [BUG] Volume metafile getting deleted or empty results in a detach-attach loop ([4846](https://github.com/longhorn/longhorn/issues/4846)) - @mantissahz @chriscchien
|
|
||||||
- [BUG] Backing image is stuck at `in-progress` status if the provided checksum is incorrect ([4852](https://github.com/longhorn/longhorn/issues/4852)) - @FrankYang0529 @chriscchien
|
|
||||||
- [BUG] Duplicate channel close error in the backing image manage related components ([4865](https://github.com/longhorn/longhorn/issues/4865)) - @weizhe0422 @roger-ryao
|
|
||||||
- [BUG] The node ID of backing image data source somehow get changed then lead to file handling failed ([4887](https://github.com/longhorn/longhorn/issues/4887)) - @shuo-wu @chriscchien
|
|
||||||
- [BUG] Cannot upload a backing image larger than 10G ([4902](https://github.com/longhorn/longhorn/issues/4902)) - @smallteeths @shuo-wu @chriscchien
|
|
||||||
- [BUG] Failed to build longhorn-instance-manager master branch ([4946](https://github.com/longhorn/longhorn/issues/4946)) - @derekbit
|
|
||||||
- [BUG] PVC only works with plural annotation `volumes.kubernetes.io/storage-provisioner: driver.longhorn.io` ([4951](https://github.com/longhorn/longhorn/issues/4951)) - @weizhe0422
|
|
||||||
- [BUG] Failed to create a replenished replica process because of the newly adding option ([4962](https://github.com/longhorn/longhorn/issues/4962)) - @yangchiu @derekbit
|
|
||||||
- [BUG] Incorrect log messages in longhorn-engine processRemoveSnapshot() ([4980](https://github.com/longhorn/longhorn/issues/4980)) - @derekbit
|
|
||||||
- [BUG] System backup showing wrong age ([5047](https://github.com/longhorn/longhorn/issues/5047)) - @smallteeths @khushboo-rancher
|
|
||||||
- [BUG] System backup should validate empty backup target ([5055](https://github.com/longhorn/longhorn/issues/5055)) - @c3y1huang @khushboo-rancher
|
|
||||||
- [BUG] missing the `restoreVolumeRecurringJob` parameter in the VolumeGet API ([5062](https://github.com/longhorn/longhorn/issues/5062)) - @mantissahz @roger-ryao
|
|
||||||
- [BUG] System restore stuck in restoring if pvc exists with identical name ([5064](https://github.com/longhorn/longhorn/issues/5064)) - @c3y1huang @roger-ryao
|
|
||||||
- [BUG] No error shown on UI if system backup conf not available ([5072](https://github.com/longhorn/longhorn/issues/5072)) - @c3y1huang @khushboo-rancher
|
|
||||||
- [BUG] System restore missing services ([5074](https://github.com/longhorn/longhorn/issues/5074)) - @yangchiu @c3y1huang
|
|
||||||
- [BUG] In a system restore, PV & PVC are not restored if PVC was created with 'longhorn-static' (created via Longhorn GUI) ([5091](https://github.com/longhorn/longhorn/issues/5091)) - @c3y1huang @khushboo-rancher
|
|
||||||
- [BUG][v1.4.0-rc1] image security scan CRITICAL issues ([5107](https://github.com/longhorn/longhorn/issues/5107)) - @yangchiu @mantissahz
|
|
||||||
- [BUG] Snapshot trim wrong label in the volume detail page. ([5127](https://github.com/longhorn/longhorn/issues/5127)) - @smallteeths @chriscchien
|
|
||||||
- [BUG] Filesystem on the volume with a backing image is corrupted after applying trim operation ([5129](https://github.com/longhorn/longhorn/issues/5129)) - @derekbit @chriscchien
|
|
||||||
- [BUG] Error in uninstall job ([5132](https://github.com/longhorn/longhorn/issues/5132)) - @c3y1huang @chriscchien
|
|
||||||
- [BUG] Uninstall job unable to delete the systembackup and systemrestore cr. ([5133](https://github.com/longhorn/longhorn/issues/5133)) - @c3y1huang @chriscchien
|
|
||||||
- [BUG] Nil pointer dereference error on restoring the system backup ([5134](https://github.com/longhorn/longhorn/issues/5134)) - @yangchiu @c3y1huang
|
|
||||||
- [BUG] UI option Update Replicas Auto Balance should use capital letter like others ([5154](https://github.com/longhorn/longhorn/issues/5154)) - @smallteeths @chriscchien
|
|
||||||
- [BUG] System restore cannot roll out when volume name is different to the PV ([5157](https://github.com/longhorn/longhorn/issues/5157)) - @yangchiu @c3y1huang
|
|
||||||
- [BUG] Online expansion doesn't succeed after a failed expansion ([5169](https://github.com/longhorn/longhorn/issues/5169)) - @derekbit @shuo-wu @khushboo-rancher
|
|
||||||
|
|
||||||
## Misc
|
|
||||||
|
|
||||||
- [DOC] RWX support for NVIDIA JETSON Ubuntu 18.4LTS kernel requires enabling NFSV4.1 ([3157](https://github.com/longhorn/longhorn/issues/3157)) - @yangchiu @derekbit
|
|
||||||
- [DOC] Add information about encryption algorithm to documentation ([3285](https://github.com/longhorn/longhorn/issues/3285)) - @mantissahz
|
|
||||||
- [DOC] Update the doc of volume size after introducing snapshot prune ([4158](https://github.com/longhorn/longhorn/issues/4158)) - @shuo-wu
|
|
||||||
- [Doc] Update the outdated "Customizing Default Settings" document ([4174](https://github.com/longhorn/longhorn/issues/4174)) - @derekbit
|
|
||||||
- [TASK] Refresh distro version support for 1.4 ([4401](https://github.com/longhorn/longhorn/issues/4401)) - @weizhe0422
|
|
||||||
- [TASK] Update official document Longhorn Networking ([4478](https://github.com/longhorn/longhorn/issues/4478)) - @derekbit
|
|
||||||
- [TASK] Update preserveUnknownFields fields in longhorn-manager CRD manifest ([4505](https://github.com/longhorn/longhorn/issues/4505)) - @derekbit @roger-ryao
|
|
||||||
- [TASK] Disable doc search for archived versions < 1.1 ([4524](https://github.com/longhorn/longhorn/issues/4524)) - @mantissahz
|
|
||||||
- [TASK] Update longhorn components with the latest backupstore ([4552](https://github.com/longhorn/longhorn/issues/4552)) - @derekbit
|
|
||||||
- [TASK] Update base image of all components from BCI 15.3 to 15.4 ([4617](https://github.com/longhorn/longhorn/issues/4617)) - @yangchiu
|
|
||||||
- [DOC] Update the Longhorn document in Install with Helm ([4745](https://github.com/longhorn/longhorn/issues/4745)) - @roger-ryao
|
|
||||||
- [TASK] Create longhornio support-bundle-kit image ([4911](https://github.com/longhorn/longhorn/issues/4911)) - @yangchiu
|
|
||||||
- [DOC] Add Recurring * Jobs History Limit to setting reference ([4912](https://github.com/longhorn/longhorn/issues/4912)) - @weizhe0422 @roger-ryao
|
|
||||||
- [DOC] Add Failed Backup TTL to setting reference ([4913](https://github.com/longhorn/longhorn/issues/4913)) - @mantissahz
|
|
||||||
- [TASK] Create longhornio liveness probe image ([4945](https://github.com/longhorn/longhorn/issues/4945)) - @yangchiu
|
|
||||||
- [TASK] Make system managed components branch-based build ([5024](https://github.com/longhorn/longhorn/issues/5024)) - @yangchiu
|
|
||||||
- [TASK] Remove unstable s390x from PR check for all repos ([5040](https://github.com/longhorn/longhorn/issues/5040)) -
|
|
||||||
- [TASK] Update longhorn-share-manager's nfs-ganesha to V4.2.1 ([5083](https://github.com/longhorn/longhorn/issues/5083)) - @derekbit @mantissahz
|
|
||||||
- [DOC] Update the Longhorn document in Setting up Prometheus and Grafana ([5158](https://github.com/longhorn/longhorn/issues/5158)) - @roger-ryao
|
|
||||||
|
|
||||||
## Contributors
|
|
||||||
|
|
||||||
- @FrankYang0529
|
|
||||||
- @PhanLe1010
|
|
||||||
- @c3y1huang
|
|
||||||
- @chriscchien
|
|
||||||
- @derekbit
|
|
||||||
- @flkdnt
|
|
||||||
- @innobead
|
|
||||||
- @joshimoo
|
|
||||||
- @khushboo-rancher
|
|
||||||
- @mantissahz
|
|
||||||
- @olljanat
|
|
||||||
- @roger-ryao
|
|
||||||
- @shuo-wu
|
|
||||||
- @smallteeths
|
|
||||||
- @w13915984028
|
|
||||||
- @weizhe0422
|
|
||||||
- @yangchiu
|
|
||||||
@ -1,88 +0,0 @@
|
|||||||
## Release Note
|
|
||||||
**v1.4.1 released!** 🎆
|
|
||||||
|
|
||||||
This release introduces improvements and bug fixes as described below about stability, performance, space efficiency, resilience, and so on. Please try it and feedback. Thanks for all the contributions!
|
|
||||||
|
|
||||||
## Installation
|
|
||||||
|
|
||||||
> **Please ensure your Kubernetes cluster is at least v1.21 before installing Longhorn v1.4.1.**
|
|
||||||
|
|
||||||
Longhorn supports 3 installation ways including Rancher App Marketplace, Kubectl, and Helm. Follow the installation instructions [here](https://longhorn.io/docs/1.4.1/deploy/install/).
|
|
||||||
|
|
||||||
## Upgrade
|
|
||||||
|
|
||||||
> **Please ensure your Kubernetes cluster is at least v1.21 before upgrading to Longhorn v1.4.1 from v1.3.x/v1.4.0, which are only supported source versions.**
|
|
||||||
|
|
||||||
Follow the upgrade instructions [here](https://longhorn.io/docs/1.4.1/deploy/upgrade/).
|
|
||||||
|
|
||||||
## Deprecation & Incompatibilities
|
|
||||||
|
|
||||||
N/A
|
|
||||||
|
|
||||||
## Known Issues after Release
|
|
||||||
|
|
||||||
Please follow up on [here](https://github.com/longhorn/longhorn/wiki/Outstanding-Known-Issues-of-Releases) about any outstanding issues found after this release.
|
|
||||||
|
|
||||||
|
|
||||||
## Highlights
|
|
||||||
|
|
||||||
- [IMPROVEMENT] Periodically clean up volume snapshots ([3836](https://github.com/longhorn/longhorn/issues/3836)) - @c3y1huang @chriscchien
|
|
||||||
|
|
||||||
## Improvement
|
|
||||||
|
|
||||||
- [IMPROVEMENT] Do not count the failure replica reuse failure caused by the disconnection ([1923](https://github.com/longhorn/longhorn/issues/1923)) - @yangchiu @mantissahz
|
|
||||||
- [IMPROVEMENT] Update uninstallation info to include the 'Deleting Confirmation Flag' in chart ([5250](https://github.com/longhorn/longhorn/issues/5250)) - @PhanLe1010 @roger-ryao
|
|
||||||
- [IMPROVEMENT] Fix Guaranteed Engine Manager CPU recommendation formula in UI ([5338](https://github.com/longhorn/longhorn/issues/5338)) - @c3y1huang @smallteeths @roger-ryao
|
|
||||||
- [IMPROVEMENT] Update PSP validation in the Longhorn upstream chart ([5339](https://github.com/longhorn/longhorn/issues/5339)) - @yangchiu @PhanLe1010
|
|
||||||
- [IMPROVEMENT] Update ganesha nfs to 4.2.3 ([5356](https://github.com/longhorn/longhorn/issues/5356)) - @derekbit @roger-ryao
|
|
||||||
- [IMPROVEMENT] Set write-cache of longhorn block device to off explicitly ([5382](https://github.com/longhorn/longhorn/issues/5382)) - @derekbit @chriscchien
|
|
||||||
|
|
||||||
## Stability
|
|
||||||
|
|
||||||
- [BUG] Memory leak in CSI plugin caused by stuck umount processes if the RWX volume is already gone ([5296](https://github.com/longhorn/longhorn/issues/5296)) - @derekbit @roger-ryao
|
|
||||||
- [BUG] share-manager pod failed to restart after kubelet restart ([5507](https://github.com/longhorn/longhorn/issues/5507)) - @yangchiu @derekbit
|
|
||||||
|
|
||||||
## Bugs
|
|
||||||
|
|
||||||
- [BUG] Longhorn 1.3.2 fails to backup & restore volumes behind Internet proxy ([5054](https://github.com/longhorn/longhorn/issues/5054)) - @mantissahz @chriscchien
|
|
||||||
- [BUG] RWX doesn't work with release 1.4.0 due to end grace update error from recovery backend ([5183](https://github.com/longhorn/longhorn/issues/5183)) - @derekbit @chriscchien
|
|
||||||
- [BUG] Incorrect indentation of charts/questions.yaml ([5196](https://github.com/longhorn/longhorn/issues/5196)) - @mantissahz @roger-ryao
|
|
||||||
- [BUG] Updating option "Allow snapshots removal during trim" for old volumes failed ([5218](https://github.com/longhorn/longhorn/issues/5218)) - @shuo-wu @roger-ryao
|
|
||||||
- [BUG] Incorrect router retry mechanism ([5259](https://github.com/longhorn/longhorn/issues/5259)) - @mantissahz @chriscchien
|
|
||||||
- [BUG] System Backup is stuck at Uploading if there are PVs not provisioned by CSI driver ([5286](https://github.com/longhorn/longhorn/issues/5286)) - @c3y1huang @chriscchien
|
|
||||||
- [BUG] Sync up with backup target during DR volume activation ([5292](https://github.com/longhorn/longhorn/issues/5292)) - @yangchiu @weizhe0422
|
|
||||||
- [BUG] environment_check.sh does not handle different kernel versions in cluster correctly ([5304](https://github.com/longhorn/longhorn/issues/5304)) - @achims311 @roger-ryao
|
|
||||||
- [BUG] instance-manager-r high memory consumption ([5312](https://github.com/longhorn/longhorn/issues/5312)) - @derekbit @roger-ryao
|
|
||||||
- [BUG] Replica rebuilding caused by rke2/kubelet restart ([5340](https://github.com/longhorn/longhorn/issues/5340)) - @derekbit @chriscchien
|
|
||||||
- [BUG] Error message not consistent between create/update recurring job when retain number greater than 50 ([5434](https://github.com/longhorn/longhorn/issues/5434)) - @c3y1huang @chriscchien
|
|
||||||
- [BUG] Do not copy Host header to API requests forwarded to Longhorn Manager ([5438](https://github.com/longhorn/longhorn/issues/5438)) - @yangchiu @smallteeths
|
|
||||||
- [BUG] RWX Volume attachment is getting Failed ([5456](https://github.com/longhorn/longhorn/issues/5456)) - @derekbit
|
|
||||||
- [BUG] test case test_backup_lock_deletion_during_restoration failed ([5458](https://github.com/longhorn/longhorn/issues/5458)) - @yangchiu @derekbit
|
|
||||||
- [BUG] [master] [v1.4.1-rc1] Volume restoration will never complete if attached node is down ([5464](https://github.com/longhorn/longhorn/issues/5464)) - @derekbit @weizhe0422 @chriscchien
|
|
||||||
- [BUG] Unable to create support bundle agent pod in air-gap environment ([5467](https://github.com/longhorn/longhorn/issues/5467)) - @yangchiu @c3y1huang
|
|
||||||
- [BUG] Node disconnection test failed ([5476](https://github.com/longhorn/longhorn/issues/5476)) - @yangchiu @derekbit
|
|
||||||
- [BUG] Physical node down test failed ([5477](https://github.com/longhorn/longhorn/issues/5477)) - @derekbit @chriscchien
|
|
||||||
- [BUG] Backing image with sync failure ([5481](https://github.com/longhorn/longhorn/issues/5481)) - @ChanYiLin @roger-ryao
|
|
||||||
- [BUG] Example of data migration doesn't work for hidden/./dot-files) ([5484](https://github.com/longhorn/longhorn/issues/5484)) - @hedefalk @shuo-wu @chriscchien
|
|
||||||
- [BUG] test case test_dr_volume_with_backup_block_deletion failed ([5489](https://github.com/longhorn/longhorn/issues/5489)) - @yangchiu @derekbit
|
|
||||||
|
|
||||||
## Misc
|
|
||||||
|
|
||||||
- [TASK][UI] add new recurring job tasks ([5272](https://github.com/longhorn/longhorn/issues/5272)) - @smallteeths @chriscchien
|
|
||||||
|
|
||||||
## Contributors
|
|
||||||
|
|
||||||
- @ChanYiLin
|
|
||||||
- @PhanLe1010
|
|
||||||
- @achims311
|
|
||||||
- @c3y1huang
|
|
||||||
- @chriscchien
|
|
||||||
- @derekbit
|
|
||||||
- @hedefalk
|
|
||||||
- @innobead
|
|
||||||
- @mantissahz
|
|
||||||
- @roger-ryao
|
|
||||||
- @shuo-wu
|
|
||||||
- @smallteeths
|
|
||||||
- @weizhe0422
|
|
||||||
- @yangchiu
|
|
||||||
@ -1,92 +0,0 @@
|
|||||||
## Release Note
|
|
||||||
### **v1.4.2 released!** 🎆
|
|
||||||
|
|
||||||
Longhorn v1.4.2 is the latest stable version of Longhorn 1.4.
|
|
||||||
It introduces improvements and bug fixes in the areas of stability, performance, space efficiency, resilience, and so on. Please try it out and provide feedback. Thanks for all the contributions!
|
|
||||||
|
|
||||||
> For the definition of stable or latest release, please check [here](https://github.com/longhorn/longhorn#releases).
|
|
||||||
|
|
||||||
## Installation
|
|
||||||
|
|
||||||
> **Please ensure your Kubernetes cluster is at least v1.21 before installing v1.4.2.**
|
|
||||||
|
|
||||||
Longhorn supports 3 installation ways including Rancher App Marketplace, Kubectl, and Helm. Follow the installation instructions [here](https://longhorn.io/docs/1.4.2/deploy/install/).
|
|
||||||
|
|
||||||
## Upgrade
|
|
||||||
|
|
||||||
> **Please read the [important notes](https://longhorn.io/docs/1.4.2/deploy/important-notes/) first and ensure your Kubernetes cluster is at least v1.21 before upgrading to Longhorn v1.4.2 from v1.3.x/v1.4.x, which are only supported source versions.**
|
|
||||||
|
|
||||||
Follow the upgrade instructions [here](https://longhorn.io/docs/1.4.2/deploy/upgrade/).
|
|
||||||
|
|
||||||
## Deprecation & Incompatibilities
|
|
||||||
|
|
||||||
N/A
|
|
||||||
|
|
||||||
## Known Issues after Release
|
|
||||||
|
|
||||||
Please follow up on [here](https://github.com/longhorn/longhorn/wiki/Outstanding-Known-Issues-of-Releases) about any outstanding issues found after this release.
|
|
||||||
|
|
||||||
|
|
||||||
## Highlights
|
|
||||||
|
|
||||||
- [IMPROVEMENT] Use PDB to protect Longhorn components from unexpected drains ([3304](https://github.com/longhorn/longhorn/issues/3304)) - @yangchiu @PhanLe1010
|
|
||||||
- [IMPROVEMENT] Introduce timeout mechanism for the sparse file syncing service ([4305](https://github.com/longhorn/longhorn/issues/4305)) - @yangchiu @ChanYiLin
|
|
||||||
- [IMPROVEMENT] Recurring jobs create new snapshots while being not able to clean up old ones ([4898](https://github.com/longhorn/longhorn/issues/4898)) - @mantissahz @chriscchien
|
|
||||||
|
|
||||||
## Improvement
|
|
||||||
|
|
||||||
- [IMPROVEMENT] Support bundle collects dmesg, syslog and related information of longhorn nodes ([5073](https://github.com/longhorn/longhorn/issues/5073)) - @weizhe0422 @roger-ryao
|
|
||||||
- [IMPROVEMENT] Fix BackingImage uploading/downloading flow to prevent client timeout ([5443](https://github.com/longhorn/longhorn/issues/5443)) - @ChanYiLin @chriscchien
|
|
||||||
- [IMPROVEMENT] Create a new setting so that Longhorn removes PDB for instance-manager-r that doesn't have any running instance inside it ([5549](https://github.com/longhorn/longhorn/issues/5549)) - @PhanLe1010 @khushboo-rancher
|
|
||||||
- [IMPROVEMENT] Deprecate the setting `allow-node-drain-with-last-healthy-replica` and replace it by `node-drain-policy` setting ([5585](https://github.com/longhorn/longhorn/issues/5585)) - @yangchiu @PhanLe1010
|
|
||||||
- [IMPROVEMENT][UI] Recurring jobs create new snapshots while being not able to clean up old one ([5610](https://github.com/longhorn/longhorn/issues/5610)) - @mantissahz @smallteeths @roger-ryao
|
|
||||||
- [IMPROVEMENT] Only activate replica if it doesn't have deletion timestamp during volume engine upgrade ([5632](https://github.com/longhorn/longhorn/issues/5632)) - @PhanLe1010 @roger-ryao
|
|
||||||
- [IMPROVEMENT] Clean up backup target if the backup target setting is unset ([5655](https://github.com/longhorn/longhorn/issues/5655)) - @yangchiu @ChanYiLin
|
|
||||||
|
|
||||||
## Resilience
|
|
||||||
|
|
||||||
- [BUG] Directly mark replica as failed if the node is deleted ([5542](https://github.com/longhorn/longhorn/issues/5542)) - @weizhe0422 @roger-ryao
|
|
||||||
- [BUG] RWX volume is stuck at detaching when the attached node is down ([5558](https://github.com/longhorn/longhorn/issues/5558)) - @derekbit @roger-ryao
|
|
||||||
- [BUG] Backup monitor gets stuck in an infinite loop if backup isn't found ([5662](https://github.com/longhorn/longhorn/issues/5662)) - @derekbit @chriscchien
|
|
||||||
- [BUG] Resources such as replicas are somehow not mutated when network is unstable ([5762](https://github.com/longhorn/longhorn/issues/5762)) - @derekbit @roger-ryao
|
|
||||||
- [BUG] Instance manager may not update instance status for a minute after starting ([5809](https://github.com/longhorn/longhorn/issues/5809)) - @ejweber @chriscchien
|
|
||||||
|
|
||||||
## Bugs
|
|
||||||
|
|
||||||
- [BUG] Delete a uploading backing image, the corresponding LH temp file is not deleted ([3682](https://github.com/longhorn/longhorn/issues/3682)) - @ChanYiLin @chriscchien
|
|
||||||
- [BUG] Can not create backup in engine image not fully deployed cluster ([5248](https://github.com/longhorn/longhorn/issues/5248)) - @ChanYiLin @roger-ryao
|
|
||||||
- [BUG] Upgrade engine --> spec.restoreVolumeRecurringJob and spec.snapshotDataIntegrity Unsupported value ([5485](https://github.com/longhorn/longhorn/issues/5485)) - @yangchiu @derekbit
|
|
||||||
- [BUG] Bulk backup deletion cause restoring volume to finish with attached state. ([5506](https://github.com/longhorn/longhorn/issues/5506)) - @ChanYiLin @roger-ryao
|
|
||||||
- [BUG] volume expansion starts for no reason, gets stuck on current size > expected size ([5513](https://github.com/longhorn/longhorn/issues/5513)) - @mantissahz @roger-ryao
|
|
||||||
- [BUG] RWX volume attachment failed if tried more enough times ([5537](https://github.com/longhorn/longhorn/issues/5537)) - @yangchiu @derekbit
|
|
||||||
- [BUG] instance-manager-e emits `Wait for process pvc-xxxx to shutdown` constantly ([5575](https://github.com/longhorn/longhorn/issues/5575)) - @derekbit @roger-ryao
|
|
||||||
- [BUG] Support bundle kit should respect node selector & taint toleration ([5614](https://github.com/longhorn/longhorn/issues/5614)) - @yangchiu @c3y1huang
|
|
||||||
- [BUG] Value overlapped in page Instance Manager Image ([5622](https://github.com/longhorn/longhorn/issues/5622)) - @smallteeths @chriscchien
|
|
||||||
- [BUG] Instance manager PDB created with wrong selector thus blocking the draining of the wrongly selected node forever ([5680](https://github.com/longhorn/longhorn/issues/5680)) - @PhanLe1010 @chriscchien
|
|
||||||
- [BUG] During volume live engine upgrade, if the replica pod is killed, the volume is stuck in upgrading forever ([5684](https://github.com/longhorn/longhorn/issues/5684)) - @yangchiu @PhanLe1010
|
|
||||||
- [BUG] Instance manager PDBs cannot be removed if the longhorn-manager pod on its spec node is not available ([5688](https://github.com/longhorn/longhorn/issues/5688)) - @PhanLe1010 @roger-ryao
|
|
||||||
- [BUG] Rebuild rebuilding is possibly issued to a wrong replica ([5709](https://github.com/longhorn/longhorn/issues/5709)) - @ejweber @roger-ryao
|
|
||||||
- [BUG] longhorn upgrade is not upgrading engineimage ([5740](https://github.com/longhorn/longhorn/issues/5740)) - @shuo-wu @chriscchien
|
|
||||||
- [BUG] `test_replica_auto_balance_when_replica_on_unschedulable_node` Error in creating volume with nodeSelector and dataLocality parameters ([5745](https://github.com/longhorn/longhorn/issues/5745)) - @c3y1huang @roger-ryao
|
|
||||||
- [BUG] Unable to backup volume after NFS server IP change ([5856](https://github.com/longhorn/longhorn/issues/5856)) - @derekbit @roger-ryao
|
|
||||||
|
|
||||||
## Misc
|
|
||||||
|
|
||||||
- [TASK] Check and update the networking doc & example YAMLs ([5651](https://github.com/longhorn/longhorn/issues/5651)) - @yangchiu @shuo-wu
|
|
||||||
|
|
||||||
## Contributors
|
|
||||||
|
|
||||||
- @ChanYiLin
|
|
||||||
- @PhanLe1010
|
|
||||||
- @c3y1huang
|
|
||||||
- @chriscchien
|
|
||||||
- @derekbit
|
|
||||||
- @ejweber
|
|
||||||
- @innobead
|
|
||||||
- @khushboo-rancher
|
|
||||||
- @mantissahz
|
|
||||||
- @roger-ryao
|
|
||||||
- @shuo-wu
|
|
||||||
- @smallteeths
|
|
||||||
- @weizhe0422
|
|
||||||
- @yangchiu
|
|
||||||
@ -1,74 +0,0 @@
|
|||||||
## Release Note
|
|
||||||
### **v1.4.3 released!** 🎆
|
|
||||||
|
|
||||||
Longhorn v1.4.3 is the latest stable version of Longhorn 1.4.
|
|
||||||
It introduces improvements and bug fixes in the areas of stability, resilience, and so on. Please try it out and provide feedback. Thanks for all the contributions!
|
|
||||||
|
|
||||||
> For the definition of stable or latest release, please check [here](https://github.com/longhorn/longhorn#releases).
|
|
||||||
|
|
||||||
## Installation
|
|
||||||
|
|
||||||
> **Please ensure your Kubernetes cluster is at least v1.21 before installing v1.4.3.**
|
|
||||||
|
|
||||||
Longhorn supports 3 installation ways including Rancher App Marketplace, Kubectl, and Helm. Follow the installation instructions [here](https://longhorn.io/docs/1.4.3/deploy/install/).
|
|
||||||
|
|
||||||
## Upgrade
|
|
||||||
|
|
||||||
> **Please read the [important notes](https://longhorn.io/docs/1.4.3/deploy/important-notes/) first and ensure your Kubernetes cluster is at least v1.21 before upgrading to Longhorn v1.4.3 from v1.3.x/v1.4.x, which are only supported source versions.**
|
|
||||||
|
|
||||||
Follow the upgrade instructions [here](https://longhorn.io/docs/1.4.3/deploy/upgrade/).
|
|
||||||
|
|
||||||
## Deprecation & Incompatibilities
|
|
||||||
|
|
||||||
N/A
|
|
||||||
|
|
||||||
## Known Issues after Release
|
|
||||||
|
|
||||||
Please follow up on [here](https://github.com/longhorn/longhorn/wiki/Outstanding-Known-Issues-of-Releases) about any outstanding issues found after this release.
|
|
||||||
|
|
||||||
|
|
||||||
## Improvement
|
|
||||||
|
|
||||||
- [IMPROVEMENT] Assign the pods to the same node where the strict-local volume is present ([5448](https://github.com/longhorn/longhorn/issues/5448)) - @c3y1huang @chriscchien
|
|
||||||
|
|
||||||
## Resilience
|
|
||||||
|
|
||||||
- [BUG] filesystem corrupted after delete instance-manager-r for a locality best-effort volume ([5801](https://github.com/longhorn/longhorn/issues/5801)) - @yangchiu @ChanYiLin @mantissahz
|
|
||||||
|
|
||||||
## Bugs
|
|
||||||
|
|
||||||
- [BUG] 'Upgrade Engine' still shows up in a specific situation when engine already upgraded ([3063](https://github.com/longhorn/longhorn/issues/3063)) - @weizhe0422 @PhanLe1010 @smallteeths
|
|
||||||
- [BUG] DR volume even after activation remains in standby mode if there are one or more failed replicas. ([3069](https://github.com/longhorn/longhorn/issues/3069)) - @yangchiu @mantissahz
|
|
||||||
- [BUG] Prevent Longhorn uninstallation from getting stuck due to backups in error ([5868](https://github.com/longhorn/longhorn/issues/5868)) - @ChanYiLin @mantissahz
|
|
||||||
- [BUG] Unable to create support bundle if the previous one stayed in ReadyForDownload phase ([5882](https://github.com/longhorn/longhorn/issues/5882)) - @c3y1huang @roger-ryao
|
|
||||||
- [BUG] share-manager for a given pvc keep restarting (other pvc are working fine) ([5954](https://github.com/longhorn/longhorn/issues/5954)) - @yangchiu @derekbit
|
|
||||||
- [BUG] Replica auto-rebalance doesn't respect node selector ([5971](https://github.com/longhorn/longhorn/issues/5971)) - @c3y1huang @roger-ryao
|
|
||||||
- [BUG] Extra snapshot generated when clone from a detached volume ([5986](https://github.com/longhorn/longhorn/issues/5986)) - @weizhe0422 @ejweber
|
|
||||||
- [BUG] User created snapshot deleted after node drain and uncordon ([5992](https://github.com/longhorn/longhorn/issues/5992)) - @yangchiu @mantissahz
|
|
||||||
- [BUG] In some specific situation, system backup auto deleted when creating another one ([6045](https://github.com/longhorn/longhorn/issues/6045)) - @c3y1huang @chriscchien
|
|
||||||
- [BUG] Backing Image deletion stuck if it's deleted during uploading process and bids is ready-for-transfer state ([6086](https://github.com/longhorn/longhorn/issues/6086)) - @WebberHuang1118 @chriscchien
|
|
||||||
- [BUG] Backing image manager fails when SELinux is enabled ([6108](https://github.com/longhorn/longhorn/issues/6108)) - @ejweber @chriscchien
|
|
||||||
- [BUG] test_dr_volume_with_restore_command_error failed ([6130](https://github.com/longhorn/longhorn/issues/6130)) - @mantissahz @roger-ryao
|
|
||||||
- [BUG] Longhorn doesn't remove the system backups crd on uninstallation ([6185](https://github.com/longhorn/longhorn/issues/6185)) - @c3y1huang @khushboo-rancher
|
|
||||||
- [BUG] Test case test_ha_backup_deletion_recovery failed in rhel or rockylinux arm64 environment ([6213](https://github.com/longhorn/longhorn/issues/6213)) - @yangchiu @ChanYiLin @mantissahz
|
|
||||||
- [BUG] Engine continues to attempt to rebuild replica while detaching ([6217](https://github.com/longhorn/longhorn/issues/6217)) - @yangchiu @ejweber
|
|
||||||
- [BUG] Unable to receive support bundle from UI when it's large (400MB+) ([6256](https://github.com/longhorn/longhorn/issues/6256)) - @c3y1huang @chriscchien
|
|
||||||
- [BUG] Migration test case failed: unable to detach volume migration is not ready yet ([6238](https://github.com/longhorn/longhorn/issues/6238)) - @yangchiu @PhanLe1010 @khushboo-rancher
|
|
||||||
- [BUG] Restored Volumes stuck in attaching state ([6239](https://github.com/longhorn/longhorn/issues/6239)) - @derekbit @roger-ryao
|
|
||||||
|
|
||||||
## Contributors
|
|
||||||
|
|
||||||
- @ChanYiLin
|
|
||||||
- @PhanLe1010
|
|
||||||
- @WebberHuang1118
|
|
||||||
- @c3y1huang
|
|
||||||
- @chriscchien
|
|
||||||
- @derekbit
|
|
||||||
- @ejweber
|
|
||||||
- @innobead
|
|
||||||
- @khushboo-rancher
|
|
||||||
- @mantissahz
|
|
||||||
- @roger-ryao
|
|
||||||
- @smallteeths
|
|
||||||
- @weizhe0422
|
|
||||||
- @yangchiu
|
|
||||||
@ -1,301 +0,0 @@
|
|||||||
## Release Note
|
|
||||||
### **v1.5.0 released!** 🎆
|
|
||||||
|
|
||||||
Longhorn v1.5.0 is the latest version of Longhorn 1.5.
|
|
||||||
It introduces many enhancements, improvements, and bug fixes as described below including performance, stability, maintenance, resilience, and so on. Please try it and feedback. Thanks for all the contributions!
|
|
||||||
|
|
||||||
> For the definition of stable or latest release, please check [here](https://github.com/longhorn/longhorn#releases).
|
|
||||||
|
|
||||||
- [v2 Data Engine based on SPDK - Preview](https://github.com/longhorn/longhorn/issues/5751)
|
|
||||||
> **Please note that this is a preview feature, so should not be used in any production environment. A preview feature is disabled by default and would be changed in the following versions until it becomes general availability.**
|
|
||||||
|
|
||||||
In addition to the existing iSCSI stack (v1) data engine, we are introducing the v2 data engine based on SPDK (Storage Performance Development Kit). This release includes the introduction of volume lifecycle management, degraded volume handling, offline replica rebuilding, block device management, and orphaned replica management. For the performance benchmark and comparison with v1, check the report [here](https://longhorn.io/docs/1.5.0/spdk/performance-benchmark/).
|
|
||||||
|
|
||||||
- [Longhorn Volume Attachment](https://github.com/longhorn/longhorn/issues/3715)
|
|
||||||
Introducing the new Longhorn VolumeAttachment CR, which ensures exclusive attachment and supports automatic volume attachment and detachment for various headless operations such as volume cloning, backing image export, and recurring jobs.
|
|
||||||
|
|
||||||
- [Cluster Autoscaler - GA](https://github.com/longhorn/longhorn/issues/5238)
|
|
||||||
Cluster Autoscaler was initially introduced as an experimental feature in v1.3. After undergoing automatic validation on different public cloud Kubernetes distributions and receiving user feedback, it has now reached general availability.
|
|
||||||
|
|
||||||
- [Instance Manager Engine & Replica Consolidation](https://github.com/longhorn/longhorn/issues/5208)
|
|
||||||
Previously, there were two separate instance manager pods responsible for volume engine and replica process management. However, this setup required high resource usage, especially during live upgrades. In this release, we have merged these pods into a single instance manager, reducing the initial resource requirements.
|
|
||||||
|
|
||||||
- [Volume Backup Compression Methods](https://github.com/longhorn/longhorn/issues/5189)
|
|
||||||
Longhorn supports different compression methods for volume backups, including lz4, gzip, or no compression. This allows users to choose the most suitable method based on their data type and usage requirements.
|
|
||||||
|
|
||||||
- [Automatic Volume Trim Recurring Job](https://github.com/longhorn/longhorn/issues/5186)
|
|
||||||
While volume filesystem trim was introduced in v1.4, users had to perform the operation manually. From this release, users can create a recurring job that automatically runs the trim process, improving space efficiency without requiring human intervention.
|
|
||||||
|
|
||||||
- [RWX Volume Trim](https://github.com/longhorn/longhorn/issues/5143)
|
|
||||||
Longhorn supports filesystem trim for RWX (Read-Write-Many) volumes, expanding the trim functionality beyond RWO (Read-Write-Once) volumes only.
|
|
||||||
|
|
||||||
- [Upgrade Path Enforcement & Downgrade Prevention](https://github.com/longhorn/longhorn/issues/5131)
|
|
||||||
To ensure compatibility after an upgrade, we have implemented upgrade path enforcement. This prevents unintended downgrades and ensures the system and data remain intact.
|
|
||||||
|
|
||||||
- [Backing Image Management via CSI VolumeSnapshot](https://github.com/longhorn/longhorn/issues/5005)
|
|
||||||
Users can now utilize the unified CSI VolumeSnapshot interface to manage Backing Images similar to volume snapshots and backups.
|
|
||||||
|
|
||||||
- [Snapshot Cleanup & Delete Recurring Job](https://github.com/longhorn/longhorn/issues/3836)
|
|
||||||
Introducing two new recurring job types specifically designed for snapshot cleanup and deletion. These jobs allow users to remove unnecessary snapshots for better space efficiency.
|
|
||||||
|
|
||||||
- [CIFS Backup Store](https://github.com/longhorn/longhorn/issues/3599) & [Azure Backup Store](https://github.com/longhorn/longhorn/issues/1309)
|
|
||||||
To enhance users' backup strategies and align with data governance policies, Longhorn now supports additional backup storage protocols, including CIFS and Azure.
|
|
||||||
|
|
||||||
- [Kubernetes Upgrade Node Drain Policy](https://github.com/longhorn/longhorn/issues/3304)
|
|
||||||
The new Node Drain Policy provides flexible strategies to protect volume data during Kubernetes upgrades or node maintenance operations. This ensures the integrity and availability of your volumes.
|
|
||||||
|
|
||||||
## Installation
|
|
||||||
|
|
||||||
> **Please ensure your Kubernetes cluster is at least v1.21 before installing Longhorn v1.5.0.**
|
|
||||||
|
|
||||||
Longhorn supports 3 installation ways including Rancher App Marketplace, Kubectl, and Helm. Follow the installation instructions [here](https://longhorn.io/docs/1.5.0/deploy/install/).
|
|
||||||
|
|
||||||
## Upgrade
|
|
||||||
|
|
||||||
> **Please ensure your Kubernetes cluster is at least v1.21 before upgrading to Longhorn v1.5.0 from v1.4.x. Only support upgrading from 1.4.x.**
|
|
||||||
|
|
||||||
Follow the upgrade instructions [here](https://longhorn.io/docs/1.5.0/deploy/upgrade/).
|
|
||||||
|
|
||||||
## Deprecation & Incompatibilities
|
|
||||||
|
|
||||||
Please check the [important notes](https://longhorn.io/docs/1.5.0/deploy/important-notes/) to know more about deprecated, removed, incompatible features and important changes. If you upgrade indirectly from an older version like v1.3.x, please also check the corresponding important note for each upgrade version path.
|
|
||||||
|
|
||||||
## Known Issues after Release
|
|
||||||
|
|
||||||
Please follow up on [here](https://github.com/longhorn/longhorn/wiki/Outstanding-Known-Issues-of-Releases) about any outstanding issues found after this release.
|
|
||||||
|
|
||||||
## Highlights
|
|
||||||
|
|
||||||
- [DOC] Provide the user guide for Kubernetes upgrade ([494](https://github.com/longhorn/longhorn/issues/494)) - @PhanLe1010
|
|
||||||
- [FEATURE] Backups to Azure Blob Storage ([1309](https://github.com/longhorn/longhorn/issues/1309)) - @mantissahz @chriscchien
|
|
||||||
- [IMPROVEMENT] Use PDB to protect Longhorn components from unexpected drains ([3304](https://github.com/longhorn/longhorn/issues/3304)) - @yangchiu @PhanLe1010
|
|
||||||
- [FEATURE] CIFS Backup Store Support ([3599](https://github.com/longhorn/longhorn/issues/3599)) - @derekbit @chriscchien
|
|
||||||
- [IMPROVEMENT] Consolidate volume attach/detach implementation ([3715](https://github.com/longhorn/longhorn/issues/3715)) - @yangchiu @PhanLe1010
|
|
||||||
- [IMPROVEMENT] Periodically clean up volume snapshots ([3836](https://github.com/longhorn/longhorn/issues/3836)) - @c3y1huang @chriscchien
|
|
||||||
- [IMPROVEMENT] Introduce timeout mechanism for the sparse file syncing service ([4305](https://github.com/longhorn/longhorn/issues/4305)) - @yangchiu @ChanYiLin
|
|
||||||
- [IMPROVEMENT] Recurring jobs create new snapshots while being not able to clean up old ones ([4898](https://github.com/longhorn/longhorn/issues/4898)) - @mantissahz @chriscchien
|
|
||||||
- [FEATURE] BackingImage Management via VolumeSnapshot ([5005](https://github.com/longhorn/longhorn/issues/5005)) - @ChanYiLin @chriscchien
|
|
||||||
- [FEATURE] Upgrade path enforcement & downgrade prevention ([5131](https://github.com/longhorn/longhorn/issues/5131)) - @yangchiu @mantissahz
|
|
||||||
- [FEATURE] Support RWX volume trim ([5143](https://github.com/longhorn/longhorn/issues/5143)) - @derekbit @chriscchien
|
|
||||||
- [FEATURE] Auto Trim via recurring job ([5186](https://github.com/longhorn/longhorn/issues/5186)) - @c3y1huang @chriscchien
|
|
||||||
- [FEATURE] Introduce faster compression and multiple threads for volume backup & restore ([5189](https://github.com/longhorn/longhorn/issues/5189)) - @derekbit @roger-ryao
|
|
||||||
- [FEATURE] Consolidate Instance Manager Engine & Replica for resource consumption reduction ([5208](https://github.com/longhorn/longhorn/issues/5208)) - @yangchiu @c3y1huang
|
|
||||||
- [FEATURE] Cluster Autoscaler Support GA ([5238](https://github.com/longhorn/longhorn/issues/5238)) - @yangchiu @c3y1huang
|
|
||||||
- [FEATURE] Update K8s version support and component/pkg/build dependencies for Longhorn 1.5 ([5595](https://github.com/longhorn/longhorn/issues/5595)) - @yangchiu @ejweber
|
|
||||||
- [FEATURE] Support SPDK Data Engine - Preview ([5751](https://github.com/longhorn/longhorn/issues/5751)) - @derekbit @shuo-wu @DamiaSan
|
|
||||||
|
|
||||||
## Enhancements
|
|
||||||
|
|
||||||
- [FEATURE] Allow users to directly activate a restoring/DR volume as long as there is one ready replica. ([1512](https://github.com/longhorn/longhorn/issues/1512)) - @mantissahz @weizhe0422
|
|
||||||
- [REFACTOR] volume controller refactoring/split up, to simplify the control flow ([2527](https://github.com/longhorn/longhorn/issues/2527)) - @PhanLe1010 @chriscchien
|
|
||||||
- [FEATURE] Import and export SPDK longhorn volumes to longhorn sparse file directory ([4100](https://github.com/longhorn/longhorn/issues/4100)) - @DamiaSan
|
|
||||||
- [FEATURE] Add a global `storage reserved` setting for newly created longhorn nodes' disks ([4773](https://github.com/longhorn/longhorn/issues/4773)) - @mantissahz @chriscchien
|
|
||||||
- [FEATURE] Support backup volumes during system backup ([5011](https://github.com/longhorn/longhorn/issues/5011)) - @c3y1huang @chriscchien
|
|
||||||
- [FEATURE] Support SPDK lvol shallow copy for newly replica creation ([5217](https://github.com/longhorn/longhorn/issues/5217)) - @DamiaSan
|
|
||||||
- [FEATURE] Introduce longhorn-spdk-engine for SPDK volume management ([5282](https://github.com/longhorn/longhorn/issues/5282)) - @shuo-wu
|
|
||||||
- [FEATURE] Support replica-zone-soft-anti-affinity setting per volume ([5358](https://github.com/longhorn/longhorn/issues/5358)) - @ChanYiLin @smallteeths @chriscchien
|
|
||||||
- [FEATURE] Install Opt-In NetworkPolicies ([5403](https://github.com/longhorn/longhorn/issues/5403)) - @yangchiu @ChanYiLin
|
|
||||||
- [FEATURE] Create Longhorn SPDK Engine component with basic fundamental functions ([5406](https://github.com/longhorn/longhorn/issues/5406)) - @shuo-wu
|
|
||||||
- [FEATURE] Add status APIs for shallow copy and IO pause/resume ([5647](https://github.com/longhorn/longhorn/issues/5647)) - @DamiaSan
|
|
||||||
- [FEATURE] Introduce a new disk type, disk management and replica scheduler for SPDK volumes ([5683](https://github.com/longhorn/longhorn/issues/5683)) - @derekbit @roger-ryao
|
|
||||||
- [FEATURE] Support replica scheduling for SPDK volume ([5711](https://github.com/longhorn/longhorn/issues/5711)) - @derekbit
|
|
||||||
- [FEATURE] Create SPDK gRPC service for instance manager ([5712](https://github.com/longhorn/longhorn/issues/5712)) - @shuo-wu
|
|
||||||
- [FEATURE] Environment check script for Longhorn with SPDK ([5738](https://github.com/longhorn/longhorn/issues/5738)) - @derekbit @chriscchien
|
|
||||||
- [FEATURE] Deployment manifests for helping install SPDK dependencies, utilities and libraries ([5739](https://github.com/longhorn/longhorn/issues/5739)) - @yangchiu @derekbit
|
|
||||||
- [FEATURE] Implement Disk gRPC Service in Instance Manager for collecting SPDK disk statistics from SPDK gRPC service ([5744](https://github.com/longhorn/longhorn/issues/5744)) - @derekbit @chriscchien
|
|
||||||
- [FEATURE] Support for SPDK RAID1 by setting the minimum number of base_bdevs to 1 ([5758](https://github.com/longhorn/longhorn/issues/5758)) - @yangchiu @DamiaSan
|
|
||||||
- [FEATURE] Add a global setting for enabling and disabling SPDK feature ([5778](https://github.com/longhorn/longhorn/issues/5778)) - @yangchiu @derekbit
|
|
||||||
- [FEATURE] Identify and manage orphaned lvols and raid bdevs if the associated `Volume` resources are not existing ([5827](https://github.com/longhorn/longhorn/issues/5827)) - @yangchiu @derekbit
|
|
||||||
- [FEATURE] Longhorn UI for SPDK feature ([5846](https://github.com/longhorn/longhorn/issues/5846)) - @smallteeths @chriscchien
|
|
||||||
- [FEATURE] UI modification to work with new AD mechanism (Longhorn UI -> Longhorn API) ([6004](https://github.com/longhorn/longhorn/issues/6004)) - @yangchiu @smallteeths
|
|
||||||
- [FEATURE] Replica offline rebuild over SPDK - data engine ([6067](https://github.com/longhorn/longhorn/issues/6067)) - @shuo-wu
|
|
||||||
- [FEATURE] Support automatic offline replica rebuilding of volumes using SPDK data engine ([6071](https://github.com/longhorn/longhorn/issues/6071)) - @yangchiu @derekbit
|
|
||||||
|
|
||||||
## Improvement
|
|
||||||
|
|
||||||
- [IMPROVEMENT] Do not count the failure replica reuse failure caused by the disconnection ([1923](https://github.com/longhorn/longhorn/issues/1923)) - @yangchiu @mantissahz
|
|
||||||
- [IMPROVEMENT] Consider changing the over provisioning default/recommendation to 100% percentage (no over provisioning) ([2694](https://github.com/longhorn/longhorn/issues/2694)) - @c3y1huang @chriscchien
|
|
||||||
- [BUG] StorageClass of pv and pvc of a recovered pv should not always be default. ([3506](https://github.com/longhorn/longhorn/issues/3506)) - @ChanYiLin @smallteeths @roger-ryao
|
|
||||||
- [IMPROVEMENT] Auto-attach volume for K8s CSI snapshot ([3726](https://github.com/longhorn/longhorn/issues/3726)) - @weizhe0422 @PhanLe1010
|
|
||||||
- [IMPROVEMENT] Change Longhorn API to create/delete snapshot CRs instead of calling engine CLI ([3995](https://github.com/longhorn/longhorn/issues/3995)) - @yangchiu @PhanLe1010
|
|
||||||
- [IMPROVEMENT] Add support for crypto parameters for RWX volumes ([4829](https://github.com/longhorn/longhorn/issues/4829)) - @mantissahz @roger-ryao
|
|
||||||
- [IMPROVEMENT] Remove the global setting `mkfs-ext4-parameters` ([4914](https://github.com/longhorn/longhorn/issues/4914)) - @ejweber @roger-ryao
|
|
||||||
- [IMPROVEMENT] Move all snapshot related settings at one place. ([4930](https://github.com/longhorn/longhorn/issues/4930)) - @smallteeths @roger-ryao
|
|
||||||
- [IMPROVEMENT] Remove system managed component image settings ([5028](https://github.com/longhorn/longhorn/issues/5028)) - @mantissahz @chriscchien
|
|
||||||
- [IMPROVEMENT] Set default `engine-replica-timeout` value for engine controller start command ([5031](https://github.com/longhorn/longhorn/issues/5031)) - @derekbit @chriscchien
|
|
||||||
- [IMPROVEMENT] Support bundle collects dmesg, syslog and related information of longhorn nodes ([5073](https://github.com/longhorn/longhorn/issues/5073)) - @weizhe0422 @roger-ryao
|
|
||||||
- [IMPROVEMENT] Collect volume, system, feature info for metrics for better usage awareness ([5235](https://github.com/longhorn/longhorn/issues/5235)) - @c3y1huang @chriscchien @roger-ryao
|
|
||||||
- [IMPROVEMENT] Update uninstallation info to include the 'Deleting Confirmation Flag' in chart ([5250](https://github.com/longhorn/longhorn/issues/5250)) - @PhanLe1010 @roger-ryao
|
|
||||||
- [IMPROVEMENT] Disable Revision Counter for Strict-Local dataLocality ([5257](https://github.com/longhorn/longhorn/issues/5257)) - @derekbit @roger-ryao
|
|
||||||
- [IMPROVEMENT] Fix Guaranteed Engine Manager CPU recommendation formula in UI ([5338](https://github.com/longhorn/longhorn/issues/5338)) - @c3y1huang @smallteeths @roger-ryao
|
|
||||||
- [IMPROVEMENT] Update PSP validation in the Longhorn upstream chart ([5339](https://github.com/longhorn/longhorn/issues/5339)) - @yangchiu @PhanLe1010
|
|
||||||
- [IMPROVEMENT] Update ganesha nfs to 4.2.3 ([5356](https://github.com/longhorn/longhorn/issues/5356)) - @derekbit @roger-ryao
|
|
||||||
- [IMPROVEMENT] Set write-cache of longhorn block device to off explicitly ([5382](https://github.com/longhorn/longhorn/issues/5382)) - @derekbit @chriscchien
|
|
||||||
- [IMPROVEMENT] Clean up unused backupstore mountpoint ([5391](https://github.com/longhorn/longhorn/issues/5391)) - @derekbit @chriscchien
|
|
||||||
- [DOC] Update Kubernetes version info to have consistent description from the longhorn documentation in chart ([5399](https://github.com/longhorn/longhorn/issues/5399)) - @ChanYiLin @roger-ryao
|
|
||||||
- [IMPROVEMENT] Fix BackingImage uploading/downloading flow to prevent client timeout ([5443](https://github.com/longhorn/longhorn/issues/5443)) - @ChanYiLin @chriscchien
|
|
||||||
- [IMPROVEMENT] Assign the pods to the same node where the strict-local volume is present ([5448](https://github.com/longhorn/longhorn/issues/5448)) - @c3y1huang @chriscchien
|
|
||||||
- [IMPROVEMENT] Have explicitly message when trying to attach a volume which it's engine and replica were on deleted node ([5545](https://github.com/longhorn/longhorn/issues/5545)) - @ChanYiLin @chriscchien
|
|
||||||
- [IMPROVEMENT] Create a new setting so that Longhorn removes PDB for instance-manager-r that doesn't have any running instance inside it ([5549](https://github.com/longhorn/longhorn/issues/5549)) - @PhanLe1010 @roger-ryao
|
|
||||||
- [IMPROVEMENT] Merge conversion/admission webhook and recovery backend services into longhorn-manager ([5590](https://github.com/longhorn/longhorn/issues/5590)) - @ChanYiLin @chriscchien
|
|
||||||
- [IMPROVEMENT][UI] Recurring jobs create new snapshots while being not able to clean up old one ([5610](https://github.com/longhorn/longhorn/issues/5610)) - @mantissahz @smallteeths @roger-ryao
|
|
||||||
- [IMPROVEMENT] Only activate replica if it doesn't have deletion timestamp during volume engine upgrade ([5632](https://github.com/longhorn/longhorn/issues/5632)) - @PhanLe1010 @roger-ryao
|
|
||||||
- [IMPROVEMENT] Clean up backup target if the backup target setting is unset ([5655](https://github.com/longhorn/longhorn/issues/5655)) - @yangchiu @ChanYiLin
|
|
||||||
- [IMPROVEMENT] Bump CSI sidecar components' version ([5672](https://github.com/longhorn/longhorn/issues/5672)) - @yangchiu @ejweber
|
|
||||||
- [IMPROVEMENT] Configure log level of Longhorn components ([5888](https://github.com/longhorn/longhorn/issues/5888)) - @ChanYiLin @weizhe0422
|
|
||||||
- [IMPROVEMENT] Remove development toolchain from Longhorn images ([6022](https://github.com/longhorn/longhorn/issues/6022)) - @ChanYiLin @derekbit
|
|
||||||
- [IMPROVEMENT] Reduce replica process's number of allocated ports ([6079](https://github.com/longhorn/longhorn/issues/6079)) - @ChanYiLin @derekbit
|
|
||||||
- [IMPROVEMENT] UI supports automatic replica rebuilding for SPDK volumes ([6107](https://github.com/longhorn/longhorn/issues/6107)) - @smallteeths @roger-ryao
|
|
||||||
- [IMPROVEMENT] Minor UX changes for Longhorn SPDK ([6126](https://github.com/longhorn/longhorn/issues/6126)) - @derekbit @roger-ryao
|
|
||||||
- [IMPROVEMENT] Instance manager spdk_tgt resilience due to spdk_tgt crash ([6155](https://github.com/longhorn/longhorn/issues/6155)) - @yangchiu @derekbit
|
|
||||||
- [IMPROVEMENT] Determine number of replica/engine port count in longhorn-manager (control plane) instead ([6163](https://github.com/longhorn/longhorn/issues/6163)) - @derekbit @chriscchien
|
|
||||||
- [IMPROVEMENT] SPDK client should functions after encountering decoding error ([6191](https://github.com/longhorn/longhorn/issues/6191)) - @yangchiu @shuo-wu
|
|
||||||
|
|
||||||
## Performance
|
|
||||||
|
|
||||||
- [REFACTORING] Evaluate the impact of removing the client side compression for backup blocks ([1409](https://github.com/longhorn/longhorn/issues/1409)) - @derekbit
|
|
||||||
|
|
||||||
## Resilience
|
|
||||||
|
|
||||||
- [BUG] If backing image downloading fails on one node, it doesn't try on other nodes. ([3746](https://github.com/longhorn/longhorn/issues/3746)) - @ChanYiLin
|
|
||||||
- [BUG] Replica rebuilding caused by rke2/kubelet restart ([5340](https://github.com/longhorn/longhorn/issues/5340)) - @derekbit @chriscchien
|
|
||||||
- [BUG] Volume restoration will never complete if attached node is down ([5464](https://github.com/longhorn/longhorn/issues/5464)) - @derekbit @weizhe0422 @chriscchien
|
|
||||||
- [BUG] Node disconnection test failed ([5476](https://github.com/longhorn/longhorn/issues/5476)) - @yangchiu @derekbit
|
|
||||||
- [BUG] Physical node down test failed ([5477](https://github.com/longhorn/longhorn/issues/5477)) - @derekbit @chriscchien
|
|
||||||
- [BUG] Backing image with sync failure ([5481](https://github.com/longhorn/longhorn/issues/5481)) - @ChanYiLin @roger-ryao
|
|
||||||
- [BUG] share-manager pod failed to restart after kubelet restart ([5507](https://github.com/longhorn/longhorn/issues/5507)) - @yangchiu @derekbit
|
|
||||||
- [BUG] Directly mark replica as failed if the node is deleted ([5542](https://github.com/longhorn/longhorn/issues/5542)) - @weizhe0422 @roger-ryao
|
|
||||||
- [BUG] RWX volume is stuck at detaching when the attached node is down ([5558](https://github.com/longhorn/longhorn/issues/5558)) - @derekbit @roger-ryao
|
|
||||||
- [BUG] Unable to export RAID1 bdev in degraded state ([5650](https://github.com/longhorn/longhorn/issues/5650)) - @chriscchien @DamiaSan
|
|
||||||
- [BUG] Backup monitor gets stuck in an infinite loop if backup isn't found ([5662](https://github.com/longhorn/longhorn/issues/5662)) - @derekbit @chriscchien
|
|
||||||
- [BUG] Resources such as replicas are somehow not mutated when network is unstable ([5762](https://github.com/longhorn/longhorn/issues/5762)) - @derekbit @roger-ryao
|
|
||||||
- [BUG] filesystem corrupted after delete instance-manager-r for a locality best-effort volume ([5801](https://github.com/longhorn/longhorn/issues/5801)) - @yangchiu @ChanYiLin @mantissahz
|
|
||||||
|
|
||||||
## Stability
|
|
||||||
|
|
||||||
- [BUG] nfs backup broken - NFS server: mkdir - file exists ([4626](https://github.com/longhorn/longhorn/issues/4626)) - @yangchiu @derekbit
|
|
||||||
- [BUG] Memory leak in CSI plugin caused by stuck umount processes if the RWX volume is already gone ([5296](https://github.com/longhorn/longhorn/issues/5296)) - @derekbit @roger-ryao
|
|
||||||
|
|
||||||
## Bugs
|
|
||||||
|
|
||||||
- [BUG] 'Upgrade Engine' still shows up in a specific situation when engine already upgraded ([3063](https://github.com/longhorn/longhorn/issues/3063)) - @weizhe0422 @PhanLe1010 @smallteeths
|
|
||||||
- [BUG] DR volume even after activation remains in standby mode if there are one or more failed replicas. ([3069](https://github.com/longhorn/longhorn/issues/3069)) - @yangchiu @mantissahz
|
|
||||||
- [BUG] volume not able to attach with raw type backing image ([3437](https://github.com/longhorn/longhorn/issues/3437)) - @yangchiu @ChanYiLin
|
|
||||||
- [BUG] Delete a uploading backing image, the corresponding LH temp file is not deleted ([3682](https://github.com/longhorn/longhorn/issues/3682)) - @ChanYiLin @chriscchien
|
|
||||||
- [BUG] Cloned PVC from detached volume will stuck at not ready for workload ([3692](https://github.com/longhorn/longhorn/issues/3692)) - @PhanLe1010 @chriscchien
|
|
||||||
- [BUG] Block device volume failed to unmount when it is detached unexpectedly ([3778](https://github.com/longhorn/longhorn/issues/3778)) - @PhanLe1010 @chriscchien
|
|
||||||
- [BUG] After migration of Longhorn from Rancher old UI to dashboard, the csi-plugin doesn't update ([4519](https://github.com/longhorn/longhorn/issues/4519)) - @mantissahz @roger-ryao
|
|
||||||
- [BUG] Volumes Stuck in Attach/Detach Loop when running on OpenShift/OKD ([4988](https://github.com/longhorn/longhorn/issues/4988)) - @ChanYiLin
|
|
||||||
- [BUG] Longhorn 1.3.2 fails to backup & restore volumes behind Internet proxy ([5054](https://github.com/longhorn/longhorn/issues/5054)) - @mantissahz @chriscchien
|
|
||||||
- [BUG] Instance manager pod does not respect of node taint? ([5161](https://github.com/longhorn/longhorn/issues/5161)) - @ejweber
|
|
||||||
- [BUG] RWX doesn't work with release 1.4.0 due to end grace update error from recovery backend ([5183](https://github.com/longhorn/longhorn/issues/5183)) - @derekbit @chriscchien
|
|
||||||
- [BUG] Incorrect indentation of charts/questions.yaml ([5196](https://github.com/longhorn/longhorn/issues/5196)) - @mantissahz @roger-ryao
|
|
||||||
- [BUG] Updating option "Allow snapshots removal during trim" for old volumes failed ([5218](https://github.com/longhorn/longhorn/issues/5218)) - @shuo-wu @roger-ryao
|
|
||||||
- [BUG] Since 1.4.0 RWX volume failing regularly ([5224](https://github.com/longhorn/longhorn/issues/5224)) - @derekbit
|
|
||||||
- [BUG] Can not create backup in engine image not fully deployed cluster ([5248](https://github.com/longhorn/longhorn/issues/5248)) - @ChanYiLin @roger-ryao
|
|
||||||
- [BUG] Incorrect router retry mechanism ([5259](https://github.com/longhorn/longhorn/issues/5259)) - @mantissahz @chriscchien
|
|
||||||
- [BUG] System Backup is stuck at Uploading if there are PVs not provisioned by CSI driver ([5286](https://github.com/longhorn/longhorn/issues/5286)) - @c3y1huang @chriscchien
|
|
||||||
- [BUG] Sync up with backup target during DR volume activation ([5292](https://github.com/longhorn/longhorn/issues/5292)) - @yangchiu @weizhe0422
|
|
||||||
- [BUG] environment_check.sh does not handle different kernel versions in cluster correctly ([5304](https://github.com/longhorn/longhorn/issues/5304)) - @achims311 @roger-ryao
|
|
||||||
- [BUG] instance-manager-r high memory consumption ([5312](https://github.com/longhorn/longhorn/issues/5312)) - @derekbit @roger-ryao
|
|
||||||
- [BUG] Unable to upgrade longhorn from v1.3.2 to master-head ([5368](https://github.com/longhorn/longhorn/issues/5368)) - @yangchiu @derekbit
|
|
||||||
- [BUG] Modify engineManagerCPURequest and replicaManagerCPURequest won't raise resource request in instance-manager-e pod ([5419](https://github.com/longhorn/longhorn/issues/5419)) - @c3y1huang
|
|
||||||
- [BUG] Error message not consistent between create/update recurring job when retain number greater than 50 ([5434](https://github.com/longhorn/longhorn/issues/5434)) - @c3y1huang @chriscchien
|
|
||||||
- [BUG] Do not copy Host header to API requests forwarded to Longhorn Manager ([5438](https://github.com/longhorn/longhorn/issues/5438)) - @yangchiu @smallteeths
|
|
||||||
- [BUG] RWX Volume attachment is getting Failed ([5456](https://github.com/longhorn/longhorn/issues/5456)) - @derekbit
|
|
||||||
- [BUG] test case test_backup_lock_deletion_during_restoration failed ([5458](https://github.com/longhorn/longhorn/issues/5458)) - @yangchiu @derekbit
|
|
||||||
- [BUG] Unable to create support bundle agent pod in air-gap environment ([5467](https://github.com/longhorn/longhorn/issues/5467)) - @yangchiu @c3y1huang
|
|
||||||
- [BUG] Example of data migration doesn't work for hidden/./dot-files) ([5484](https://github.com/longhorn/longhorn/issues/5484)) - @hedefalk @shuo-wu @chriscchien
|
|
||||||
- [BUG] Upgrade engine --> spec.restoreVolumeRecurringJob and spec.snapshotDataIntegrity Unsupported value ([5485](https://github.com/longhorn/longhorn/issues/5485)) - @yangchiu @derekbit
|
|
||||||
- [BUG] test case test_dr_volume_with_backup_block_deletion failed ([5489](https://github.com/longhorn/longhorn/issues/5489)) - @yangchiu @derekbit
|
|
||||||
- [BUG] Bulk backup deletion cause restoring volume to finish with attached state. ([5506](https://github.com/longhorn/longhorn/issues/5506)) - @ChanYiLin @roger-ryao
|
|
||||||
- [BUG] volume expansion starts for no reason, gets stuck on current size > expected size ([5513](https://github.com/longhorn/longhorn/issues/5513)) - @mantissahz @roger-ryao
|
|
||||||
- [BUG] RWX volume attachment failed if tried more enough times ([5537](https://github.com/longhorn/longhorn/issues/5537)) - @yangchiu @derekbit
|
|
||||||
- [BUG] instance-manager-e emits `Wait for process pvc-xxxx to shutdown` constantly ([5575](https://github.com/longhorn/longhorn/issues/5575)) - @derekbit @roger-ryao
|
|
||||||
- [BUG] Support bundle kit should respect node selector & taint toleration ([5614](https://github.com/longhorn/longhorn/issues/5614)) - @yangchiu @c3y1huang
|
|
||||||
- [BUG] Value overlapped in page Instance Manager Image ([5622](https://github.com/longhorn/longhorn/issues/5622)) - @smallteeths @chriscchien
|
|
||||||
- [BUG] Updated Rocky 9 (and others) can't attach due to SELinux ([5627](https://github.com/longhorn/longhorn/issues/5627)) - @yangchiu @ejweber
|
|
||||||
- [BUG] Fix misleading error messages when creating a mount point for a backup store ([5630](https://github.com/longhorn/longhorn/issues/5630)) - @derekbit
|
|
||||||
- [BUG] Instance manager PDB created with wrong selector thus blocking the draining of the wrongly selected node forever ([5680](https://github.com/longhorn/longhorn/issues/5680)) - @PhanLe1010 @chriscchien
|
|
||||||
- [BUG] During volume live engine upgrade, if the replica pod is killed, the volume is stuck in upgrading forever ([5684](https://github.com/longhorn/longhorn/issues/5684)) - @yangchiu @PhanLe1010
|
|
||||||
- [BUG] Instance manager PDBs cannot be removed if the longhorn-manager pod on its spec node is not available ([5688](https://github.com/longhorn/longhorn/issues/5688)) - @PhanLe1010 @roger-ryao
|
|
||||||
- [BUG] Rebuild rebuilding is possibly issued to a wrong replica ([5709](https://github.com/longhorn/longhorn/issues/5709)) - @ejweber @roger-ryao
|
|
||||||
- [BUG] Observing repilca on new IM-r before upgrading of volume ([5729](https://github.com/longhorn/longhorn/issues/5729)) - @c3y1huang
|
|
||||||
- [BUG] longhorn upgrade is not upgrading engineimage ([5740](https://github.com/longhorn/longhorn/issues/5740)) - @shuo-wu @chriscchien
|
|
||||||
- [BUG] `test_replica_auto_balance_when_replica_on_unschedulable_node` Error in creating volume with nodeSelector and dataLocality parameters ([5745](https://github.com/longhorn/longhorn/issues/5745)) - @c3y1huang @roger-ryao
|
|
||||||
- [BUG] Unable to backup volume after NFS server IP change ([5856](https://github.com/longhorn/longhorn/issues/5856)) - @derekbit @roger-ryao
|
|
||||||
- [BUG] Prevent Longhorn uninstallation from getting stuck due to backups in error ([5868](https://github.com/longhorn/longhorn/issues/5868)) - @ChanYiLin @mantissahz
|
|
||||||
- [BUG] Unable to create support bundle if the previous one stayed in ReadyForDownload phase ([5882](https://github.com/longhorn/longhorn/issues/5882)) - @c3y1huang @roger-ryao
|
|
||||||
- [BUG] share-manager for a given pvc keep restarting (other pvc are working fine) ([5954](https://github.com/longhorn/longhorn/issues/5954)) - @yangchiu @derekbit
|
|
||||||
- [BUG] Replica auto-rebalance doesn't respect node selector ([5971](https://github.com/longhorn/longhorn/issues/5971)) - @c3y1huang @roger-ryao
|
|
||||||
- [BUG] Volume detached automatically after upgrade Longhorn ([5983](https://github.com/longhorn/longhorn/issues/5983)) - @yangchiu @PhanLe1010
|
|
||||||
- [BUG] Extra snapshot generated when clone from a detached volume ([5986](https://github.com/longhorn/longhorn/issues/5986)) - @weizhe0422 @ejweber
|
|
||||||
- [BUG] User created snapshot deleted after node drain and uncordon ([5992](https://github.com/longhorn/longhorn/issues/5992)) - @yangchiu @mantissahz
|
|
||||||
- [BUG] Webhook PDBs are not removed after upgrading to master-head ([6026](https://github.com/longhorn/longhorn/issues/6026)) - @weizhe0422 @PhanLe1010
|
|
||||||
- [BUG] In some specific situation, system backup auto deleted when creating another one ([6045](https://github.com/longhorn/longhorn/issues/6045)) - @c3y1huang @chriscchien
|
|
||||||
- [BUG] Backing Image deletion stuck if it's deleted during uploading process and bids is ready-for-transfer state ([6086](https://github.com/longhorn/longhorn/issues/6086)) - @WebberHuang1118 @chriscchien
|
|
||||||
- [BUG] A backup target backed by a Samba server is not recognized ([6100](https://github.com/longhorn/longhorn/issues/6100)) - @derekbit @weizhe0422
|
|
||||||
- [BUG] Backing image manager fails when SELinux is enabled ([6108](https://github.com/longhorn/longhorn/issues/6108)) - @ejweber @chriscchien
|
|
||||||
- [BUG] Force delete volume make SPDK disk unschedule ([6110](https://github.com/longhorn/longhorn/issues/6110)) - @derekbit
|
|
||||||
- [BUG] share-manager terminated during Longhorn upgrading causes rwx volume not working ([6120](https://github.com/longhorn/longhorn/issues/6120)) - @yangchiu @derekbit
|
|
||||||
- [BUG] SPDK Volume snapshotList API Error ([6123](https://github.com/longhorn/longhorn/issues/6123)) - @derekbit @chriscchien
|
|
||||||
- [BUG] test_recurring_jobs_allow_detached_volume failed ([6124](https://github.com/longhorn/longhorn/issues/6124)) - @ChanYiLin @roger-ryao
|
|
||||||
- [BUG] Cron job triggered replica rebuilding keeps repeating itself after corrupting snapshot data ([6129](https://github.com/longhorn/longhorn/issues/6129)) - @yangchiu @mantissahz
|
|
||||||
- [BUG] test_dr_volume_with_restore_command_error failed ([6130](https://github.com/longhorn/longhorn/issues/6130)) - @mantissahz @roger-ryao
|
|
||||||
- [BUG] RWX volume remains attached after workload deleted if it's upgraded from v1.4.2 ([6139](https://github.com/longhorn/longhorn/issues/6139)) - @PhanLe1010 @chriscchien
|
|
||||||
- [BUG] timestamp or checksum not matched in test_snapshot_hash_detect_corruption test case ([6145](https://github.com/longhorn/longhorn/issues/6145)) - @yangchiu @derekbit
|
|
||||||
- [BUG] When a v2 volume is attached in maintenance mode, removing a replica will lead to volume stuck in attaching-detaching loop ([6166](https://github.com/longhorn/longhorn/issues/6166)) - @derekbit @chriscchien
|
|
||||||
- [BUG] Misleading offline rebuilding hint if offline rebuilding is not enabled ([6169](https://github.com/longhorn/longhorn/issues/6169)) - @smallteeths @roger-ryao
|
|
||||||
- [BUG] Longhorn doesn't remove the system backups crd on uninstallation ([6185](https://github.com/longhorn/longhorn/issues/6185)) - @c3y1huang @khushboo-rancher
|
|
||||||
- [BUG] Volume attachment related error logs in uninstaller pod ([6197](https://github.com/longhorn/longhorn/issues/6197)) - @yangchiu @PhanLe1010
|
|
||||||
- [BUG] Test case test_ha_backup_deletion_recovery failed in rhel or rockylinux arm64 environment ([6213](https://github.com/longhorn/longhorn/issues/6213)) - @yangchiu @ChanYiLin @mantissahz
|
|
||||||
- [BUG] migration test cases could fail due to unexpected volume controllers and replicas status ([6215](https://github.com/longhorn/longhorn/issues/6215)) - @yangchiu @PhanLe1010
|
|
||||||
- [BUG] Engine continues to attempt to rebuild replica while detaching ([6217](https://github.com/longhorn/longhorn/issues/6217)) - @yangchiu @ejweber
|
|
||||||
|
|
||||||
## Misc
|
|
||||||
|
|
||||||
- [TASK] Remove deprecated volume spec recurringJobs and storageClass recurringJobs field ([2865](https://github.com/longhorn/longhorn/issues/2865)) - @c3y1huang @chriscchien
|
|
||||||
- [TASK] Remove deprecated fields after CRD API version bump ([3289](https://github.com/longhorn/longhorn/issues/3289)) - @c3y1huang @roger-ryao
|
|
||||||
- [TASK] Replace jobq lib with an alternative way for listing remote backup volumes and info ([4176](https://github.com/longhorn/longhorn/issues/4176)) - @ChanYiLin @chriscchien
|
|
||||||
- [DOC] Update the Longhorn document in Uninstalling Longhorn using kubectl ([4841](https://github.com/longhorn/longhorn/issues/4841)) - @roger-ryao
|
|
||||||
- [TASK] Remove a deprecated feature `disable-replica-rebuild` from longhorn-manager ([4997](https://github.com/longhorn/longhorn/issues/4997)) - @ejweber @chriscchien
|
|
||||||
- [TASK] Update the distro matrix supports on Longhorn docs for 1.5 ([5177](https://github.com/longhorn/longhorn/issues/5177)) - @yangchiu
|
|
||||||
- [TASK] Clarify if any upcoming K8s API deprecation/removal will impact Longhorn 1.4 ([5180](https://github.com/longhorn/longhorn/issues/5180)) - @PhanLe1010
|
|
||||||
- [TASK] Revert affinity for Longhorn user deployed components ([5191](https://github.com/longhorn/longhorn/issues/5191)) - @weizhe0422 @ejweber
|
|
||||||
- [TASK] Add GitHub action for CI to lib repos for supporting dependency bot ([5239](https://github.com/longhorn/longhorn/issues/5239)) -
|
|
||||||
- [DOC] Update the readme of longhorn-spdk-engine about using new Longhorn (RAID1) bdev ([5256](https://github.com/longhorn/longhorn/issues/5256)) - @DamiaSan
|
|
||||||
- [TASK][UI] add new recurring job tasks ([5272](https://github.com/longhorn/longhorn/issues/5272)) - @smallteeths @chriscchien
|
|
||||||
- [DOC] Update the node maintenance doc to cover upgrade prerequisites for Rancher ([5278](https://github.com/longhorn/longhorn/issues/5278)) - @PhanLe1010
|
|
||||||
- [TASK] Run build-engine-test-images automatically when having incompatible engine on master ([5400](https://github.com/longhorn/longhorn/issues/5400)) - @yangchiu
|
|
||||||
- [TASK] Update k8s.gcr.io to registry.k8s.io in repos ([5432](https://github.com/longhorn/longhorn/issues/5432)) - @yangchiu
|
|
||||||
- [TASK][UI] add new recurring job task - filesystem trim ([5529](https://github.com/longhorn/longhorn/issues/5529)) - @smallteeths @chriscchien
|
|
||||||
- doc: update prerequisites in chart readme to make it consistent with documentation v1.3.x ([5531](https://github.com/longhorn/longhorn/pull/5531)) - @ChanYiLin
|
|
||||||
- [FEATURE] Remove deprecated `allow-node-drain-with-last-healthy-replica` ([5620](https://github.com/longhorn/longhorn/issues/5620)) - @weizhe0422 @PhanLe1010
|
|
||||||
- [FEATURE] Set recurring jobs to PVCs ([5791](https://github.com/longhorn/longhorn/issues/5791)) - @yangchiu @c3y1huang
|
|
||||||
- [TASK] Automatically update crds.yaml in longhorn repo from longhorn-manager repo ([5854](https://github.com/longhorn/longhorn/issues/5854)) - @yangchiu
|
|
||||||
- [IMPROVEMENT] Remove privilege requirement from lifecycle jobs ([5862](https://github.com/longhorn/longhorn/issues/5862)) - @mantissahz @chriscchien
|
|
||||||
- [TASK][UI] support new aio typed instance managers ([5876](https://github.com/longhorn/longhorn/issues/5876)) - @smallteeths @chriscchien
|
|
||||||
- [TASK] Remove `Guaranteed Engine Manager CPU`, `Guaranteed Replica Manager CPU`, and `Guaranteed Engine CPU` settings. ([5917](https://github.com/longhorn/longhorn/issues/5917)) - @c3y1huang @roger-ryao
|
|
||||||
- [TASK][UI] Support volume backup policy ([6028](https://github.com/longhorn/longhorn/issues/6028)) - @smallteeths @chriscchien
|
|
||||||
- [TASK] Reduce BackupConcurrentLimit and RestoreConcurrentLimit default values ([6135](https://github.com/longhorn/longhorn/issues/6135)) - @derekbit @chriscchien
|
|
||||||
|
|
||||||
## Contributors
|
|
||||||
|
|
||||||
- @ChanYiLin
|
|
||||||
- @DamiaSan
|
|
||||||
- @PhanLe1010
|
|
||||||
- @WebberHuang1118
|
|
||||||
- @achims311
|
|
||||||
- @c3y1huang
|
|
||||||
- @chriscchien
|
|
||||||
- @derekbit
|
|
||||||
- @ejweber
|
|
||||||
- @hedefalk
|
|
||||||
- @innobead
|
|
||||||
- @khushboo-rancher
|
|
||||||
- @mantissahz
|
|
||||||
- @roger-ryao
|
|
||||||
- @shuo-wu
|
|
||||||
- @smallteeths
|
|
||||||
- @weizhe0422
|
|
||||||
- @yangchiu
|
|
||||||
@ -1,65 +0,0 @@
|
|||||||
## Release Note
|
|
||||||
### **v1.5.1 released!** 🎆
|
|
||||||
|
|
||||||
Longhorn v1.5.1 is the latest version of Longhorn 1.5.
|
|
||||||
This release introduces bug fixes as described below about 1.5.0 upgrade issues, stability, troubleshooting and so on. Please try it and feedback. Thanks for all the contributions!
|
|
||||||
|
|
||||||
> For the definition of stable or latest release, please check [here](https://github.com/longhorn/longhorn#releases).
|
|
||||||
|
|
||||||
## Installation
|
|
||||||
|
|
||||||
> **Please ensure your Kubernetes cluster is at least v1.21 before installing v1.5.1.**
|
|
||||||
|
|
||||||
Longhorn supports 3 installation ways including Rancher App Marketplace, Kubectl, and Helm. Follow the installation instructions [here](https://longhorn.io/docs/1.5.1/deploy/install/).
|
|
||||||
|
|
||||||
## Upgrade
|
|
||||||
|
|
||||||
> **Please read the [important notes](https://longhorn.io/docs/1.5.1/deploy/important-notes/) first and ensure your Kubernetes cluster is at least v1.21 before upgrading to Longhorn v1.5.1 from v1.4.x/v1.5.0, which are only supported source versions.**
|
|
||||||
|
|
||||||
Follow the upgrade instructions [here](https://longhorn.io/docs/1.5.1/deploy/upgrade/).
|
|
||||||
|
|
||||||
## Deprecation & Incompatibilities
|
|
||||||
|
|
||||||
N/A
|
|
||||||
|
|
||||||
## Known Issues after Release
|
|
||||||
|
|
||||||
Please follow up on [here](https://github.com/longhorn/longhorn/wiki/Outstanding-Known-Issues-of-Releases) about any outstanding issues found after this release.
|
|
||||||
|
|
||||||
## Improvement
|
|
||||||
|
|
||||||
- [IMPROVEMENT] Implement/fix the unit tests of Volume Attachment and volume controller ([6005](https://github.com/longhorn/longhorn/issues/6005)) - @PhanLe1010
|
|
||||||
- [QUESTION] Repetitive warnings and errors in a new longhorn setup ([6257](https://github.com/longhorn/longhorn/issues/6257)) - @derekbit @c3y1huang @roger-ryao
|
|
||||||
|
|
||||||
## Resilience
|
|
||||||
|
|
||||||
- [BUG] 1.5.0 Upgrade: Longhorn conversion webhook server fails ([6259](https://github.com/longhorn/longhorn/issues/6259)) - @derekbit @roger-ryao
|
|
||||||
- [BUG] Race leaves snapshot CRs that cannot be deleted ([6298](https://github.com/longhorn/longhorn/issues/6298)) - @yangchiu @PhanLe1010 @ejweber
|
|
||||||
|
|
||||||
## Bugs
|
|
||||||
|
|
||||||
- [BUG] Engine continues to attempt to rebuild replica while detaching ([6217](https://github.com/longhorn/longhorn/issues/6217)) - @yangchiu @ejweber
|
|
||||||
- [BUG] Upgrade to 1.5.0 failed: validator.longhorn.io denied the request if having orphan resources ([6246](https://github.com/longhorn/longhorn/issues/6246)) - @derekbit @roger-ryao
|
|
||||||
- [BUG] Unable to receive support bundle from UI when it's large (400MB+) ([6256](https://github.com/longhorn/longhorn/issues/6256)) - @c3y1huang @chriscchien
|
|
||||||
- [BUG] Longhorn Manager Pods CrashLoop after upgrade from 1.4.0 to 1.5.0 while backing up volumes ([6264](https://github.com/longhorn/longhorn/issues/6264)) - @ChanYiLin @roger-ryao
|
|
||||||
- [BUG] Can not delete type=`bi` VolumeSnapshot if related backing image not exist ([6266](https://github.com/longhorn/longhorn/issues/6266)) - @ChanYiLin @chriscchien
|
|
||||||
- [BUG] 1.5.0: AttachVolume.Attach failed for volume, the volume is currently attached to a different node ([6287](https://github.com/longhorn/longhorn/issues/6287)) - @yangchiu @derekbit
|
|
||||||
- [BUG] test case test_setting_priority_class failed in master and v1.5.x ([6319](https://github.com/longhorn/longhorn/issues/6319)) - @derekbit @chriscchien
|
|
||||||
- [BUG] Unused webhook and recovery backend deployment left in helm chart ([6252](https://github.com/longhorn/longhorn/issues/6252)) - @ChanYiLin @chriscchien
|
|
||||||
|
|
||||||
## Misc
|
|
||||||
|
|
||||||
- [DOC] v1.5.0 additional outgoing firewall ports need to be opened 9501 9502 9503 ([6317](https://github.com/longhorn/longhorn/issues/6317)) - @ChanYiLin @chriscchien
|
|
||||||
|
|
||||||
## Contributors
|
|
||||||
|
|
||||||
- @ChanYiLin
|
|
||||||
- @PhanLe1010
|
|
||||||
- @c3y1huang
|
|
||||||
- @chriscchien
|
|
||||||
- @derekbit
|
|
||||||
- @ejweber
|
|
||||||
- @innobead
|
|
||||||
- @roger-ryao
|
|
||||||
- @yangchiu
|
|
||||||
|
|
||||||
@ -1,8 +1,5 @@
|
|||||||
The list of current Longhorn maintainers:
|
The list of current Longhorn maintainers:
|
||||||
|
|
||||||
Name, <Email>, @GitHubHandle
|
Name, <Email>, @GitHubHandle
|
||||||
Sheng Yang, <sheng@yasker.org>, @yasker
|
Sheng Yang, <sheng.yang@rancher.com>, @yasker
|
||||||
Shuo Wu, <shuo.wu@suse.com>, @shuo-wu
|
Shuo Wu, <shuo@rancher.com>, @shuo-wu
|
||||||
David Ko, <dko@suse.com>, @innobead
|
|
||||||
Derek Su, <derek.su@suse.com>, @derekbit
|
|
||||||
Phan Le, <phan.le@suse.com>, @PhanLe1010
|
|
||||||
|
|||||||
168
README.md
168
README.md
@ -1,20 +1,17 @@
|
|||||||
<h1 align="center" style="border-bottom: none">
|
# Longhorn
|
||||||
<a href="https://longhorn.io/" target="_blank"><img alt="Longhorn" width="120px" src="https://github.com/longhorn/website/blob/master/static/img/icon-longhorn.svg"></a><br>Longhorn
|
|
||||||
</h1>
|
|
||||||
|
|
||||||
<p align="center">A CNCF Incubating Project. Visit <a href="https://longhorn.io/" target="_blank">longhorn.io</a> for the full documentation.</p>
|
### Build Status
|
||||||
|
* Engine: [](https://drone-publish.longhorn.io/longhorn/longhorn-engine) [](https://goreportcard.com/report/github.com/longhorn/longhorn-engine)
|
||||||
|
* Manager: [](https://drone-publish.longhorn.io/longhorn/longhorn-manager)[](https://goreportcard.com/report/github.com/longhorn/longhorn-manager)
|
||||||
|
* Instance Manager: [](http://drone-publish.longhorn.io/longhorn/longhorn-instance-manager)[](https://goreportcard.com/report/github.com/longhorn/longhorn-instance-manager)
|
||||||
|
* Share Manager: [](http://drone-publish.longhorn.io/longhorn/longhorn-share-manager)[](https://goreportcard.com/report/github.com/longhorn/longhorn-share-manager)
|
||||||
|
* UI: [](https://drone-publish.longhorn.io/longhorn/longhorn-ui)
|
||||||
|
* Test: [](http://drone-publish.longhorn.io/longhorn/longhorn-tests)
|
||||||
|
|
||||||
<div align="center">
|
### Overview
|
||||||
|
Longhorn is a distributed block storage system for Kubernetes. Longhorn is cloud native storage because it is built using Kubernetes and container primatives.
|
||||||
|
|
||||||
[](https://github.com/longhorn/longhorn/releases)
|
Longhorn is lightweight, reliable, and powerful. You can install Longhorn on an existing Kubernetes cluster with one `kubectl apply` command or using Helm charts. Once Longhorn is installed, it adds persistent volume support to the Kubernetes cluster.
|
||||||
[](https://github.com/longhorn/longhorn/blob/master/LICENSE)
|
|
||||||
[](https://longhorn.io/docs/latest/)
|
|
||||||
|
|
||||||
</div>
|
|
||||||
|
|
||||||
Longhorn is a distributed block storage system for Kubernetes. Longhorn is cloud-native storage built using Kubernetes and container primitives.
|
|
||||||
|
|
||||||
Longhorn is lightweight, reliable, and powerful. You can install Longhorn on an existing Kubernetes cluster with one `kubectl apply`command or by using Helm charts. Once Longhorn is installed, it adds persistent volume support to the Kubernetes cluster.
|
|
||||||
|
|
||||||
Longhorn implements distributed block storage using containers and microservices. Longhorn creates a dedicated storage controller for each block device volume and synchronously replicates the volume across multiple replicas stored on multiple nodes. The storage controller and replicas are themselves orchestrated using Kubernetes. Here are some notable features of Longhorn:
|
Longhorn implements distributed block storage using containers and microservices. Longhorn creates a dedicated storage controller for each block device volume and synchronously replicates the volume across multiple replicas stored on multiple nodes. The storage controller and replicas are themselves orchestrated using Kubernetes. Here are some notable features of Longhorn:
|
||||||
|
|
||||||
@ -27,111 +24,50 @@ Longhorn implements distributed block storage using containers and microservices
|
|||||||
|
|
||||||
You can read more technical details of Longhorn [here](https://longhorn.io/).
|
You can read more technical details of Longhorn [here](https://longhorn.io/).
|
||||||
|
|
||||||
# Releases
|
|
||||||
|
|
||||||
> **NOTE**:
|
## Get Involved
|
||||||
> - __\<version\>*__ means the release branch is under active support and will have periodic follow-up patch releases.
|
**Community Meeting and Office Hours**!: Hosted by the core maintainers of Longhorn: 2nd Friday of the every month at 09:00 Pacific Time (PT)/12:00 Eastern Time (ET) on Zoom: http://bit.ly/longhorn-community-meeting. Gcal event: http://bit.ly/longhorn-events
|
||||||
> - __Latest__ release means the version is the latest release of the newest release branch.
|
**Longhorn Mailing List**!: Stay up to date on the latest news and events: https://lists.cncf.io/g/cncf-longhorn
|
||||||
> - __Stable__ release means the version is stable and has been widely adopted by users.
|
|
||||||
|
|
||||||
https://github.com/longhorn/longhorn/releases
|
|
||||||
|
|
||||||
| Release | Version | Type | Release Note (Changelog) | Important Note |
|
|
||||||
|-----------|---------|----------------|----------------------------------------------------------------|-------------------------------------------------------------|
|
|
||||||
| **1.5*** | 1.5.1 | Latest | [🔗](https://github.com/longhorn/longhorn/releases/tag/v1.5.1) | [🔗](https://longhorn.io/docs/1.5.1/deploy/important-notes) |
|
|
||||||
| **1.4*** | 1.4.4 | Stable | [🔗](https://github.com/longhorn/longhorn/releases/tag/v1.4.4) | [🔗](https://longhorn.io/docs/1.4.4/deploy/important-notes) |
|
|
||||||
| 1.3 | 1.3.3 | Stable | [🔗](https://github.com/longhorn/longhorn/releases/tag/v1.3.3) | [🔗](https://longhorn.io/docs/1.3.3/deploy/important-notes) |
|
|
||||||
| 1.2 | 1.2.6 | Stable | [🔗](https://github.com/longhorn/longhorn/releases/tag/v1.2.6) | [🔗](https://longhorn.io/docs/1.2.6/deploy/important-notes) |
|
|
||||||
| 1.1 | 1.1.3 | Stable | [🔗](https://github.com/longhorn/longhorn/releases/tag/v1.1.3) | |
|
|
||||||
|
|
||||||
# Roadmap
|
|
||||||
|
|
||||||
https://github.com/longhorn/longhorn/wiki/Roadmap
|
|
||||||
|
|
||||||
# Components
|
|
||||||
|
|
||||||
Longhorn is 100% open source software. Project source code is spread across a number of repos:
|
|
||||||
|
|
||||||
* Engine: [](https://drone-publish.longhorn.io/longhorn/longhorn-engine)[](https://goreportcard.com/report/github.com/longhorn/longhorn-engine)[](https://app.fossa.com/projects/custom%2B25850%2Fgithub.com%2Flonghorn%2Flonghorn-engine?ref=badge_shield)
|
|
||||||
* Manager: [](https://drone-publish.longhorn.io/longhorn/longhorn-manager)[](https://goreportcard.com/report/github.com/longhorn/longhorn-manager)[](https://app.fossa.com/projects/custom%2B25850%2Fgithub.com%2Flonghorn%2Flonghorn-manager?ref=badge_shield)
|
|
||||||
* Instance Manager: [](http://drone-publish.longhorn.io/longhorn/longhorn-instance-manager)[](https://goreportcard.com/report/github.com/longhorn/longhorn-instance-manager)[](https://app.fossa.com/projects/custom%2B25850%2Fgithub.com%2Flonghorn%2Flonghorn-instance-manager?ref=badge_shield)
|
|
||||||
* Share Manager: [](http://drone-publish.longhorn.io/longhorn/longhorn-share-manager)[](https://goreportcard.com/report/github.com/longhorn/longhorn-share-manager)[](https://app.fossa.com/projects/custom%2B25850%2Fgithub.com%2Flonghorn%2Flonghorn-share-manager?ref=badge_shield)
|
|
||||||
* Backing Image Manager: [](http://drone-publish.longhorn.io/longhorn/backing-image-manager)[](https://goreportcard.com/report/github.com/longhorn/backing-image-manager)[](https://app.fossa.com/projects/custom%2B25850%2Fgithub.com%2Flonghorn%2Fbacking-image-manager?ref=badge_shield)
|
|
||||||
* UI: [](https://drone-publish.longhorn.io/longhorn/longhorn-ui)[](https://app.fossa.com/projects/custom%2B25850%2Fgithub.com%2Flonghorn%2Flonghorn-ui?ref=badge_shield)
|
|
||||||
|
|
||||||
| Component | What it does | GitHub repo |
|
|
||||||
| :----------------------------- | :--------------------------------------------------------------------- | :------------------------------------------------------------------------------------------ |
|
|
||||||
| Longhorn Backing Image Manager | Backing image download, sync, and deletion in a disk | [longhorn/backing-image-manager](https://github.com/longhorn/backing-image-manager) |
|
|
||||||
| Longhorn Engine | Core controller/replica logic | [longhorn/longhorn-engine](https://github.com/longhorn/longhorn-engine) |
|
|
||||||
| Longhorn Instance Manager | Controller/replica instance lifecycle management | [longhorn/longhorn-instance-manager](https://github.com/longhorn/longhorn-instance-manager) |
|
|
||||||
| Longhorn Manager | Longhorn orchestration, includes CSI driver for Kubernetes | [longhorn/longhorn-manager](https://github.com/longhorn/longhorn-manager) |
|
|
||||||
| Longhorn Share Manager | NFS provisioner that exposes Longhorn volumes as ReadWriteMany volumes | [longhorn/longhorn-share-manager](https://github.com/longhorn/longhorn-share-manager) |
|
|
||||||
| Longhorn UI | The Longhorn dashboard | [longhorn/longhorn-ui](https://github.com/longhorn/longhorn-ui) |
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
# Get Started
|
|
||||||
|
|
||||||
## Requirements
|
|
||||||
|
|
||||||
For the installation requirements, refer to the [Longhorn documentation.](https://longhorn.io/docs/latest/deploy/install/#installation-requirements)
|
|
||||||
|
|
||||||
## Installation
|
|
||||||
|
|
||||||
> **NOTE**:
|
|
||||||
> Please note that the master branch is for the upcoming feature release development.
|
|
||||||
> For an official release installation or upgrade, please refer to the below ways.
|
|
||||||
|
|
||||||
Longhorn can be installed on a Kubernetes cluster in several ways:
|
|
||||||
|
|
||||||
- [Rancher App Marketplace](https://longhorn.io/docs/latest/deploy/install/install-with-rancher/)
|
|
||||||
- [kubectl](https://longhorn.io/docs/latest/deploy/install/install-with-kubectl/)
|
|
||||||
- [Helm](https://longhorn.io/docs/latest/deploy/install/install-with-helm/)
|
|
||||||
|
|
||||||
## Documentation
|
|
||||||
|
|
||||||
The official Longhorn documentation is [here.](https://longhorn.io/docs)
|
|
||||||
|
|
||||||
# Get Involved
|
|
||||||
|
|
||||||
## Discussion, Feedback
|
|
||||||
|
|
||||||
If having any discussions or feedbacks, feel free to [file a discussion](https://github.com/longhorn/longhorn/discussions).
|
|
||||||
|
|
||||||
## Features Request, Bug Reporting
|
|
||||||
|
|
||||||
If having any issues, feel free to [file an issue](https://github.com/longhorn/longhorn/issues/new/choose).
|
|
||||||
We have a weekly community issue review meeting to review all reported issues or enhancement requests.
|
|
||||||
|
|
||||||
When creating a bug issue, please help upload the support bundle to the issue or send to
|
|
||||||
[longhorn-support-bundle](mailto:longhorn-support-bundle@suse.com).
|
|
||||||
|
|
||||||
## Report Vulnerabilities
|
|
||||||
|
|
||||||
If having any vulnerabilities found, please report to [longhorn-security](mailto:longhorn-security@suse.com).
|
|
||||||
|
|
||||||
# Community
|
|
||||||
|
|
||||||
Longhorn is open source software, so contributions are greatly welcome.
|
|
||||||
Please read [Code of Conduct](./CODE_OF_CONDUCT.md) and [Contributing Guideline](./CONTRIBUTING.md) before contributing.
|
|
||||||
|
|
||||||
Contributing code is not the only way of contributing. We value feedbacks very much and many of the Longhorn features are originated from users' feedback.
|
|
||||||
If you have any feedbacks, feel free to [file an issue](https://github.com/longhorn/longhorn/issues/new/choose) and talk to the developers at the [CNCF](https://slack.cncf.io/) [#longhorn](https://cloud-native.slack.com/messages/longhorn) Slack channel.
|
|
||||||
|
|
||||||
If having any discussion, feedbacks, requests, issues or security reports, please follow below ways.
|
|
||||||
We also have a [CNCF Slack channel: longhorn](https://cloud-native.slack.com/messages/longhorn) for discussion.
|
|
||||||
|
|
||||||
## Community Meeting and Office Hours
|
|
||||||
Hosted by the core maintainers of Longhorn: 4th Friday of the every month at 09:00 (CET) or 16:00 (CST) at https://community.cncf.io/longhorn-community/.
|
|
||||||
|
|
||||||
## Longhorn Mailing List
|
|
||||||
Stay up to date on the latest news and events: https://lists.cncf.io/g/cncf-longhorn
|
|
||||||
|
|
||||||
You can read more about the community and its events here: https://github.com/longhorn/community
|
You can read more about the community and its events here: https://github.com/longhorn/community
|
||||||
|
|
||||||
# License
|
## Current status
|
||||||
|
|
||||||
Copyright (c) 2014-2022 The Longhorn Authors
|
The latest release of Longhorn is **v1.1.0**.
|
||||||
|
|
||||||
|
## Source code
|
||||||
|
Longhorn is 100% open source software. Project source code is spread across a number of repos:
|
||||||
|
|
||||||
|
1. Longhorn engine -- Core controller/replica logic https://github.com/longhorn/longhorn-engine
|
||||||
|
1. Longhorn manager -- Longhorn orchestration https://github.com/longhorn/longhorn-manager
|
||||||
|
1. Longhorn UI -- Dashboard https://github.com/longhorn/longhorn-ui
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
# Requirements
|
||||||
|
|
||||||
|
For the installation requirements, refer to the [Longhorn documentation.](https://longhorn.io/docs/install/requirements)
|
||||||
|
|
||||||
|
# Install
|
||||||
|
|
||||||
|
Longhorn can be installed on a Kubernetes cluster in several ways:
|
||||||
|
|
||||||
|
- [kubectl](https://longhorn.io/docs/install/install-with-kubectl/)
|
||||||
|
- [Helm](https://longhorn.io/docs/install/install-with-helm/)
|
||||||
|
- [Rancher catalog app](https://longhorn.io/docs/install/install-with-rancher/)
|
||||||
|
|
||||||
|
# Documentation
|
||||||
|
|
||||||
|
The official Longhorn documentation is [here.](https://longhorn.io/docs)
|
||||||
|
|
||||||
|
## Community
|
||||||
|
Longhorn is open source software, so contributions are greatly welcome. Please read [Code of Conduct](./CODE_OF_CONDUCT.md) and [Contributing Guideline](./CONTRIBUTING.md) before contributing.
|
||||||
|
|
||||||
|
Contributing code is not the only way of contributing. We value feedbacks very much and many of the Longhorn features are originated from users' feedback. If you have any feedbacks, feel free to [file an issue](https://github.com/longhorn/longhorn/issues/new?title=*Summarize%20your%20issue%20here*&body=*Describe%20your%20issue%20here*%0A%0A---%0AVersion%3A%20``) and talk to the developers at the [CNCF](https://slack.cncf.io/) [#longhorn](https://cloud-native.slack.com/messages/longhorn) slack channel.
|
||||||
|
|
||||||
|
## License
|
||||||
|
|
||||||
|
Copyright (c) 2014-2020 The Longhorn Authors
|
||||||
|
|
||||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
|
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
|
||||||
|
|
||||||
@ -139,6 +75,6 @@ Licensed under the Apache License, Version 2.0 (the "License"); you may not use
|
|||||||
|
|
||||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
|
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
|
||||||
|
|
||||||
## Longhorn is a [CNCF Incubating Project](https://www.cncf.io/projects/)
|
### Longhorn is a [CNCF Sandbox Project](https://www.cncf.io/sandbox-projects/)
|
||||||
|
|
||||||

|

|
||||||
|
|||||||
@ -1,8 +1,8 @@
|
|||||||
apiVersion: v1
|
apiVersion: v1
|
||||||
name: longhorn
|
name: longhorn
|
||||||
version: 1.6.0-dev
|
version: 1.1.0
|
||||||
appVersion: v1.6.0-dev
|
appVersion: v1.1.0
|
||||||
kubeVersion: ">=1.21.0-0"
|
kubeVersion: ">=v1.16.0-r0"
|
||||||
description: Longhorn is a distributed block storage system for Kubernetes.
|
description: Longhorn is a distributed block storage system for Kubernetes.
|
||||||
keywords:
|
keywords:
|
||||||
- longhorn
|
- longhorn
|
||||||
@ -11,7 +11,6 @@ keywords:
|
|||||||
- block
|
- block
|
||||||
- device
|
- device
|
||||||
- iscsi
|
- iscsi
|
||||||
- nfs
|
|
||||||
home: https://github.com/longhorn/longhorn
|
home: https://github.com/longhorn/longhorn
|
||||||
sources:
|
sources:
|
||||||
- https://github.com/longhorn/longhorn
|
- https://github.com/longhorn/longhorn
|
||||||
@ -21,8 +20,9 @@ sources:
|
|||||||
- https://github.com/longhorn/longhorn-manager
|
- https://github.com/longhorn/longhorn-manager
|
||||||
- https://github.com/longhorn/longhorn-ui
|
- https://github.com/longhorn/longhorn-ui
|
||||||
- https://github.com/longhorn/longhorn-tests
|
- https://github.com/longhorn/longhorn-tests
|
||||||
- https://github.com/longhorn/backing-image-manager
|
|
||||||
maintainers:
|
maintainers:
|
||||||
- name: Longhorn maintainers
|
- name: Longhorn maintainers
|
||||||
email: maintainers@longhorn.io
|
email: maintainers@longhorn.io
|
||||||
icon: https://raw.githubusercontent.com/cncf/artwork/master/projects/longhorn/icon/color/longhorn-icon-color.png
|
- name: Sheng Yang
|
||||||
|
email: sheng@yasker.org
|
||||||
|
icon: https://raw.githubusercontent.com/cncf/artwork/master/projects/longhorn/icon/color/longhorn-icon-color.svg?sanitize=true
|
||||||
|
|||||||
277
chart/README.md
277
chart/README.md
@ -11,30 +11,15 @@ Longhorn is 100% open source software. Project source code is spread across a nu
|
|||||||
1. Longhorn Engine -- Core controller/replica logic https://github.com/longhorn/longhorn-engine
|
1. Longhorn Engine -- Core controller/replica logic https://github.com/longhorn/longhorn-engine
|
||||||
2. Longhorn Instance Manager -- Controller/replica instance lifecycle management https://github.com/longhorn/longhorn-instance-manager
|
2. Longhorn Instance Manager -- Controller/replica instance lifecycle management https://github.com/longhorn/longhorn-instance-manager
|
||||||
3. Longhorn Share Manager -- NFS provisioner that exposes Longhorn volumes as ReadWriteMany volumes. https://github.com/longhorn/longhorn-share-manager
|
3. Longhorn Share Manager -- NFS provisioner that exposes Longhorn volumes as ReadWriteMany volumes. https://github.com/longhorn/longhorn-share-manager
|
||||||
4. Backing Image Manager -- Backing image file lifecycle management. https://github.com/longhorn/backing-image-manager
|
4. Longhorn Manager -- Longhorn orchestration, includes CSI driver for Kubernetes https://github.com/longhorn/longhorn-manager
|
||||||
5. Longhorn Manager -- Longhorn orchestration, includes CSI driver for Kubernetes https://github.com/longhorn/longhorn-manager
|
4. Longhorn UI -- Dashboard https://github.com/longhorn/longhorn-ui
|
||||||
6. Longhorn UI -- Dashboard https://github.com/longhorn/longhorn-ui
|
|
||||||
|
|
||||||
## Prerequisites
|
## Prerequisites
|
||||||
|
|
||||||
1. A container runtime compatible with Kubernetes (Docker v1.13+, containerd v1.3.7+, etc.)
|
1. Docker v1.13+
|
||||||
2. Kubernetes >= v1.21
|
2. Kubernetes v1.16+
|
||||||
3. Make sure `bash`, `curl`, `findmnt`, `grep`, `awk` and `blkid` has been installed in all nodes of the Kubernetes cluster.
|
3. Make sure `curl`, `findmnt`, `grep`, `awk` and `blkid` has been installed in all nodes of the Kubernetes cluster.
|
||||||
4. Make sure `open-iscsi` has been installed, and the `iscsid` daemon is running on all nodes of the Kubernetes cluster. For GKE, recommended Ubuntu as guest OS image since it contains `open-iscsi` already.
|
4. Make sure `open-iscsi` has been installed in all nodes of the Kubernetes cluster. For GKE, recommended Ubuntu as guest OS image since it contains `open-iscsi` already.
|
||||||
|
|
||||||
## Upgrading to Kubernetes v1.25+
|
|
||||||
|
|
||||||
Starting in Kubernetes v1.25, [Pod Security Policies](https://kubernetes.io/docs/concepts/security/pod-security-policy/) have been removed from the Kubernetes API.
|
|
||||||
|
|
||||||
As a result, **before upgrading to Kubernetes v1.25** (or on a fresh install in a Kubernetes v1.25+ cluster), users are expected to perform an in-place upgrade of this chart with `enablePSP` set to `false` if it has been previously set to `true`.
|
|
||||||
|
|
||||||
> **Note:**
|
|
||||||
> If you upgrade your cluster to Kubernetes v1.25+ before removing PSPs via a `helm upgrade` (even if you manually clean up resources), **it will leave the Helm release in a broken state within the cluster such that further Helm operations will not work (`helm uninstall`, `helm upgrade`, etc.).**
|
|
||||||
>
|
|
||||||
> If your charts get stuck in this state, you may have to clean up your Helm release secrets.
|
|
||||||
Upon setting `enablePSP` to false, the chart will remove any PSP resources deployed on its behalf from the cluster. This is the default setting for this chart.
|
|
||||||
|
|
||||||
As a replacement for PSPs, [Pod Security Admission](https://kubernetes.io/docs/concepts/security/pod-security-admission/) should be used. Please consult the Longhorn docs for more details on how to configure your chart release namespaces to work with the new Pod Security Admission and apply Pod Security Standards.
|
|
||||||
|
|
||||||
## Installation
|
## Installation
|
||||||
1. Add Longhorn chart repository.
|
1. Add Longhorn chart repository.
|
||||||
@ -63,264 +48,14 @@ helm install longhorn longhorn/longhorn --namespace longhorn-system
|
|||||||
|
|
||||||
With Helm 2 to uninstall Longhorn.
|
With Helm 2 to uninstall Longhorn.
|
||||||
```
|
```
|
||||||
kubectl -n longhorn-system patch -p '{"value": "true"}' --type=merge lhs deleting-confirmation-flag
|
|
||||||
helm delete longhorn --purge
|
helm delete longhorn --purge
|
||||||
```
|
```
|
||||||
|
|
||||||
With Helm 3 to uninstall Longhorn.
|
With Helm 3 to uninstall Longhorn.
|
||||||
```
|
```
|
||||||
kubectl -n longhorn-system patch -p '{"value": "true"}' --type=merge lhs deleting-confirmation-flag
|
|
||||||
helm uninstall longhorn -n longhorn-system
|
helm uninstall longhorn -n longhorn-system
|
||||||
kubectl delete namespace longhorn-system
|
kubectl delete namespace longhorn-system
|
||||||
```
|
```
|
||||||
|
|
||||||
## Values
|
|
||||||
|
|
||||||
The `values.yaml` contains items used to tweak a deployment of this chart.
|
|
||||||
|
|
||||||
### Cattle Settings
|
|
||||||
|
|
||||||
| Key | Type | Default | Description |
|
|
||||||
|-----|------|---------|-------------|
|
|
||||||
| global.cattle.systemDefaultRegistry | string | `""` | System default registry |
|
|
||||||
| global.cattle.windowsCluster.defaultSetting.systemManagedComponentsNodeSelector | string | `"kubernetes.io/os:linux"` | Node selector for Longhorn system managed components |
|
|
||||||
| global.cattle.windowsCluster.defaultSetting.taintToleration | string | `"cattle.io/os=linux:NoSchedule"` | Toleration for Longhorn system managed components |
|
|
||||||
| global.cattle.windowsCluster.enabled | bool | `false` | Enable this to allow Longhorn to run on the Rancher deployed Windows cluster |
|
|
||||||
| global.cattle.windowsCluster.nodeSelector | object | `{"kubernetes.io/os":"linux"}` | Select Linux nodes to run Longhorn user deployed components |
|
|
||||||
| global.cattle.windowsCluster.tolerations | list | `[{"effect":"NoSchedule","key":"cattle.io/os","operator":"Equal","value":"linux"}]` | Tolerate Linux nodes to run Longhorn user deployed components |
|
|
||||||
|
|
||||||
### Network Policies
|
|
||||||
|
|
||||||
| Key | Type | Default | Description |
|
|
||||||
|-----|------|---------|-------------|
|
|
||||||
| networkPolicies.enabled | bool | `false` | Enable NetworkPolicies to limit access to the Longhorn pods |
|
|
||||||
| networkPolicies.type | string | `"k3s"` | Create the policy based on your distribution to allow access for the ingress. Options: `k3s`, `rke2`, `rke1` |
|
|
||||||
|
|
||||||
### Image Settings
|
|
||||||
|
|
||||||
| Key | Type | Default | Description |
|
|
||||||
|-----|------|---------|-------------|
|
|
||||||
| image.csi.attacher.repository | string | `"longhornio/csi-attacher"` | Specify CSI attacher image repository. Leave blank to autodetect |
|
|
||||||
| image.csi.attacher.tag | string | `"v4.2.0"` | Specify CSI attacher image tag. Leave blank to autodetect |
|
|
||||||
| image.csi.livenessProbe.repository | string | `"longhornio/livenessprobe"` | Specify CSI liveness probe image repository. Leave blank to autodetect |
|
|
||||||
| image.csi.livenessProbe.tag | string | `"v2.9.0"` | Specify CSI liveness probe image tag. Leave blank to autodetect |
|
|
||||||
| image.csi.nodeDriverRegistrar.repository | string | `"longhornio/csi-node-driver-registrar"` | Specify CSI node driver registrar image repository. Leave blank to autodetect |
|
|
||||||
| image.csi.nodeDriverRegistrar.tag | string | `"v2.7.0"` | Specify CSI node driver registrar image tag. Leave blank to autodetect |
|
|
||||||
| image.csi.provisioner.repository | string | `"longhornio/csi-provisioner"` | Specify CSI provisioner image repository. Leave blank to autodetect |
|
|
||||||
| image.csi.provisioner.tag | string | `"v3.4.1"` | Specify CSI provisioner image tag. Leave blank to autodetect |
|
|
||||||
| image.csi.resizer.repository | string | `"longhornio/csi-resizer"` | Specify CSI driver resizer image repository. Leave blank to autodetect |
|
|
||||||
| image.csi.resizer.tag | string | `"v1.7.0"` | Specify CSI driver resizer image tag. Leave blank to autodetect |
|
|
||||||
| image.csi.snapshotter.repository | string | `"longhornio/csi-snapshotter"` | Specify CSI driver snapshotter image repository. Leave blank to autodetect |
|
|
||||||
| image.csi.snapshotter.tag | string | `"v6.2.1"` | Specify CSI driver snapshotter image tag. Leave blank to autodetect. |
|
|
||||||
| image.longhorn.backingImageManager.repository | string | `"longhornio/backing-image-manager"` | Specify Longhorn backing image manager image repository |
|
|
||||||
| image.longhorn.backingImageManager.tag | string | `"master-head"` | Specify Longhorn backing image manager image tag |
|
|
||||||
| image.longhorn.engine.repository | string | `"longhornio/longhorn-engine"` | Specify Longhorn engine image repository |
|
|
||||||
| image.longhorn.engine.tag | string | `"master-head"` | Specify Longhorn engine image tag |
|
|
||||||
| image.longhorn.instanceManager.repository | string | `"longhornio/longhorn-instance-manager"` | Specify Longhorn instance manager image repository |
|
|
||||||
| image.longhorn.instanceManager.tag | string | `"master-head"` | Specify Longhorn instance manager image tag |
|
|
||||||
| image.longhorn.manager.repository | string | `"longhornio/longhorn-manager"` | Specify Longhorn manager image repository |
|
|
||||||
| image.longhorn.manager.tag | string | `"master-head"` | Specify Longhorn manager image tag |
|
|
||||||
| image.longhorn.shareManager.repository | string | `"longhornio/longhorn-share-manager"` | Specify Longhorn share manager image repository |
|
|
||||||
| image.longhorn.shareManager.tag | string | `"master-head"` | Specify Longhorn share manager image tag |
|
|
||||||
| image.longhorn.supportBundleKit.repository | string | `"longhornio/support-bundle-kit"` | Specify Longhorn support bundle manager image repository |
|
|
||||||
| image.longhorn.supportBundleKit.tag | string | `"v0.0.27"` | Specify Longhorn support bundle manager image tag |
|
|
||||||
| image.longhorn.ui.repository | string | `"longhornio/longhorn-ui"` | Specify Longhorn ui image repository |
|
|
||||||
| image.longhorn.ui.tag | string | `"master-head"` | Specify Longhorn ui image tag |
|
|
||||||
| image.openshift.oauthProxy.repository | string | `"quay.io/openshift/origin-oauth-proxy"` | For openshift user. Specify oauth proxy image repository |
|
|
||||||
| image.openshift.oauthProxy.tag | float | `4.13` | For openshift user. Specify oauth proxy image tag. Note: Use your OCP/OKD 4.X Version, Current Stable is 4.13 |
|
|
||||||
| image.pullPolicy | string | `"IfNotPresent"` | Image pull policy which applies to all user deployed Longhorn Components. e.g, Longhorn manager, Longhorn driver, Longhorn UI |
|
|
||||||
|
|
||||||
### Service Settings
|
|
||||||
|
|
||||||
| Key | Description |
|
|
||||||
|-----|-------------|
|
|
||||||
| service.manager.nodePort | NodePort port number (to set explicitly, choose port between 30000-32767) |
|
|
||||||
| service.manager.type | Define Longhorn manager service type. |
|
|
||||||
| service.ui.nodePort | NodePort port number (to set explicitly, choose port between 30000-32767) |
|
|
||||||
| service.ui.type | Define Longhorn UI service type. Options: `ClusterIP`, `NodePort`, `LoadBalancer`, `Rancher-Proxy` |
|
|
||||||
|
|
||||||
### StorageClass Settings
|
|
||||||
|
|
||||||
| Key | Type | Default | Description |
|
|
||||||
|-----|------|---------|-------------|
|
|
||||||
| persistence.backingImage.dataSourceParameters | string | `nil` | Specify the data source parameters for the backing image used in Longhorn StorageClass. This option accepts a json string of a map. e.g., `'{\"url\":\"https://backing-image-example.s3-region.amazonaws.com/test-backing-image\"}'`. |
|
|
||||||
| persistence.backingImage.dataSourceType | string | `nil` | Specify the data source type for the backing image used in Longhorn StorageClass. If the backing image does not exists, Longhorn will use this field to create a backing image. Otherwise, Longhorn will use it to verify the selected backing image. |
|
|
||||||
| persistence.backingImage.enable | bool | `false` | Set backing image for Longhorn StorageClass |
|
|
||||||
| persistence.backingImage.expectedChecksum | string | `nil` | Specify the expected SHA512 checksum of the selected backing image in Longhorn StorageClass |
|
|
||||||
| persistence.backingImage.name | string | `nil` | Specify a backing image that will be used by Longhorn volumes in Longhorn StorageClass. If not exists, the backing image data source type and backing image data source parameters should be specified so that Longhorn will create the backing image before using it |
|
|
||||||
| persistence.defaultClass | bool | `true` | Set Longhorn StorageClass as default |
|
|
||||||
| persistence.defaultClassReplicaCount | int | `3` | Set replica count for Longhorn StorageClass |
|
|
||||||
| persistence.defaultDataLocality | string | `"disabled"` | Set data locality for Longhorn StorageClass. Options: `disabled`, `best-effort` |
|
|
||||||
| persistence.defaultFsType | string | `"ext4"` | Set filesystem type for Longhorn StorageClass |
|
|
||||||
| persistence.defaultMkfsParams | string | `""` | Set mkfs options for Longhorn StorageClass |
|
|
||||||
| persistence.defaultNodeSelector.enable | bool | `false` | Enable Node selector for Longhorn StorageClass |
|
|
||||||
| persistence.defaultNodeSelector.selector | string | `""` | This selector enables only certain nodes having these tags to be used for the volume. e.g. `"storage,fast"` |
|
|
||||||
| persistence.migratable | bool | `false` | Set volume migratable for Longhorn StorageClass |
|
|
||||||
| persistence.reclaimPolicy | string | `"Delete"` | Define reclaim policy. Options: `Retain`, `Delete` |
|
|
||||||
| persistence.recurringJobSelector.enable | bool | `false` | Enable recurring job selector for Longhorn StorageClass |
|
|
||||||
| persistence.recurringJobSelector.jobList | list | `[]` | Recurring job selector list for Longhorn StorageClass. Please be careful of quotes of input. e.g., `[{"name":"backup", "isGroup":true}]` |
|
|
||||||
| persistence.removeSnapshotsDuringFilesystemTrim | string | `"ignored"` | Allow automatically removing snapshots during filesystem trim for Longhorn StorageClass. Options: `ignored`, `enabled`, `disabled` |
|
|
||||||
|
|
||||||
### CSI Settings
|
|
||||||
|
|
||||||
| Key | Description |
|
|
||||||
|-----|-------------|
|
|
||||||
| csi.attacherReplicaCount | Specify replica count of CSI Attacher. Leave blank to use default count: 3 |
|
|
||||||
| csi.kubeletRootDir | Specify kubelet root-dir. Leave blank to autodetect |
|
|
||||||
| csi.provisionerReplicaCount | Specify replica count of CSI Provisioner. Leave blank to use default count: 3 |
|
|
||||||
| csi.resizerReplicaCount | Specify replica count of CSI Resizer. Leave blank to use default count: 3 |
|
|
||||||
| csi.snapshotterReplicaCount | Specify replica count of CSI Snapshotter. Leave blank to use default count: 3 |
|
|
||||||
|
|
||||||
### Longhorn Manager Settings
|
|
||||||
|
|
||||||
Longhorn system contains user deployed components (e.g, Longhorn manager, Longhorn driver, Longhorn UI) and system managed components (e.g, instance manager, engine image, CSI driver, etc.).
|
|
||||||
These settings only apply to Longhorn manager component.
|
|
||||||
|
|
||||||
| Key | Type | Default | Description |
|
|
||||||
|-----|------|---------|-------------|
|
|
||||||
| longhornManager.log.format | string | `"plain"` | Options: `plain`, `json` |
|
|
||||||
| longhornManager.nodeSelector | object | `{}` | Select nodes to run Longhorn manager |
|
|
||||||
| longhornManager.priorityClass | string | `nil` | Priority class for longhorn manager |
|
|
||||||
| longhornManager.serviceAnnotations | object | `{}` | Annotation used in Longhorn manager service |
|
|
||||||
| longhornManager.tolerations | list | `[]` | Tolerate nodes to run Longhorn manager |
|
|
||||||
|
|
||||||
### Longhorn Driver Settings
|
|
||||||
|
|
||||||
Longhorn system contains user deployed components (e.g, Longhorn manager, Longhorn driver, Longhorn UI) and system managed components (e.g, instance manager, engine image, CSI driver, etc.).
|
|
||||||
These settings only apply to Longhorn driver component.
|
|
||||||
|
|
||||||
| Key | Type | Default | Description |
|
|
||||||
|-----|------|---------|-------------|
|
|
||||||
| longhornDriver.nodeSelector | object | `{}` | Select nodes to run Longhorn driver |
|
|
||||||
| longhornDriver.priorityClass | string | `nil` | Priority class for longhorn driver |
|
|
||||||
| longhornDriver.tolerations | list | `[]` | Tolerate nodes to run Longhorn driver |
|
|
||||||
|
|
||||||
### Longhorn UI Settings
|
|
||||||
|
|
||||||
Longhorn system contains user deployed components (e.g, Longhorn manager, Longhorn driver, Longhorn UI) and system managed components (e.g, instance manager, engine image, CSI driver, etc.).
|
|
||||||
These settings only apply to Longhorn UI component.
|
|
||||||
|
|
||||||
| Key | Type | Default | Description |
|
|
||||||
|-----|------|---------|-------------|
|
|
||||||
| longhornUI.nodeSelector | object | `{}` | Select nodes to run Longhorn UI |
|
|
||||||
| longhornUI.priorityClass | string | `nil` | Priority class count for longhorn ui |
|
|
||||||
| longhornUI.replicas | int | `2` | Replica count for longhorn ui |
|
|
||||||
| longhornUI.tolerations | list | `[]` | Tolerate nodes to run Longhorn UI |
|
|
||||||
|
|
||||||
### Ingress Settings
|
|
||||||
|
|
||||||
| Key | Type | Default | Description |
|
|
||||||
|-----|------|---------|-------------|
|
|
||||||
| ingress.annotations | string | `nil` | Ingress annotations done as key:value pairs |
|
|
||||||
| ingress.enabled | bool | `false` | Set to true to enable ingress record generation |
|
|
||||||
| ingress.host | string | `"sslip.io"` | Layer 7 Load Balancer hostname |
|
|
||||||
| ingress.ingressClassName | string | `nil` | Add ingressClassName to the Ingress Can replace the kubernetes.io/ingress.class annotation on v1.18+ |
|
|
||||||
| ingress.path | string | `"/"` | If ingress is enabled you can set the default ingress path then you can access the UI by using the following full path {{host}}+{{path}} |
|
|
||||||
| ingress.secrets | string | `nil` | If you're providing your own certificates, please use this to add the certificates as secrets |
|
|
||||||
| ingress.secureBackends | bool | `false` | Enable this in order to enable that the backend service will be connected at port 443 |
|
|
||||||
| ingress.tls | bool | `false` | Set this to true in order to enable TLS on the ingress record |
|
|
||||||
| ingress.tlsSecret | string | `"longhorn.local-tls"` | If TLS is set to true, you must declare what secret will store the key/certificate for TLS |
|
|
||||||
|
|
||||||
### Private Registry Settings
|
|
||||||
|
|
||||||
Longhorn can be installed in an air gapped environment with private registry settings. Please refer to **Air Gap Installation** in our official site [link](https://longhorn.io/docs)
|
|
||||||
|
|
||||||
| Key | Description |
|
|
||||||
|-----|-------------|
|
|
||||||
| privateRegistry.createSecret | Set `true` to create a new private registry secret |
|
|
||||||
| privateRegistry.registryPasswd | Password used to authenticate to private registry |
|
|
||||||
| privateRegistry.registrySecret | If create a new private registry secret is true, create a Kubernetes secret with this name; else use the existing secret of this name. Use it to pull images from your private registry |
|
|
||||||
| privateRegistry.registryUrl | URL of private registry. Leave blank to apply system default registry |
|
|
||||||
| privateRegistry.registryUser | User used to authenticate to private registry |
|
|
||||||
|
|
||||||
### OS/Kubernetes Distro Settings
|
|
||||||
|
|
||||||
#### Opensift Settings
|
|
||||||
|
|
||||||
Please also refer to this document [ocp-readme](https://github.com/longhorn/longhorn/blob/master/chart/ocp-readme.md) for more details
|
|
||||||
|
|
||||||
| Key | Type | Default | Description |
|
|
||||||
|-----|------|---------|-------------|
|
|
||||||
| openshift.enabled | bool | `false` | Enable when using openshift |
|
|
||||||
| openshift.ui.port | int | `443` | UI port in openshift environment |
|
|
||||||
| openshift.ui.proxy | int | `8443` | UI proxy in openshift environment |
|
|
||||||
| openshift.ui.route | string | `"longhorn-ui"` | UI route in openshift environment |
|
|
||||||
|
|
||||||
### Other Settings
|
|
||||||
|
|
||||||
| Key | Default | Description |
|
|
||||||
|-----|---------|-------------|
|
|
||||||
| annotations | `{}` | Annotations to add to the Longhorn Manager DaemonSet Pods. Optional. |
|
|
||||||
| enablePSP | `false` | For Kubernetes < v1.25, if your cluster enables Pod Security Policy admission controller, set this to `true` to ship longhorn-psp which allow privileged Longhorn pods to start |
|
|
||||||
|
|
||||||
### System Default Settings
|
|
||||||
|
|
||||||
For system default settings, you can first leave blank to use default values which will be applied when installing Longhorn.
|
|
||||||
You can then change them through UI after installation.
|
|
||||||
For more details like types or options, you can refer to **Settings Reference** in our official site [link](https://longhorn.io/docs)
|
|
||||||
|
|
||||||
| Key | Description |
|
|
||||||
|-----|-------------|
|
|
||||||
| defaultSettings.allowEmptyDiskSelectorVolume | Allow Scheduling Empty Disk Selector Volumes To Any Disk |
|
|
||||||
| defaultSettings.allowEmptyNodeSelectorVolume | Allow Scheduling Empty Node Selector Volumes To Any Node |
|
|
||||||
| defaultSettings.allowRecurringJobWhileVolumeDetached | If this setting is enabled, Longhorn will automatically attaches the volume and takes snapshot/backup when it is the time to do recurring snapshot/backup. |
|
|
||||||
| defaultSettings.allowVolumeCreationWithDegradedAvailability | This setting allows user to create and attach a volume that doesn't have all the replicas scheduled at the time of creation. |
|
|
||||||
| defaultSettings.autoCleanupSystemGeneratedSnapshot | This setting enables Longhorn to automatically cleanup the system generated snapshot after replica rebuild is done. |
|
|
||||||
| defaultSettings.autoDeletePodWhenVolumeDetachedUnexpectedly | If enabled, Longhorn will automatically delete the workload pod that is managed by a controller (e.g. deployment, statefulset, daemonset, etc...) when Longhorn volume is detached unexpectedly (e.g. during Kubernetes upgrade, Docker reboot, or network disconnect). By deleting the pod, its controller restarts the pod and Kubernetes handles volume reattachment and remount. |
|
|
||||||
| defaultSettings.autoSalvage | If enabled, volumes will be automatically salvaged when all the replicas become faulty e.g. due to network disconnection. Longhorn will try to figure out which replica(s) are usable, then use them for the volume. By default true. |
|
|
||||||
| defaultSettings.backingImageCleanupWaitInterval | This interval in minutes determines how long Longhorn will wait before cleaning up the backing image file when there is no replica in the disk using it. |
|
|
||||||
| defaultSettings.backingImageRecoveryWaitInterval | This interval in seconds determines how long Longhorn will wait before re-downloading the backing image file when all disk files of this backing image become failed or unknown. |
|
|
||||||
| defaultSettings.backupCompressionMethod | This setting allows users to specify backup compression method. |
|
|
||||||
| defaultSettings.backupConcurrentLimit | This setting controls how many worker threads per backup concurrently. |
|
|
||||||
| defaultSettings.backupTarget | The endpoint used to access the backupstore. Available: NFS, CIFS, AWS, GCP, AZURE. |
|
|
||||||
| defaultSettings.backupTargetCredentialSecret | The name of the Kubernetes secret associated with the backup target. |
|
|
||||||
| defaultSettings.backupstorePollInterval | In seconds. The backupstore poll interval determines how often Longhorn checks the backupstore for new backups. Set to 0 to disable the polling. By default 300. |
|
|
||||||
| defaultSettings.concurrentAutomaticEngineUpgradePerNodeLimit | This setting controls how Longhorn automatically upgrades volumes' engines to the new default engine image after upgrading Longhorn manager. The value of this setting specifies the maximum number of engines per node that are allowed to upgrade to the default engine image at the same time. If the value is 0, Longhorn will not automatically upgrade volumes' engines to default version. |
|
|
||||||
| defaultSettings.concurrentReplicaRebuildPerNodeLimit | This setting controls how many replicas on a node can be rebuilt simultaneously. |
|
|
||||||
| defaultSettings.concurrentVolumeBackupRestorePerNodeLimit | This setting controls how many volumes on a node can restore the backup concurrently. Set the value to **0** to disable backup restore. |
|
|
||||||
| defaultSettings.createDefaultDiskLabeledNodes | Create default Disk automatically only on Nodes with the label "node.longhorn.io/create-default-disk=true" if no other disks exist. If disabled, the default disk will be created on all new nodes when each node is first added. |
|
|
||||||
| defaultSettings.defaultDataLocality | Longhorn volume has data locality if there is a local replica of the volume on the same node as the pod which is using the volume. |
|
|
||||||
| defaultSettings.defaultDataPath | Default path to use for storing data on a host. By default "/var/lib/longhorn/" |
|
|
||||||
| defaultSettings.defaultLonghornStaticStorageClass | The 'storageClassName' is given to PVs and PVCs that are created for an existing Longhorn volume. The StorageClass name can also be used as a label, so it is possible to use a Longhorn StorageClass to bind a workload to an existing PV without creating a Kubernetes StorageClass object. By default 'longhorn-static'. |
|
|
||||||
| defaultSettings.defaultReplicaCount | The default number of replicas when a volume is created from the Longhorn UI. For Kubernetes configuration, update the `numberOfReplicas` in the StorageClass. By default 3. |
|
|
||||||
| defaultSettings.deletingConfirmationFlag | This flag is designed to prevent Longhorn from being accidentally uninstalled which will lead to data lost. |
|
|
||||||
| defaultSettings.disableRevisionCounter | This setting is only for volumes created by UI. By default, this is false meaning there will be a reivision counter file to track every write to the volume. During salvage recovering Longhorn will pick the replica with largest reivision counter as candidate to recover the whole volume. If revision counter is disabled, Longhorn will not track every write to the volume. During the salvage recovering, Longhorn will use the 'volume-head-xxx.img' file last modification time and file size to pick the replica candidate to recover the whole volume. |
|
|
||||||
| defaultSettings.disableSchedulingOnCordonedNode | Disable Longhorn manager to schedule replica on Kubernetes cordoned node. By default true. |
|
|
||||||
| defaultSettings.engineReplicaTimeout | In seconds. The setting specifies the timeout between the engine and replica(s), and the value should be between 8 to 30 seconds. The default value is 8 seconds. |
|
|
||||||
| defaultSettings.failedBackupTTL | In minutes. This setting determines how long Longhorn will keep the backup resource that was failed. Set to 0 to disable the auto-deletion. |
|
|
||||||
| defaultSettings.fastReplicaRebuildEnabled | This feature supports the fast replica rebuilding. It relies on the checksum of snapshot disk files, so setting the snapshot-data-integrity to **enable** or **fast-check** is a prerequisite. |
|
|
||||||
| defaultSettings.guaranteedInstanceManagerCPU | This integer value indicates how many percentage of the total allocatable CPU on each node will be reserved for each instance manager Pod. You can leave it with the default value, which is 12%. |
|
|
||||||
| defaultSettings.kubernetesClusterAutoscalerEnabled | Enabling this setting will notify Longhorn that the cluster is using Kubernetes Cluster Autoscaler. |
|
|
||||||
| defaultSettings.logLevel | The log level Panic, Fatal, Error, Warn, Info, Debug, Trace used in longhorn manager. Default to Info. |
|
|
||||||
| defaultSettings.nodeDownPodDeletionPolicy | Defines the Longhorn action when a Volume is stuck with a StatefulSet/Deployment Pod on a node that is down. |
|
|
||||||
| defaultSettings.nodeDrainPolicy | Define the policy to use when a node with the last healthy replica of a volume is drained. |
|
|
||||||
| defaultSettings.offlineReplicaRebuilding | This setting allows users to enable the offline replica rebuilding for volumes using v2 data engine. |
|
|
||||||
| defaultSettings.orphanAutoDeletion | This setting allows Longhorn to delete the orphan resource and its corresponding orphaned data automatically like stale replicas. Orphan resources on down or unknown nodes will not be cleaned up automatically. |
|
|
||||||
| defaultSettings.priorityClass | priorityClass for longhorn system componentss |
|
|
||||||
| defaultSettings.recurringFailedJobsHistoryLimit | This setting specifies how many failed backup or snapshot job histories should be retained. History will not be retained if the value is 0. |
|
|
||||||
| defaultSettings.recurringSuccessfulJobsHistoryLimit | This setting specifies how many successful backup or snapshot job histories should be retained. History will not be retained if the value is 0. |
|
|
||||||
| defaultSettings.removeSnapshotsDuringFilesystemTrim | This setting allows Longhorn filesystem trim feature to automatically mark the latest snapshot and its ancestors as removed and stops at the snapshot containing multiple children. |
|
|
||||||
| defaultSettings.replicaAutoBalance | Enable this setting automatically rebalances replicas when discovered an available node. |
|
|
||||||
| defaultSettings.replicaDiskSoftAntiAffinity | Allow scheduling on disks with existing healthy replicas of the same volume. By default true. |
|
|
||||||
| defaultSettings.replicaFileSyncHttpClientTimeout | In seconds. The setting specifies the HTTP client timeout to the file sync server. |
|
|
||||||
| defaultSettings.replicaReplenishmentWaitInterval | In seconds. The interval determines how long Longhorn will wait at least in order to reuse the existing data on a failed replica rather than directly creating a new replica for a degraded volume. |
|
|
||||||
| defaultSettings.replicaSoftAntiAffinity | Allow scheduling on nodes with existing healthy replicas of the same volume. By default false. |
|
|
||||||
| defaultSettings.replicaZoneSoftAntiAffinity | Allow scheduling new Replicas of Volume to the Nodes in the same Zone as existing healthy Replicas. Nodes don't belong to any Zone will be treated as in the same Zone. Notice that Longhorn relies on label `topology.kubernetes.io/zone=<Zone name of the node>` in the Kubernetes node object to identify the zone. By default true. |
|
|
||||||
| defaultSettings.restoreConcurrentLimit | This setting controls how many worker threads per restore concurrently. |
|
|
||||||
| defaultSettings.restoreVolumeRecurringJobs | Restore recurring jobs from the backup volume on the backup target and create recurring jobs if not exist during a backup restoration. |
|
|
||||||
| defaultSettings.snapshotDataIntegrity | This setting allows users to enable or disable snapshot hashing and data integrity checking. |
|
|
||||||
| defaultSettings.snapshotDataIntegrityCronjob | Unix-cron string format. The setting specifies when Longhorn checks the data integrity of snapshot disk files. |
|
|
||||||
| defaultSettings.snapshotDataIntegrityImmediateCheckAfterSnapshotCreation | Hashing snapshot disk files impacts the performance of the system. The immediate snapshot hashing and checking can be disabled to minimize the impact after creating a snapshot. |
|
|
||||||
| defaultSettings.storageMinimalAvailablePercentage | If the minimum available disk capacity exceeds the actual percentage of available disk capacity, the disk becomes unschedulable until more space is freed up. By default 25. |
|
|
||||||
| defaultSettings.storageNetwork | Longhorn uses the storage network for in-cluster data traffic. Leave this blank to use the Kubernetes cluster network. |
|
|
||||||
| defaultSettings.storageOverProvisioningPercentage | The over-provisioning percentage defines how much storage can be allocated relative to the hard drive's capacity. By default 200. |
|
|
||||||
| defaultSettings.storageReservedPercentageForDefaultDisk | The reserved percentage specifies the percentage of disk space that will not be allocated to the default disk on each new Longhorn node. |
|
|
||||||
| defaultSettings.supportBundleFailedHistoryLimit | This setting specifies how many failed support bundles can exist in the cluster. Set this value to **0** to have Longhorn automatically purge all failed support bundles. |
|
|
||||||
| defaultSettings.systemManagedComponentsNodeSelector | nodeSelector for longhorn system components |
|
|
||||||
| defaultSettings.systemManagedPodsImagePullPolicy | This setting defines the Image Pull Policy of Longhorn system managed pod. e.g. instance manager, engine image, CSI driver, etc. The new Image Pull Policy will only apply after the system managed pods restart. |
|
|
||||||
| defaultSettings.taintToleration | taintToleration for longhorn system components |
|
|
||||||
| defaultSettings.upgradeChecker | Upgrade Checker will check for new Longhorn version periodically. When there is a new version available, a notification will appear in the UI. By default true. |
|
|
||||||
| defaultSettings.v2DataEngine | This allows users to activate v2 data engine based on SPDK. Currently, it is in the preview phase and should not be utilized in a production environment. |
|
|
||||||
|
|
||||||
---
|
---
|
||||||
Please see [link](https://github.com/longhorn/longhorn) for more information.
|
Please see [link](https://github.com/longhorn/longhorn) for more information.
|
||||||
|
|||||||
@ -1,253 +0,0 @@
|
|||||||
# Longhorn Chart
|
|
||||||
|
|
||||||
> **Important**: Please install the Longhorn chart in the `longhorn-system` namespace only.
|
|
||||||
|
|
||||||
> **Warning**: Longhorn doesn't support downgrading from a higher version to a lower version.
|
|
||||||
|
|
||||||
## Source Code
|
|
||||||
|
|
||||||
Longhorn is 100% open source software. Project source code is spread across a number of repos:
|
|
||||||
|
|
||||||
1. Longhorn Engine -- Core controller/replica logic https://github.com/longhorn/longhorn-engine
|
|
||||||
2. Longhorn Instance Manager -- Controller/replica instance lifecycle management https://github.com/longhorn/longhorn-instance-manager
|
|
||||||
3. Longhorn Share Manager -- NFS provisioner that exposes Longhorn volumes as ReadWriteMany volumes. https://github.com/longhorn/longhorn-share-manager
|
|
||||||
4. Backing Image Manager -- Backing image file lifecycle management. https://github.com/longhorn/backing-image-manager
|
|
||||||
5. Longhorn Manager -- Longhorn orchestration, includes CSI driver for Kubernetes https://github.com/longhorn/longhorn-manager
|
|
||||||
6. Longhorn UI -- Dashboard https://github.com/longhorn/longhorn-ui
|
|
||||||
|
|
||||||
## Prerequisites
|
|
||||||
|
|
||||||
1. A container runtime compatible with Kubernetes (Docker v1.13+, containerd v1.3.7+, etc.)
|
|
||||||
2. Kubernetes >= v1.21
|
|
||||||
3. Make sure `bash`, `curl`, `findmnt`, `grep`, `awk` and `blkid` has been installed in all nodes of the Kubernetes cluster.
|
|
||||||
4. Make sure `open-iscsi` has been installed, and the `iscsid` daemon is running on all nodes of the Kubernetes cluster. For GKE, recommended Ubuntu as guest OS image since it contains `open-iscsi` already.
|
|
||||||
|
|
||||||
## Upgrading to Kubernetes v1.25+
|
|
||||||
|
|
||||||
Starting in Kubernetes v1.25, [Pod Security Policies](https://kubernetes.io/docs/concepts/security/pod-security-policy/) have been removed from the Kubernetes API.
|
|
||||||
|
|
||||||
As a result, **before upgrading to Kubernetes v1.25** (or on a fresh install in a Kubernetes v1.25+ cluster), users are expected to perform an in-place upgrade of this chart with `enablePSP` set to `false` if it has been previously set to `true`.
|
|
||||||
|
|
||||||
> **Note:**
|
|
||||||
> If you upgrade your cluster to Kubernetes v1.25+ before removing PSPs via a `helm upgrade` (even if you manually clean up resources), **it will leave the Helm release in a broken state within the cluster such that further Helm operations will not work (`helm uninstall`, `helm upgrade`, etc.).**
|
|
||||||
>
|
|
||||||
> If your charts get stuck in this state, you may have to clean up your Helm release secrets.
|
|
||||||
Upon setting `enablePSP` to false, the chart will remove any PSP resources deployed on its behalf from the cluster. This is the default setting for this chart.
|
|
||||||
|
|
||||||
As a replacement for PSPs, [Pod Security Admission](https://kubernetes.io/docs/concepts/security/pod-security-admission/) should be used. Please consult the Longhorn docs for more details on how to configure your chart release namespaces to work with the new Pod Security Admission and apply Pod Security Standards.
|
|
||||||
|
|
||||||
## Installation
|
|
||||||
1. Add Longhorn chart repository.
|
|
||||||
```
|
|
||||||
helm repo add longhorn https://charts.longhorn.io
|
|
||||||
```
|
|
||||||
|
|
||||||
2. Update local Longhorn chart information from chart repository.
|
|
||||||
```
|
|
||||||
helm repo update
|
|
||||||
```
|
|
||||||
|
|
||||||
3. Install Longhorn chart.
|
|
||||||
- With Helm 2, the following command will create the `longhorn-system` namespace and install the Longhorn chart together.
|
|
||||||
```
|
|
||||||
helm install longhorn/longhorn --name longhorn --namespace longhorn-system
|
|
||||||
```
|
|
||||||
- With Helm 3, the following commands will create the `longhorn-system` namespace first, then install the Longhorn chart.
|
|
||||||
|
|
||||||
```
|
|
||||||
kubectl create namespace longhorn-system
|
|
||||||
helm install longhorn longhorn/longhorn --namespace longhorn-system
|
|
||||||
```
|
|
||||||
|
|
||||||
## Uninstallation
|
|
||||||
|
|
||||||
With Helm 2 to uninstall Longhorn.
|
|
||||||
```
|
|
||||||
kubectl -n longhorn-system patch -p '{"value": "true"}' --type=merge lhs deleting-confirmation-flag
|
|
||||||
helm delete longhorn --purge
|
|
||||||
```
|
|
||||||
|
|
||||||
With Helm 3 to uninstall Longhorn.
|
|
||||||
```
|
|
||||||
kubectl -n longhorn-system patch -p '{"value": "true"}' --type=merge lhs deleting-confirmation-flag
|
|
||||||
helm uninstall longhorn -n longhorn-system
|
|
||||||
kubectl delete namespace longhorn-system
|
|
||||||
```
|
|
||||||
|
|
||||||
## Values
|
|
||||||
|
|
||||||
The `values.yaml` contains items used to tweak a deployment of this chart.
|
|
||||||
|
|
||||||
### Cattle Settings
|
|
||||||
|
|
||||||
| Key | Type | Default | Description |
|
|
||||||
|-----|------|---------|-------------|
|
|
||||||
{{- range .Values }}
|
|
||||||
{{- if hasPrefix "global" .Key }}
|
|
||||||
| {{ .Key }} | {{ .Type }} | {{ if .Default }}{{ .Default }}{{ else }}{{ .AutoDefault }}{{ end }} | {{ if .Description }}{{ .Description }}{{ else }}{{ .AutoDescription }}{{ end }} |
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
|
|
||||||
### Network Policies
|
|
||||||
|
|
||||||
| Key | Type | Default | Description |
|
|
||||||
|-----|------|---------|-------------|
|
|
||||||
{{- range .Values }}
|
|
||||||
{{- if hasPrefix "networkPolicies" .Key }}
|
|
||||||
| {{ .Key }} | {{ .Type }} | {{ if .Default }}{{ .Default }}{{ else }}{{ .AutoDefault }}{{ end }} | {{ if .Description }}{{ .Description }}{{ else }}{{ .AutoDescription }}{{ end }} |
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
|
|
||||||
### Image Settings
|
|
||||||
|
|
||||||
| Key | Type | Default | Description |
|
|
||||||
|-----|------|---------|-------------|
|
|
||||||
{{- range .Values }}
|
|
||||||
{{- if hasPrefix "image" .Key }}
|
|
||||||
| {{ .Key }} | {{ .Type }} | {{ if .Default }}{{ .Default }}{{ else }}{{ .AutoDefault }}{{ end }} | {{ if .Description }}{{ .Description }}{{ else }}{{ .AutoDescription }}{{ end }} |
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
|
|
||||||
### Service Settings
|
|
||||||
|
|
||||||
| Key | Description |
|
|
||||||
|-----|-------------|
|
|
||||||
{{- range .Values }}
|
|
||||||
{{- if (and (hasPrefix "service" .Key) (not (contains "Account" .Key))) }}
|
|
||||||
| {{ .Key }} | {{ if .Description }}{{ .Description }}{{ else }}{{ .AutoDescription }}{{ end }} |
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
|
|
||||||
### StorageClass Settings
|
|
||||||
|
|
||||||
| Key | Type | Default | Description |
|
|
||||||
|-----|------|---------|-------------|
|
|
||||||
{{- range .Values }}
|
|
||||||
{{- if hasPrefix "persistence" .Key }}
|
|
||||||
| {{ .Key }} | {{ .Type }} | {{ if .Default }}{{ .Default }}{{ else }}{{ .AutoDefault }}{{ end }} | {{ if .Description }}{{ .Description }}{{ else }}{{ .AutoDescription }}{{ end }} |
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
|
|
||||||
### CSI Settings
|
|
||||||
|
|
||||||
| Key | Description |
|
|
||||||
|-----|-------------|
|
|
||||||
{{- range .Values }}
|
|
||||||
{{- if hasPrefix "csi" .Key }}
|
|
||||||
| {{ .Key }} | {{ if .Description }}{{ .Description }}{{ else }}{{ .AutoDescription }}{{ end }} |
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
|
|
||||||
### Longhorn Manager Settings
|
|
||||||
|
|
||||||
Longhorn system contains user deployed components (e.g, Longhorn manager, Longhorn driver, Longhorn UI) and system managed components (e.g, instance manager, engine image, CSI driver, etc.).
|
|
||||||
These settings only apply to Longhorn manager component.
|
|
||||||
|
|
||||||
| Key | Type | Default | Description |
|
|
||||||
|-----|------|---------|-------------|
|
|
||||||
{{- range .Values }}
|
|
||||||
{{- if hasPrefix "longhornManager" .Key }}
|
|
||||||
| {{ .Key }} | {{ .Type }} | {{ if .Default }}{{ .Default }}{{ else }}{{ .AutoDefault }}{{ end }} | {{ if .Description }}{{ .Description }}{{ else }}{{ .AutoDescription }}{{ end }} |
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
|
|
||||||
### Longhorn Driver Settings
|
|
||||||
|
|
||||||
Longhorn system contains user deployed components (e.g, Longhorn manager, Longhorn driver, Longhorn UI) and system managed components (e.g, instance manager, engine image, CSI driver, etc.).
|
|
||||||
These settings only apply to Longhorn driver component.
|
|
||||||
|
|
||||||
| Key | Type | Default | Description |
|
|
||||||
|-----|------|---------|-------------|
|
|
||||||
{{- range .Values }}
|
|
||||||
{{- if hasPrefix "longhornDriver" .Key }}
|
|
||||||
| {{ .Key }} | {{ .Type }} | {{ if .Default }}{{ .Default }}{{ else }}{{ .AutoDefault }}{{ end }} | {{ if .Description }}{{ .Description }}{{ else }}{{ .AutoDescription }}{{ end }} |
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
|
|
||||||
### Longhorn UI Settings
|
|
||||||
|
|
||||||
Longhorn system contains user deployed components (e.g, Longhorn manager, Longhorn driver, Longhorn UI) and system managed components (e.g, instance manager, engine image, CSI driver, etc.).
|
|
||||||
These settings only apply to Longhorn UI component.
|
|
||||||
|
|
||||||
| Key | Type | Default | Description |
|
|
||||||
|-----|------|---------|-------------|
|
|
||||||
{{- range .Values }}
|
|
||||||
{{- if hasPrefix "longhornUI" .Key }}
|
|
||||||
| {{ .Key }} | {{ .Type }} | {{ if .Default }}{{ .Default }}{{ else }}{{ .AutoDefault }}{{ end }} | {{ if .Description }}{{ .Description }}{{ else }}{{ .AutoDescription }}{{ end }} |
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
|
|
||||||
### Ingress Settings
|
|
||||||
|
|
||||||
| Key | Type | Default | Description |
|
|
||||||
|-----|------|---------|-------------|
|
|
||||||
{{- range .Values }}
|
|
||||||
{{- if hasPrefix "ingress" .Key }}
|
|
||||||
| {{ .Key }} | {{ .Type }} | {{ if .Default }}{{ .Default }}{{ else }}{{ .AutoDefault }}{{ end }} | {{ if .Description }}{{ .Description }}{{ else }}{{ .AutoDescription }}{{ end }} |
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
|
|
||||||
### Private Registry Settings
|
|
||||||
|
|
||||||
Longhorn can be installed in an air gapped environment with private registry settings. Please refer to **Air Gap Installation** in our official site [link](https://longhorn.io/docs)
|
|
||||||
|
|
||||||
| Key | Description |
|
|
||||||
|-----|-------------|
|
|
||||||
{{- range .Values }}
|
|
||||||
{{- if hasPrefix "privateRegistry" .Key }}
|
|
||||||
| {{ .Key }} | {{ if .Description }}{{ .Description }}{{ else }}{{ .AutoDescription }}{{ end }} |
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
|
|
||||||
### OS/Kubernetes Distro Settings
|
|
||||||
|
|
||||||
#### Opensift Settings
|
|
||||||
|
|
||||||
Please also refer to this document [ocp-readme](https://github.com/longhorn/longhorn/blob/master/chart/ocp-readme.md) for more details
|
|
||||||
|
|
||||||
| Key | Type | Default | Description |
|
|
||||||
|-----|------|---------|-------------|
|
|
||||||
{{- range .Values }}
|
|
||||||
{{- if hasPrefix "openshift" .Key }}
|
|
||||||
| {{ .Key }} | {{ .Type }} | {{ if .Default }}{{ .Default }}{{ else }}{{ .AutoDefault }}{{ end }} | {{ if .Description }}{{ .Description }}{{ else }}{{ .AutoDescription }}{{ end }} |
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
|
|
||||||
### Other Settings
|
|
||||||
|
|
||||||
| Key | Default | Description |
|
|
||||||
|-----|---------|-------------|
|
|
||||||
{{- range .Values }}
|
|
||||||
{{- if not (or (hasPrefix "defaultSettings" .Key)
|
|
||||||
(hasPrefix "networkPolicies" .Key)
|
|
||||||
(hasPrefix "image" .Key)
|
|
||||||
(hasPrefix "service" .Key)
|
|
||||||
(hasPrefix "persistence" .Key)
|
|
||||||
(hasPrefix "csi" .Key)
|
|
||||||
(hasPrefix "longhornManager" .Key)
|
|
||||||
(hasPrefix "longhornDriver" .Key)
|
|
||||||
(hasPrefix "longhornUI" .Key)
|
|
||||||
(hasPrefix "privateRegistry" .Key)
|
|
||||||
(hasPrefix "ingress" .Key)
|
|
||||||
(hasPrefix "openshift" .Key)
|
|
||||||
(hasPrefix "global" .Key)) }}
|
|
||||||
| {{ .Key }} | {{ if .Default }}{{ .Default }}{{ else }}{{ .AutoDefault }}{{ end }} | {{ if .Description }}{{ .Description }}{{ else }}{{ .AutoDescription }}{{ end }} |
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
|
|
||||||
### System Default Settings
|
|
||||||
|
|
||||||
For system default settings, you can first leave blank to use default values which will be applied when installing Longhorn.
|
|
||||||
You can then change them through UI after installation.
|
|
||||||
For more details like types or options, you can refer to **Settings Reference** in our official site [link](https://longhorn.io/docs)
|
|
||||||
|
|
||||||
| Key | Description |
|
|
||||||
|-----|-------------|
|
|
||||||
{{- range .Values }}
|
|
||||||
{{- if hasPrefix "defaultSettings" .Key }}
|
|
||||||
| {{ .Key }} | {{ if .Description }}{{ .Description }}{{ else }}{{ .AutoDescription }}{{ end }} |
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
|
|
||||||
---
|
|
||||||
Please see [link](https://github.com/longhorn/longhorn) for more information.
|
|
||||||
@ -1,177 +0,0 @@
|
|||||||
# OpenShift / OKD Extra Configuration Steps
|
|
||||||
|
|
||||||
- [OpenShift / OKD Extra Configuration Steps](#openshift--okd-extra-configuration-steps)
|
|
||||||
- [Notes](#notes)
|
|
||||||
- [Known Issues](#known-issues)
|
|
||||||
- [Preparing Nodes (Optional)](#preparing-nodes-optional)
|
|
||||||
- [Default /var/lib/longhorn setup](#default-varliblonghorn-setup)
|
|
||||||
- [Separate /var/mnt/longhorn setup](#separate-varmntlonghorn-setup)
|
|
||||||
- [Create Filesystem](#create-filesystem)
|
|
||||||
- [Mounting Disk On Boot](#mounting-disk-on-boot)
|
|
||||||
- [Label and Annotate Nodes](#label-and-annotate-nodes)
|
|
||||||
- [Example values.yaml](#example-valuesyaml)
|
|
||||||
- [Installation](#installation)
|
|
||||||
- [Refs](#refs)
|
|
||||||
|
|
||||||
## Notes
|
|
||||||
|
|
||||||
Main changes and tasks for OCP are:
|
|
||||||
|
|
||||||
- On OCP / OKD, the Operating System is Managed by the Cluster
|
|
||||||
- OCP Imposes [Security Context Constraints](https://docs.openshift.com/container-platform/4.11/authentication/managing-security-context-constraints.html)
|
|
||||||
- This requires everything to run with the least privilege possible. For the moment every component has been given access to run as higher privilege.
|
|
||||||
- Something to circle back on is network polices and which components can have their privileges reduced without impacting functionality.
|
|
||||||
- The UI probably can be for example.
|
|
||||||
- openshift/oauth-proxy for authentication to the Longhorn Ui
|
|
||||||
- **⚠️** Currently Scoped to Authenticated Users that can delete a longhorn settings object.
|
|
||||||
- **⚠️** Since the UI it self is not protected, network policies will need to be created to prevent namespace <--> namespace communication against the pod or service object directly.
|
|
||||||
- Anyone with access to the UI Deployment can remove the route restriction. (Namespace Scoped Admin)
|
|
||||||
- Option to use separate disk in /var/mnt/longhorn & MachineConfig file to mount /var/mnt/longhorn
|
|
||||||
- Adding finalizers for mount propagation
|
|
||||||
|
|
||||||
## Known Issues
|
|
||||||
|
|
||||||
- General Feature/Issue Thread
|
|
||||||
- [[FEATURE] Deploying Longhorn on OKD/Openshift](https://github.com/longhorn/longhorn/issues/1831)
|
|
||||||
- 4.10 / 1.23:
|
|
||||||
- 4.10.0-0.okd-2022-03-07-131213 to 4.10.0-0.okd-2022-07-09-073606
|
|
||||||
- Tested, No Known Issues
|
|
||||||
- 4.11 / 1.24:
|
|
||||||
- 4.11.0-0.okd-2022-07-27-052000 to 4.11.0-0.okd-2022-11-19-050030
|
|
||||||
- Tested, No Known Issues
|
|
||||||
- 4.11.0-0.okd-2022-12-02-145640, 4.11.0-0.okd-2023-01-14-152430:
|
|
||||||
- Workaround: [[BUG] Volumes Stuck in Attach/Detach Loop](https://github.com/longhorn/longhorn/issues/4988)
|
|
||||||
- [MachineConfig Patch](https://github.com/longhorn/longhorn/issues/4988#issuecomment-1345676772)
|
|
||||||
- 4.12 / 1.25:
|
|
||||||
- 4.12.0-0.okd-2022-12-05-210624 to 4.12.0-0.okd-2023-01-20-101927
|
|
||||||
- Tested, No Known Issues
|
|
||||||
- 4.12.0-0.okd-2023-01-21-055900 to 4.12.0-0.okd-2023-02-18-033438:
|
|
||||||
- Workaround: [[BUG] Volumes Stuck in Attach/Detach Loop](https://github.com/longhorn/longhorn/issues/4988)
|
|
||||||
- [MachineConfig Patch](https://github.com/longhorn/longhorn/issues/4988#issuecomment-1345676772)
|
|
||||||
- 4.12.0-0.okd-2023-03-05-022504 - 4.12.0-0.okd-2023-04-16-041331:
|
|
||||||
- Tested, No Known Issues
|
|
||||||
- 4.13 / 1.26:
|
|
||||||
- 4.13.0-0.okd-2023-05-03-001308 - 4.13.0-0.okd-2023-08-18-135805:
|
|
||||||
- Tested, No Known Issues
|
|
||||||
- 4.14 / 1.27:
|
|
||||||
- 4.14.0-0.okd-2023-08-12-022330 - 4.14.0-0.okd-2023-10-28-073550:
|
|
||||||
- Tested, No Known Issues
|
|
||||||
|
|
||||||
## Preparing Nodes (Optional)
|
|
||||||
|
|
||||||
Only required if you require additional customizations, such as storage-less nodes, or secondary disks.
|
|
||||||
|
|
||||||
### Default /var/lib/longhorn setup
|
|
||||||
|
|
||||||
Label each node for storage with:
|
|
||||||
|
|
||||||
```bash
|
|
||||||
oc get nodes --no-headers | awk '{print $1}'
|
|
||||||
|
|
||||||
export NODE="worker-0"
|
|
||||||
oc label node "${NODE}" node.longhorn.io/create-default-disk=true
|
|
||||||
```
|
|
||||||
|
|
||||||
### Separate /var/mnt/longhorn setup
|
|
||||||
|
|
||||||
#### Create Filesystem
|
|
||||||
|
|
||||||
On the storage nodes create a filesystem with the label longhorn:
|
|
||||||
|
|
||||||
```bash
|
|
||||||
oc get nodes --no-headers | awk '{print $1}'
|
|
||||||
|
|
||||||
export NODE="worker-0"
|
|
||||||
oc debug node/${NODE} -t -- chroot /host bash
|
|
||||||
|
|
||||||
# Validate Target Drive is Present
|
|
||||||
lsblk
|
|
||||||
|
|
||||||
export DRIVE="sdb" #vdb
|
|
||||||
sudo mkfs.ext4 -L longhorn /dev/${DRIVE}
|
|
||||||
```
|
|
||||||
|
|
||||||
> ⚠️ Note: If you add New Nodes After the below Machine Config is applied, you will need to also reboot the node.
|
|
||||||
|
|
||||||
#### Mounting Disk On Boot
|
|
||||||
|
|
||||||
The Secondary Drive needs to be mounted on every boot. Save the Concents and Apply the MachineConfig with `oc apply -f`:
|
|
||||||
|
|
||||||
> ⚠️ This will trigger an machine config profile update and reboot all worker nodes on the cluster
|
|
||||||
|
|
||||||
```yaml
|
|
||||||
apiVersion: machineconfiguration.openshift.io/v1
|
|
||||||
kind: MachineConfig
|
|
||||||
metadata:
|
|
||||||
labels:
|
|
||||||
machineconfiguration.openshift.io/role: worker
|
|
||||||
name: 71-mount-storage-worker
|
|
||||||
spec:
|
|
||||||
config:
|
|
||||||
ignition:
|
|
||||||
version: 3.2.0
|
|
||||||
systemd:
|
|
||||||
units:
|
|
||||||
- name: var-mnt-longhorn.mount
|
|
||||||
enabled: true
|
|
||||||
contents: |
|
|
||||||
[Unit]
|
|
||||||
Before=local-fs.target
|
|
||||||
[Mount]
|
|
||||||
Where=/var/mnt/longhorn
|
|
||||||
What=/dev/disk/by-label/longhorn
|
|
||||||
Options=rw,relatime,discard
|
|
||||||
[Install]
|
|
||||||
WantedBy=local-fs.target
|
|
||||||
```
|
|
||||||
|
|
||||||
#### Label and Annotate Nodes
|
|
||||||
|
|
||||||
Label and annotate storage nodes like this:
|
|
||||||
|
|
||||||
```bash
|
|
||||||
oc get nodes --no-headers | awk '{print $1}'
|
|
||||||
|
|
||||||
export NODE="worker-0"
|
|
||||||
oc annotate node ${NODE} --overwrite node.longhorn.io/default-disks-config='[{"path":"/var/mnt/longhorn","allowScheduling":true}]'
|
|
||||||
oc label node ${NODE} node.longhorn.io/create-default-disk=config
|
|
||||||
```
|
|
||||||
|
|
||||||
## Example values.yaml
|
|
||||||
|
|
||||||
Minimum Adjustments Required
|
|
||||||
|
|
||||||
```yaml
|
|
||||||
openshift:
|
|
||||||
oauthProxy:
|
|
||||||
repository: quay.io/openshift/origin-oauth-proxy
|
|
||||||
tag: 4.14 # Use Your OCP/OKD 4.X Version, Current Stable is 4.14
|
|
||||||
|
|
||||||
# defaultSettings: # Preparing nodes (Optional)
|
|
||||||
# createDefaultDiskLabeledNodes: true
|
|
||||||
|
|
||||||
openshift:
|
|
||||||
enabled: true
|
|
||||||
ui:
|
|
||||||
route: "longhorn-ui"
|
|
||||||
port: 443
|
|
||||||
proxy: 8443
|
|
||||||
```
|
|
||||||
|
|
||||||
## Installation
|
|
||||||
|
|
||||||
```bash
|
|
||||||
# helm template ./chart/ --namespace longhorn-system --values ./chart/values.yaml --no-hooks > longhorn.yaml # Local Testing
|
|
||||||
helm template longhorn --namespace longhorn-system --values values.yaml --no-hooks > longhorn.yaml
|
|
||||||
oc create namespace longhorn-system -o yaml --dry-run=client | oc apply -f -
|
|
||||||
oc apply -f longhorn.yaml -n longhorn-system
|
|
||||||
```
|
|
||||||
|
|
||||||
## Refs
|
|
||||||
|
|
||||||
- <https://docs.openshift.com/container-platform/4.11/storage/persistent_storage/persistent-storage-iscsi.html>
|
|
||||||
- <https://docs.okd.io/4.11/storage/persistent_storage/persistent-storage-iscsi.html>
|
|
||||||
- okd 4.5: <https://github.com/longhorn/longhorn/issues/1831#issuecomment-702690613>
|
|
||||||
- okd 4.6: <https://github.com/longhorn/longhorn/issues/1831#issuecomment-765884631>
|
|
||||||
- oauth-proxy: <https://github.com/openshift/oauth-proxy/blob/master/contrib/sidecar.yaml>
|
|
||||||
- <https://github.com/longhorn/longhorn/issues/1831>
|
|
||||||
@ -1,825 +0,0 @@
|
|||||||
categories:
|
|
||||||
- storage
|
|
||||||
namespace: longhorn-system
|
|
||||||
questions:
|
|
||||||
- variable: image.defaultImage
|
|
||||||
default: "true"
|
|
||||||
description: "Use default Longhorn images"
|
|
||||||
label: Use Default Images
|
|
||||||
type: boolean
|
|
||||||
show_subquestion_if: false
|
|
||||||
group: "Longhorn Images"
|
|
||||||
subquestions:
|
|
||||||
- variable: image.longhorn.manager.repository
|
|
||||||
default: longhornio/longhorn-manager
|
|
||||||
description: "Specify Longhorn Manager Image Repository"
|
|
||||||
type: string
|
|
||||||
label: Longhorn Manager Image Repository
|
|
||||||
group: "Longhorn Images Settings"
|
|
||||||
- variable: image.longhorn.manager.tag
|
|
||||||
default: master-head
|
|
||||||
description: "Specify Longhorn Manager Image Tag"
|
|
||||||
type: string
|
|
||||||
label: Longhorn Manager Image Tag
|
|
||||||
group: "Longhorn Images Settings"
|
|
||||||
- variable: image.longhorn.engine.repository
|
|
||||||
default: longhornio/longhorn-engine
|
|
||||||
description: "Specify Longhorn Engine Image Repository"
|
|
||||||
type: string
|
|
||||||
label: Longhorn Engine Image Repository
|
|
||||||
group: "Longhorn Images Settings"
|
|
||||||
- variable: image.longhorn.engine.tag
|
|
||||||
default: master-head
|
|
||||||
description: "Specify Longhorn Engine Image Tag"
|
|
||||||
type: string
|
|
||||||
label: Longhorn Engine Image Tag
|
|
||||||
group: "Longhorn Images Settings"
|
|
||||||
- variable: image.longhorn.ui.repository
|
|
||||||
default: longhornio/longhorn-ui
|
|
||||||
description: "Specify Longhorn UI Image Repository"
|
|
||||||
type: string
|
|
||||||
label: Longhorn UI Image Repository
|
|
||||||
group: "Longhorn Images Settings"
|
|
||||||
- variable: image.longhorn.ui.tag
|
|
||||||
default: master-head
|
|
||||||
description: "Specify Longhorn UI Image Tag"
|
|
||||||
type: string
|
|
||||||
label: Longhorn UI Image Tag
|
|
||||||
group: "Longhorn Images Settings"
|
|
||||||
- variable: image.longhorn.instanceManager.repository
|
|
||||||
default: longhornio/longhorn-instance-manager
|
|
||||||
description: "Specify Longhorn Instance Manager Image Repository"
|
|
||||||
type: string
|
|
||||||
label: Longhorn Instance Manager Image Repository
|
|
||||||
group: "Longhorn Images Settings"
|
|
||||||
- variable: image.longhorn.instanceManager.tag
|
|
||||||
default: v2_20221123
|
|
||||||
description: "Specify Longhorn Instance Manager Image Tag"
|
|
||||||
type: string
|
|
||||||
label: Longhorn Instance Manager Image Tag
|
|
||||||
group: "Longhorn Images Settings"
|
|
||||||
- variable: image.longhorn.shareManager.repository
|
|
||||||
default: longhornio/longhorn-share-manager
|
|
||||||
description: "Specify Longhorn Share Manager Image Repository"
|
|
||||||
type: string
|
|
||||||
label: Longhorn Share Manager Image Repository
|
|
||||||
group: "Longhorn Images Settings"
|
|
||||||
- variable: image.longhorn.shareManager.tag
|
|
||||||
default: v1_20220914
|
|
||||||
description: "Specify Longhorn Share Manager Image Tag"
|
|
||||||
type: string
|
|
||||||
label: Longhorn Share Manager Image Tag
|
|
||||||
group: "Longhorn Images Settings"
|
|
||||||
- variable: image.longhorn.backingImageManager.repository
|
|
||||||
default: longhornio/backing-image-manager
|
|
||||||
description: "Specify Longhorn Backing Image Manager Image Repository"
|
|
||||||
type: string
|
|
||||||
label: Longhorn Backing Image Manager Image Repository
|
|
||||||
group: "Longhorn Images Settings"
|
|
||||||
- variable: image.longhorn.backingImageManager.tag
|
|
||||||
default: v3_20220808
|
|
||||||
description: "Specify Longhorn Backing Image Manager Image Tag"
|
|
||||||
type: string
|
|
||||||
label: Longhorn Backing Image Manager Image Tag
|
|
||||||
group: "Longhorn Images Settings"
|
|
||||||
- variable: image.longhorn.supportBundleKit.repository
|
|
||||||
default: longhornio/support-bundle-kit
|
|
||||||
description: "Specify Longhorn Support Bundle Manager Image Repository"
|
|
||||||
type: string
|
|
||||||
label: Longhorn Support Bundle Kit Image Repository
|
|
||||||
group: "Longhorn Images Settings"
|
|
||||||
- variable: image.longhorn.supportBundleKit.tag
|
|
||||||
default: v0.0.27
|
|
||||||
description: "Specify Longhorn Support Bundle Manager Image Tag"
|
|
||||||
type: string
|
|
||||||
label: Longhorn Support Bundle Kit Image Tag
|
|
||||||
group: "Longhorn Images Settings"
|
|
||||||
- variable: image.csi.attacher.repository
|
|
||||||
default: longhornio/csi-attacher
|
|
||||||
description: "Specify CSI attacher image repository. Leave blank to autodetect."
|
|
||||||
type: string
|
|
||||||
label: Longhorn CSI Attacher Image Repository
|
|
||||||
group: "Longhorn CSI Driver Images"
|
|
||||||
- variable: image.csi.attacher.tag
|
|
||||||
default: v4.2.0
|
|
||||||
description: "Specify CSI attacher image tag. Leave blank to autodetect."
|
|
||||||
type: string
|
|
||||||
label: Longhorn CSI Attacher Image Tag
|
|
||||||
group: "Longhorn CSI Driver Images"
|
|
||||||
- variable: image.csi.provisioner.repository
|
|
||||||
default: longhornio/csi-provisioner
|
|
||||||
description: "Specify CSI provisioner image repository. Leave blank to autodetect."
|
|
||||||
type: string
|
|
||||||
label: Longhorn CSI Provisioner Image Repository
|
|
||||||
group: "Longhorn CSI Driver Images"
|
|
||||||
- variable: image.csi.provisioner.tag
|
|
||||||
default: v3.4.1
|
|
||||||
description: "Specify CSI provisioner image tag. Leave blank to autodetect."
|
|
||||||
type: string
|
|
||||||
label: Longhorn CSI Provisioner Image Tag
|
|
||||||
group: "Longhorn CSI Driver Images"
|
|
||||||
- variable: image.csi.nodeDriverRegistrar.repository
|
|
||||||
default: longhornio/csi-node-driver-registrar
|
|
||||||
description: "Specify CSI Node Driver Registrar image repository. Leave blank to autodetect."
|
|
||||||
type: string
|
|
||||||
label: Longhorn CSI Node Driver Registrar Image Repository
|
|
||||||
group: "Longhorn CSI Driver Images"
|
|
||||||
- variable: image.csi.nodeDriverRegistrar.tag
|
|
||||||
default: v2.7.0
|
|
||||||
description: "Specify CSI Node Driver Registrar image tag. Leave blank to autodetect."
|
|
||||||
type: string
|
|
||||||
label: Longhorn CSI Node Driver Registrar Image Tag
|
|
||||||
group: "Longhorn CSI Driver Images"
|
|
||||||
- variable: image.csi.resizer.repository
|
|
||||||
default: longhornio/csi-resizer
|
|
||||||
description: "Specify CSI Driver Resizer image repository. Leave blank to autodetect."
|
|
||||||
type: string
|
|
||||||
label: Longhorn CSI Driver Resizer Image Repository
|
|
||||||
group: "Longhorn CSI Driver Images"
|
|
||||||
- variable: image.csi.resizer.tag
|
|
||||||
default: v1.7.0
|
|
||||||
description: "Specify CSI Driver Resizer image tag. Leave blank to autodetect."
|
|
||||||
type: string
|
|
||||||
label: Longhorn CSI Driver Resizer Image Tag
|
|
||||||
group: "Longhorn CSI Driver Images"
|
|
||||||
- variable: image.csi.snapshotter.repository
|
|
||||||
default: longhornio/csi-snapshotter
|
|
||||||
description: "Specify CSI Driver Snapshotter image repository. Leave blank to autodetect."
|
|
||||||
type: string
|
|
||||||
label: Longhorn CSI Driver Snapshotter Image Repository
|
|
||||||
group: "Longhorn CSI Driver Images"
|
|
||||||
- variable: image.csi.snapshotter.tag
|
|
||||||
default: v6.2.1
|
|
||||||
description: "Specify CSI Driver Snapshotter image tag. Leave blank to autodetect."
|
|
||||||
type: string
|
|
||||||
label: Longhorn CSI Driver Snapshotter Image Tag
|
|
||||||
group: "Longhorn CSI Driver Images"
|
|
||||||
- variable: image.csi.livenessProbe.repository
|
|
||||||
default: longhornio/livenessprobe
|
|
||||||
description: "Specify CSI liveness probe image repository. Leave blank to autodetect."
|
|
||||||
type: string
|
|
||||||
label: Longhorn CSI Liveness Probe Image Repository
|
|
||||||
group: "Longhorn CSI Driver Images"
|
|
||||||
- variable: image.csi.livenessProbe.tag
|
|
||||||
default: v2.9.0
|
|
||||||
description: "Specify CSI liveness probe image tag. Leave blank to autodetect."
|
|
||||||
type: string
|
|
||||||
label: Longhorn CSI Liveness Probe Image Tag
|
|
||||||
group: "Longhorn CSI Driver Images"
|
|
||||||
- variable: privateRegistry.registryUrl
|
|
||||||
label: Private registry URL
|
|
||||||
description: "URL of private registry. Leave blank to apply system default registry."
|
|
||||||
group: "Private Registry Settings"
|
|
||||||
type: string
|
|
||||||
default: ""
|
|
||||||
- variable: privateRegistry.registrySecret
|
|
||||||
label: Private registry secret name
|
|
||||||
description: "If create a new private registry secret is true, create a Kubernetes secret with this name; else use the existing secret of this name. Use it to pull images from your private registry."
|
|
||||||
group: "Private Registry Settings"
|
|
||||||
type: string
|
|
||||||
default: ""
|
|
||||||
- variable: privateRegistry.createSecret
|
|
||||||
default: "true"
|
|
||||||
description: "Create a new private registry secret"
|
|
||||||
type: boolean
|
|
||||||
group: "Private Registry Settings"
|
|
||||||
label: Create Secret for Private Registry Settings
|
|
||||||
show_subquestion_if: true
|
|
||||||
subquestions:
|
|
||||||
- variable: privateRegistry.registryUser
|
|
||||||
label: Private registry user
|
|
||||||
description: "User used to authenticate to private registry."
|
|
||||||
type: string
|
|
||||||
default: ""
|
|
||||||
- variable: privateRegistry.registryPasswd
|
|
||||||
label: Private registry password
|
|
||||||
description: "Password used to authenticate to private registry."
|
|
||||||
type: password
|
|
||||||
default: ""
|
|
||||||
- variable: longhorn.default_setting
|
|
||||||
default: "false"
|
|
||||||
description: "Customize the default settings before installing Longhorn for the first time. This option will only work if the cluster hasn't installed Longhorn."
|
|
||||||
label: "Customize Default Settings"
|
|
||||||
type: boolean
|
|
||||||
show_subquestion_if: true
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
subquestions:
|
|
||||||
- variable: csi.kubeletRootDir
|
|
||||||
default:
|
|
||||||
description: "Specify kubelet root-dir. Leave blank to autodetect."
|
|
||||||
type: string
|
|
||||||
label: Kubelet Root Directory
|
|
||||||
group: "Longhorn CSI Driver Settings"
|
|
||||||
- variable: csi.attacherReplicaCount
|
|
||||||
type: int
|
|
||||||
default: 3
|
|
||||||
min: 1
|
|
||||||
max: 10
|
|
||||||
description: "Specify replica count of CSI Attacher. By default 3."
|
|
||||||
label: Longhorn CSI Attacher replica count
|
|
||||||
group: "Longhorn CSI Driver Settings"
|
|
||||||
- variable: csi.provisionerReplicaCount
|
|
||||||
type: int
|
|
||||||
default: 3
|
|
||||||
min: 1
|
|
||||||
max: 10
|
|
||||||
description: "Specify replica count of CSI Provisioner. By default 3."
|
|
||||||
label: Longhorn CSI Provisioner replica count
|
|
||||||
group: "Longhorn CSI Driver Settings"
|
|
||||||
- variable: csi.resizerReplicaCount
|
|
||||||
type: int
|
|
||||||
default: 3
|
|
||||||
min: 1
|
|
||||||
max: 10
|
|
||||||
description: "Specify replica count of CSI Resizer. By default 3."
|
|
||||||
label: Longhorn CSI Resizer replica count
|
|
||||||
group: "Longhorn CSI Driver Settings"
|
|
||||||
- variable: csi.snapshotterReplicaCount
|
|
||||||
type: int
|
|
||||||
default: 3
|
|
||||||
min: 1
|
|
||||||
max: 10
|
|
||||||
description: "Specify replica count of CSI Snapshotter. By default 3."
|
|
||||||
label: Longhorn CSI Snapshotter replica count
|
|
||||||
group: "Longhorn CSI Driver Settings"
|
|
||||||
- variable: defaultSettings.backupTarget
|
|
||||||
label: Backup Target
|
|
||||||
description: "The endpoint used to access the backupstore. Available: NFS, CIFS, AWS, GCP, AZURE"
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: string
|
|
||||||
default:
|
|
||||||
- variable: defaultSettings.backupTargetCredentialSecret
|
|
||||||
label: Backup Target Credential Secret
|
|
||||||
description: "The name of the Kubernetes secret associated with the backup target."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: string
|
|
||||||
default:
|
|
||||||
- variable: defaultSettings.allowRecurringJobWhileVolumeDetached
|
|
||||||
label: Allow Recurring Job While Volume Is Detached
|
|
||||||
description: 'If this setting is enabled, Longhorn will automatically attaches the volume and takes snapshot/backup when it is the time to do recurring snapshot/backup.'
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: boolean
|
|
||||||
default: "false"
|
|
||||||
- variable: defaultSettings.createDefaultDiskLabeledNodes
|
|
||||||
label: Create Default Disk on Labeled Nodes
|
|
||||||
description: 'Create default Disk automatically only on Nodes with the label "node.longhorn.io/create-default-disk=true" if no other disks exist. If disabled, the default disk will be created on all new nodes when each node is first added.'
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: boolean
|
|
||||||
default: "false"
|
|
||||||
- variable: defaultSettings.defaultDataPath
|
|
||||||
label: Default Data Path
|
|
||||||
description: 'Default path to use for storing data on a host. By default "/var/lib/longhorn/"'
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: string
|
|
||||||
default: "/var/lib/longhorn/"
|
|
||||||
- variable: defaultSettings.defaultDataLocality
|
|
||||||
label: Default Data Locality
|
|
||||||
description: 'Longhorn volume has data locality if there is a local replica of the volume on the same node as the pod which is using the volume.'
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: enum
|
|
||||||
options:
|
|
||||||
- "disabled"
|
|
||||||
- "best-effort"
|
|
||||||
default: "disabled"
|
|
||||||
- variable: defaultSettings.replicaSoftAntiAffinity
|
|
||||||
label: Replica Node Level Soft Anti-Affinity
|
|
||||||
description: 'Allow scheduling on nodes with existing healthy replicas of the same volume. By default false.'
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: boolean
|
|
||||||
default: "false"
|
|
||||||
- variable: defaultSettings.replicaAutoBalance
|
|
||||||
label: Replica Auto Balance
|
|
||||||
description: 'Enable this setting automatically rebalances replicas when discovered an available node.'
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: enum
|
|
||||||
options:
|
|
||||||
- "disabled"
|
|
||||||
- "least-effort"
|
|
||||||
- "best-effort"
|
|
||||||
default: "disabled"
|
|
||||||
- variable: defaultSettings.storageOverProvisioningPercentage
|
|
||||||
label: Storage Over Provisioning Percentage
|
|
||||||
description: "The over-provisioning percentage defines how much storage can be allocated relative to the hard drive's capacity. By default 200."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: int
|
|
||||||
min: 0
|
|
||||||
default: 200
|
|
||||||
- variable: defaultSettings.storageMinimalAvailablePercentage
|
|
||||||
label: Storage Minimal Available Percentage
|
|
||||||
description: "If the minimum available disk capacity exceeds the actual percentage of available disk capacity, the disk becomes unschedulable until more space is freed up. By default 25."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: int
|
|
||||||
min: 0
|
|
||||||
max: 100
|
|
||||||
default: 25
|
|
||||||
- variable: defaultSettings.storageReservedPercentageForDefaultDisk
|
|
||||||
label: Storage Reserved Percentage For Default Disk
|
|
||||||
description: "The reserved percentage specifies the percentage of disk space that will not be allocated to the default disk on each new Longhorn node."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: int
|
|
||||||
min: 0
|
|
||||||
max: 100
|
|
||||||
default: 30
|
|
||||||
- variable: defaultSettings.upgradeChecker
|
|
||||||
label: Enable Upgrade Checker
|
|
||||||
description: 'Upgrade Checker will check for new Longhorn version periodically. When there is a new version available, a notification will appear in the UI. By default true.'
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: boolean
|
|
||||||
default: "true"
|
|
||||||
- variable: defaultSettings.defaultReplicaCount
|
|
||||||
label: Default Replica Count
|
|
||||||
description: "The default number of replicas when a volume is created from the Longhorn UI. For Kubernetes configuration, update the `numberOfReplicas` in the StorageClass. By default 3."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: int
|
|
||||||
min: 1
|
|
||||||
max: 20
|
|
||||||
default: 3
|
|
||||||
- variable: defaultSettings.defaultLonghornStaticStorageClass
|
|
||||||
label: Default Longhorn Static StorageClass Name
|
|
||||||
description: "The 'storageClassName' is given to PVs and PVCs that are created for an existing Longhorn volume. The StorageClass name can also be used as a label, so it is possible to use a Longhorn StorageClass to bind a workload to an existing PV without creating a Kubernetes StorageClass object. By default 'longhorn-static'."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: string
|
|
||||||
default: "longhorn-static"
|
|
||||||
- variable: defaultSettings.backupstorePollInterval
|
|
||||||
label: Backupstore Poll Interval
|
|
||||||
description: "In seconds. The backupstore poll interval determines how often Longhorn checks the backupstore for new backups. Set to 0 to disable the polling. By default 300."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: int
|
|
||||||
min: 0
|
|
||||||
default: 300
|
|
||||||
- variable: defaultSettings.failedBackupTTL
|
|
||||||
label: Failed Backup Time to Live
|
|
||||||
description: "In minutes. This setting determines how long Longhorn will keep the backup resource that was failed. Set to 0 to disable the auto-deletion."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: int
|
|
||||||
min: 0
|
|
||||||
default: 1440
|
|
||||||
- variable: defaultSettings.restoreVolumeRecurringJobs
|
|
||||||
label: Restore Volume Recurring Jobs
|
|
||||||
description: "Restore recurring jobs from the backup volume on the backup target and create recurring jobs if not exist during a backup restoration."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: boolean
|
|
||||||
default: "false"
|
|
||||||
- variable: defaultSettings.recurringSuccessfulJobsHistoryLimit
|
|
||||||
label: Cronjob Successful Jobs History Limit
|
|
||||||
description: "This setting specifies how many successful backup or snapshot job histories should be retained. History will not be retained if the value is 0."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: int
|
|
||||||
min: 0
|
|
||||||
default: 1
|
|
||||||
- variable: defaultSettings.recurringFailedJobsHistoryLimit
|
|
||||||
label: Cronjob Failed Jobs History Limit
|
|
||||||
description: "This setting specifies how many failed backup or snapshot job histories should be retained. History will not be retained if the value is 0."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: int
|
|
||||||
min: 0
|
|
||||||
default: 1
|
|
||||||
- variable: defaultSettings.supportBundleFailedHistoryLimit
|
|
||||||
label: SupportBundle Failed History Limit
|
|
||||||
description: "This setting specifies how many failed support bundles can exist in the cluster. Set this value to **0** to have Longhorn automatically purge all failed support bundles."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: int
|
|
||||||
min: 0
|
|
||||||
default: 1
|
|
||||||
- variable: defaultSettings.autoSalvage
|
|
||||||
label: Automatic salvage
|
|
||||||
description: "If enabled, volumes will be automatically salvaged when all the replicas become faulty e.g. due to network disconnection. Longhorn will try to figure out which replica(s) are usable, then use them for the volume. By default true."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: boolean
|
|
||||||
default: "true"
|
|
||||||
- variable: defaultSettings.autoDeletePodWhenVolumeDetachedUnexpectedly
|
|
||||||
label: Automatically Delete Workload Pod when The Volume Is Detached Unexpectedly
|
|
||||||
description: 'If enabled, Longhorn will automatically delete the workload pod that is managed by a controller (e.g. deployment, statefulset, daemonset, etc...) when Longhorn volume is detached unexpectedly (e.g. during Kubernetes upgrade, Docker reboot, or network disconnect). By deleting the pod, its controller restarts the pod and Kubernetes handles volume reattachment and remount.'
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: boolean
|
|
||||||
default: "true"
|
|
||||||
- variable: defaultSettings.disableSchedulingOnCordonedNode
|
|
||||||
label: Disable Scheduling On Cordoned Node
|
|
||||||
description: "Disable Longhorn manager to schedule replica on Kubernetes cordoned node. By default true."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: boolean
|
|
||||||
default: "true"
|
|
||||||
- variable: defaultSettings.replicaZoneSoftAntiAffinity
|
|
||||||
label: Replica Zone Level Soft Anti-Affinity
|
|
||||||
description: "Allow scheduling new Replicas of Volume to the Nodes in the same Zone as existing healthy Replicas. Nodes don't belong to any Zone will be treated as in the same Zone. Notice that Longhorn relies on label `topology.kubernetes.io/zone=<Zone name of the node>` in the Kubernetes node object to identify the zone. By default true."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: boolean
|
|
||||||
default: "true"
|
|
||||||
- variable: defaultSettings.replicaDiskSoftAntiAffinity
|
|
||||||
label: Replica Disk Level Soft Anti-Affinity
|
|
||||||
description: 'Allow scheduling on disks with existing healthy replicas of the same volume. By default true.'
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: boolean
|
|
||||||
default: "true"
|
|
||||||
- variable: defaultSettings.allowEmptyNodeSelectorVolume
|
|
||||||
label: Allow Empty Node Selector Volume
|
|
||||||
description: "Allow Scheduling Empty Node Selector Volumes To Any Node"
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: boolean
|
|
||||||
default: "true"
|
|
||||||
- variable: defaultSettings.allowEmptyDiskSelectorVolume
|
|
||||||
label: Allow Empty Disk Selector Volume
|
|
||||||
description: "Allow Scheduling Empty Disk Selector Volumes To Any Disk"
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: boolean
|
|
||||||
default: "true"
|
|
||||||
- variable: defaultSettings.nodeDownPodDeletionPolicy
|
|
||||||
label: Pod Deletion Policy When Node is Down
|
|
||||||
description: "Defines the Longhorn action when a Volume is stuck with a StatefulSet/Deployment Pod on a node that is down."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: enum
|
|
||||||
options:
|
|
||||||
- "do-nothing"
|
|
||||||
- "delete-statefulset-pod"
|
|
||||||
- "delete-deployment-pod"
|
|
||||||
- "delete-both-statefulset-and-deployment-pod"
|
|
||||||
default: "do-nothing"
|
|
||||||
- variable: defaultSettings.nodeDrainPolicy
|
|
||||||
label: Node Drain Policy
|
|
||||||
description: "Define the policy to use when a node with the last healthy replica of a volume is drained."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: enum
|
|
||||||
options:
|
|
||||||
- "block-if-contains-last-replica"
|
|
||||||
- "allow-if-replica-is-stopped"
|
|
||||||
- "always-allow"
|
|
||||||
default: "block-if-contains-last-replica"
|
|
||||||
- variable: defaultSettings.replicaReplenishmentWaitInterval
|
|
||||||
label: Replica Replenishment Wait Interval
|
|
||||||
description: "In seconds. The interval determines how long Longhorn will wait at least in order to reuse the existing data on a failed replica rather than directly creating a new replica for a degraded volume."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: int
|
|
||||||
min: 0
|
|
||||||
default: 600
|
|
||||||
- variable: defaultSettings.concurrentReplicaRebuildPerNodeLimit
|
|
||||||
label: Concurrent Replica Rebuild Per Node Limit
|
|
||||||
description: "This setting controls how many replicas on a node can be rebuilt simultaneously."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: int
|
|
||||||
min: 0
|
|
||||||
default: 5
|
|
||||||
- variable: defaultSettings.concurrentVolumeBackupRestorePerNodeLimit
|
|
||||||
label: Concurrent Volume Backup Restore Per Node Limit
|
|
||||||
description: "This setting controls how many volumes on a node can restore the backup concurrently. Set the value to **0** to disable backup restore."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: int
|
|
||||||
min: 0
|
|
||||||
default: 5
|
|
||||||
- variable: defaultSettings.disableRevisionCounter
|
|
||||||
label: Disable Revision Counter
|
|
||||||
description: "This setting is only for volumes created by UI. By default, this is false meaning there will be a reivision counter file to track every write to the volume. During salvage recovering Longhorn will pick the replica with largest reivision counter as candidate to recover the whole volume. If revision counter is disabled, Longhorn will not track every write to the volume. During the salvage recovering, Longhorn will use the 'volume-head-xxx.img' file last modification time and file size to pick the replica candidate to recover the whole volume."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: boolean
|
|
||||||
default: "false"
|
|
||||||
- variable: defaultSettings.systemManagedPodsImagePullPolicy
|
|
||||||
label: System Managed Pod Image Pull Policy
|
|
||||||
description: "This setting defines the Image Pull Policy of Longhorn system managed pods, e.g. instance manager, engine image, CSI driver, etc. The new Image Pull Policy will only apply after the system managed pods restart."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: enum
|
|
||||||
options:
|
|
||||||
- "if-not-present"
|
|
||||||
- "always"
|
|
||||||
- "never"
|
|
||||||
default: "if-not-present"
|
|
||||||
- variable: defaultSettings.allowVolumeCreationWithDegradedAvailability
|
|
||||||
label: Allow Volume Creation with Degraded Availability
|
|
||||||
description: "This setting allows user to create and attach a volume that doesn't have all the replicas scheduled at the time of creation."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: boolean
|
|
||||||
default: "true"
|
|
||||||
- variable: defaultSettings.autoCleanupSystemGeneratedSnapshot
|
|
||||||
label: Automatically Cleanup System Generated Snapshot
|
|
||||||
description: "This setting enables Longhorn to automatically cleanup the system generated snapshot after replica rebuild is done."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: boolean
|
|
||||||
default: "true"
|
|
||||||
- variable: defaultSettings.concurrentAutomaticEngineUpgradePerNodeLimit
|
|
||||||
label: Concurrent Automatic Engine Upgrade Per Node Limit
|
|
||||||
description: "This setting controls how Longhorn automatically upgrades volumes' engines to the new default engine image after upgrading Longhorn manager. The value of this setting specifies the maximum number of engines per node that are allowed to upgrade to the default engine image at the same time. If the value is 0, Longhorn will not automatically upgrade volumes' engines to default version."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: int
|
|
||||||
min: 0
|
|
||||||
default: 0
|
|
||||||
- variable: defaultSettings.backingImageCleanupWaitInterval
|
|
||||||
label: Backing Image Cleanup Wait Interval
|
|
||||||
description: "This interval in minutes determines how long Longhorn will wait before cleaning up the backing image file when there is no replica in the disk using it."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: int
|
|
||||||
min: 0
|
|
||||||
default: 60
|
|
||||||
- variable: defaultSettings.backingImageRecoveryWaitInterval
|
|
||||||
label: Backing Image Recovery Wait Interval
|
|
||||||
description: "This interval in seconds determines how long Longhorn will wait before re-downloading the backing image file when all disk files of this backing image become failed or unknown."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: int
|
|
||||||
min: 0
|
|
||||||
default: 300
|
|
||||||
- variable: defaultSettings.guaranteedInstanceManagerCPU
|
|
||||||
label: Guaranteed Instance Manager CPU
|
|
||||||
description: "This integer value indicates how many percentage of the total allocatable CPU on each node will be reserved for each instance manager Pod. You can leave it with the default value, which is 12%."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: int
|
|
||||||
min: 0
|
|
||||||
max: 40
|
|
||||||
default: 12
|
|
||||||
- variable: defaultSettings.logLevel
|
|
||||||
label: Log Level
|
|
||||||
description: "The log level Panic, Fatal, Error, Warn, Info, Debug, Trace used in longhorn manager. Default to Info."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: string
|
|
||||||
default: "Info"
|
|
||||||
- variable: defaultSettings.kubernetesClusterAutoscalerEnabled
|
|
||||||
label: Kubernetes Cluster Autoscaler Enabled (Experimental)
|
|
||||||
description: "Enabling this setting will notify Longhorn that the cluster is using Kubernetes Cluster Autoscaler."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: boolean
|
|
||||||
default: false
|
|
||||||
- variable: defaultSettings.orphanAutoDeletion
|
|
||||||
label: Orphaned Data Cleanup
|
|
||||||
description: "This setting allows Longhorn to delete the orphan resource and its corresponding orphaned data automatically like stale replicas. Orphan resources on down or unknown nodes will not be cleaned up automatically."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: boolean
|
|
||||||
default: false
|
|
||||||
- variable: defaultSettings.storageNetwork
|
|
||||||
label: Storage Network
|
|
||||||
description: "Longhorn uses the storage network for in-cluster data traffic. Leave this blank to use the Kubernetes cluster network."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: string
|
|
||||||
default:
|
|
||||||
- variable: defaultSettings.deletingConfirmationFlag
|
|
||||||
label: Deleting Confirmation Flag
|
|
||||||
description: "This flag is designed to prevent Longhorn from being accidentally uninstalled which will lead to data lost."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: boolean
|
|
||||||
default: "false"
|
|
||||||
- variable: defaultSettings.engineReplicaTimeout
|
|
||||||
label: Timeout between Engine and Replica
|
|
||||||
description: "In seconds. The setting specifies the timeout between the engine and replica(s), and the value should be between 8 to 30 seconds. The default value is 8 seconds."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: int
|
|
||||||
default: "8"
|
|
||||||
- variable: defaultSettings.snapshotDataIntegrity
|
|
||||||
label: Snapshot Data Integrity
|
|
||||||
description: "This setting allows users to enable or disable snapshot hashing and data integrity checking."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: string
|
|
||||||
default: "disabled"
|
|
||||||
- variable: defaultSettings.snapshotDataIntegrityImmediateCheckAfterSnapshotCreation
|
|
||||||
label: Immediate Snapshot Data Integrity Check After Creating a Snapshot
|
|
||||||
description: "Hashing snapshot disk files impacts the performance of the system. The immediate snapshot hashing and checking can be disabled to minimize the impact after creating a snapshot."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: boolean
|
|
||||||
default: "false"
|
|
||||||
- variable: defaultSettings.snapshotDataIntegrityCronjob
|
|
||||||
label: Snapshot Data Integrity Check CronJob
|
|
||||||
description: "Unix-cron string format. The setting specifies when Longhorn checks the data integrity of snapshot disk files."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: string
|
|
||||||
default: "0 0 */7 * *"
|
|
||||||
- variable: defaultSettings.removeSnapshotsDuringFilesystemTrim
|
|
||||||
label: Remove Snapshots During Filesystem Trim
|
|
||||||
description: "This setting allows Longhorn filesystem trim feature to automatically mark the latest snapshot and its ancestors as removed and stops at the snapshot containing multiple children."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: boolean
|
|
||||||
default: "false"
|
|
||||||
- variable: defaultSettings.fastReplicaRebuildEnabled
|
|
||||||
label: Fast Replica Rebuild Enabled
|
|
||||||
description: "This feature supports the fast replica rebuilding. It relies on the checksum of snapshot disk files, so setting the snapshot-data-integrity to **enable** or **fast-check** is a prerequisite."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: boolean
|
|
||||||
default: false
|
|
||||||
- variable: defaultSettings.replicaFileSyncHttpClientTimeout
|
|
||||||
label: Timeout of HTTP Client to Replica File Sync Server
|
|
||||||
description: "In seconds. The setting specifies the HTTP client timeout to the file sync server."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: int
|
|
||||||
default: "30"
|
|
||||||
- variable: defaultSettings.backupCompressionMethod
|
|
||||||
label: Backup Compression Method
|
|
||||||
description: "This setting allows users to specify backup compression method."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: string
|
|
||||||
default: "lz4"
|
|
||||||
- variable: defaultSettings.backupConcurrentLimit
|
|
||||||
label: Backup Concurrent Limit Per Backup
|
|
||||||
description: "This setting controls how many worker threads per backup concurrently."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: int
|
|
||||||
min: 1
|
|
||||||
default: 2
|
|
||||||
- variable: defaultSettings.restoreConcurrentLimit
|
|
||||||
label: Restore Concurrent Limit Per Backup
|
|
||||||
description: "This setting controls how many worker threads per restore concurrently."
|
|
||||||
group: "Longhorn Default Settings"
|
|
||||||
type: int
|
|
||||||
min: 1
|
|
||||||
default: 2
|
|
||||||
- variable: defaultSettings.v2DataEngine
|
|
||||||
label: V2 Data Engine
|
|
||||||
description: "This allows users to activate v2 data engine based on SPDK. Currently, it is in the preview phase and should not be utilized in a production environment."
|
|
||||||
group: "Longhorn V2 Data Engine (Preview Feature) Settings"
|
|
||||||
type: boolean
|
|
||||||
default: false
|
|
||||||
- variable: defaultSettings.offlineReplicaRebuilding
|
|
||||||
label: Offline Replica Rebuilding
|
|
||||||
description: "This setting allows users to enable the offline replica rebuilding for volumes using v2 data engine."
|
|
||||||
group: "Longhorn V2 Data Engine (Preview Feature) Settings"
|
|
||||||
required: true
|
|
||||||
type: enum
|
|
||||||
options:
|
|
||||||
- "enabled"
|
|
||||||
- "disabled"
|
|
||||||
default: "enabled"
|
|
||||||
- variable: persistence.defaultClass
|
|
||||||
default: "true"
|
|
||||||
description: "Set as default StorageClass for Longhorn"
|
|
||||||
label: Default Storage Class
|
|
||||||
group: "Longhorn Storage Class Settings"
|
|
||||||
required: true
|
|
||||||
type: boolean
|
|
||||||
- variable: persistence.reclaimPolicy
|
|
||||||
label: Storage Class Retain Policy
|
|
||||||
description: "Define reclaim policy. Options: `Retain`, `Delete`"
|
|
||||||
group: "Longhorn Storage Class Settings"
|
|
||||||
required: true
|
|
||||||
type: enum
|
|
||||||
options:
|
|
||||||
- "Delete"
|
|
||||||
- "Retain"
|
|
||||||
default: "Delete"
|
|
||||||
- variable: persistence.defaultClassReplicaCount
|
|
||||||
description: "Set replica count for Longhorn StorageClass"
|
|
||||||
label: Default Storage Class Replica Count
|
|
||||||
group: "Longhorn Storage Class Settings"
|
|
||||||
type: int
|
|
||||||
min: 1
|
|
||||||
max: 10
|
|
||||||
default: 3
|
|
||||||
- variable: persistence.defaultDataLocality
|
|
||||||
description: "Set data locality for Longhorn StorageClass. Options: `disabled`, `best-effort`"
|
|
||||||
label: Default Storage Class Data Locality
|
|
||||||
group: "Longhorn Storage Class Settings"
|
|
||||||
type: enum
|
|
||||||
options:
|
|
||||||
- "disabled"
|
|
||||||
- "best-effort"
|
|
||||||
default: "disabled"
|
|
||||||
- variable: persistence.recurringJobSelector.enable
|
|
||||||
description: "Enable recurring job selector for Longhorn StorageClass"
|
|
||||||
group: "Longhorn Storage Class Settings"
|
|
||||||
label: Enable Storage Class Recurring Job Selector
|
|
||||||
type: boolean
|
|
||||||
default: false
|
|
||||||
show_subquestion_if: true
|
|
||||||
subquestions:
|
|
||||||
- variable: persistence.recurringJobSelector.jobList
|
|
||||||
description: 'Recurring job selector list for Longhorn StorageClass. Please be careful of quotes of input. e.g., [{"name":"backup", "isGroup":true}]'
|
|
||||||
label: Storage Class Recurring Job Selector List
|
|
||||||
group: "Longhorn Storage Class Settings"
|
|
||||||
type: string
|
|
||||||
default:
|
|
||||||
- variable: persistence.defaultNodeSelector.enable
|
|
||||||
description: "Enable Node selector for Longhorn StorageClass"
|
|
||||||
group: "Longhorn Storage Class Settings"
|
|
||||||
label: Enable Storage Class Node Selector
|
|
||||||
type: boolean
|
|
||||||
default: false
|
|
||||||
show_subquestion_if: true
|
|
||||||
subquestions:
|
|
||||||
- variable: persistence.defaultNodeSelector.selector
|
|
||||||
label: Storage Class Node Selector
|
|
||||||
description: 'This selector enables only certain nodes having these tags to be used for the volume. e.g. `"storage,fast"`'
|
|
||||||
group: "Longhorn Storage Class Settings"
|
|
||||||
type: string
|
|
||||||
default:
|
|
||||||
- variable: persistence.backingImage.enable
|
|
||||||
description: "Set backing image for Longhorn StorageClass"
|
|
||||||
group: "Longhorn Storage Class Settings"
|
|
||||||
label: Default Storage Class Backing Image
|
|
||||||
type: boolean
|
|
||||||
default: false
|
|
||||||
show_subquestion_if: true
|
|
||||||
subquestions:
|
|
||||||
- variable: persistence.backingImage.name
|
|
||||||
description: 'Specify a backing image that will be used by Longhorn volumes in Longhorn StorageClass. If not exists, the backing image data source type and backing image data source parameters should be specified so that Longhorn will create the backing image before using it.'
|
|
||||||
label: Storage Class Backing Image Name
|
|
||||||
group: "Longhorn Storage Class Settings"
|
|
||||||
type: string
|
|
||||||
default:
|
|
||||||
- variable: persistence.backingImage.expectedChecksum
|
|
||||||
description: 'Specify the expected SHA512 checksum of the selected backing image in Longhorn StorageClass.
|
|
||||||
WARNING:
|
|
||||||
- If the backing image name is not specified, setting this field is meaningless.
|
|
||||||
- It is not recommended to set this field if the data source type is \"export-from-volume\".'
|
|
||||||
label: Storage Class Backing Image Expected SHA512 Checksum
|
|
||||||
group: "Longhorn Storage Class Settings"
|
|
||||||
type: string
|
|
||||||
default:
|
|
||||||
- variable: persistence.backingImage.dataSourceType
|
|
||||||
description: 'Specify the data source type for the backing image used in Longhorn StorageClass.
|
|
||||||
If the backing image does not exists, Longhorn will use this field to create a backing image. Otherwise, Longhorn will use it to verify the selected backing image.
|
|
||||||
WARNING:
|
|
||||||
- If the backing image name is not specified, setting this field is meaningless.
|
|
||||||
- As for backing image creation with data source type \"upload\", it is recommended to do it via UI rather than StorageClass here. Uploading requires file data sending to the Longhorn backend after the object creation, which is complicated if you want to handle it manually.'
|
|
||||||
label: Storage Class Backing Image Data Source Type
|
|
||||||
group: "Longhorn Storage Class Settings"
|
|
||||||
type: enum
|
|
||||||
options:
|
|
||||||
- ""
|
|
||||||
- "download"
|
|
||||||
- "upload"
|
|
||||||
- "export-from-volume"
|
|
||||||
default: ""
|
|
||||||
- variable: persistence.backingImage.dataSourceParameters
|
|
||||||
description: "Specify the data source parameters for the backing image used in Longhorn StorageClass.
|
|
||||||
If the backing image does not exists, Longhorn will use this field to create a backing image. Otherwise, Longhorn will use it to verify the selected backing image.
|
|
||||||
This option accepts a json string of a map. e.g., '{\"url\":\"https://backing-image-example.s3-region.amazonaws.com/test-backing-image\"}'.
|
|
||||||
WARNING:
|
|
||||||
- If the backing image name is not specified, setting this field is meaningless.
|
|
||||||
- Be careful of the quotes here."
|
|
||||||
label: Storage Class Backing Image Data Source Parameters
|
|
||||||
group: "Longhorn Storage Class Settings"
|
|
||||||
type: string
|
|
||||||
default:
|
|
||||||
- variable: persistence.removeSnapshotsDuringFilesystemTrim
|
|
||||||
description: "Allow automatically removing snapshots during filesystem trim for Longhorn StorageClass. Options: `ignored`, `enabled`, `disabled`"
|
|
||||||
label: Default Storage Class Remove Snapshots During Filesystem Trim
|
|
||||||
group: "Longhorn Storage Class Settings"
|
|
||||||
type: enum
|
|
||||||
options:
|
|
||||||
- "ignored"
|
|
||||||
- "enabled"
|
|
||||||
- "disabled"
|
|
||||||
default: "ignored"
|
|
||||||
- variable: ingress.enabled
|
|
||||||
default: "false"
|
|
||||||
description: "Expose app using Layer 7 Load Balancer - ingress"
|
|
||||||
type: boolean
|
|
||||||
group: "Services and Load Balancing"
|
|
||||||
label: Expose app using Layer 7 Load Balancer
|
|
||||||
show_subquestion_if: true
|
|
||||||
subquestions:
|
|
||||||
- variable: ingress.host
|
|
||||||
default: "xip.io"
|
|
||||||
description: "layer 7 Load Balancer hostname"
|
|
||||||
type: hostname
|
|
||||||
required: true
|
|
||||||
label: Layer 7 Load Balancer Hostname
|
|
||||||
- variable: ingress.path
|
|
||||||
default: "/"
|
|
||||||
description: "If ingress is enabled you can set the default ingress path"
|
|
||||||
type: string
|
|
||||||
required: true
|
|
||||||
label: Ingress Path
|
|
||||||
- variable: service.ui.type
|
|
||||||
default: "Rancher-Proxy"
|
|
||||||
description: "Define Longhorn UI service type. Options: `ClusterIP`, `NodePort`, `LoadBalancer`, `Rancher-Proxy`"
|
|
||||||
type: enum
|
|
||||||
options:
|
|
||||||
- "ClusterIP"
|
|
||||||
- "NodePort"
|
|
||||||
- "LoadBalancer"
|
|
||||||
- "Rancher-Proxy"
|
|
||||||
label: Longhorn UI Service
|
|
||||||
show_if: "ingress.enabled=false"
|
|
||||||
group: "Services and Load Balancing"
|
|
||||||
show_subquestion_if: "NodePort"
|
|
||||||
subquestions:
|
|
||||||
- variable: service.ui.nodePort
|
|
||||||
default: ""
|
|
||||||
description: "NodePort port number(to set explicitly, choose port between 30000-32767)"
|
|
||||||
type: int
|
|
||||||
min: 30000
|
|
||||||
max: 32767
|
|
||||||
show_if: "service.ui.type=NodePort||service.ui.type=LoadBalancer"
|
|
||||||
label: UI Service NodePort number
|
|
||||||
- variable: enablePSP
|
|
||||||
default: "false"
|
|
||||||
description: "Setup a pod security policy for Longhorn workloads."
|
|
||||||
label: Pod Security Policy
|
|
||||||
type: boolean
|
|
||||||
group: "Other Settings"
|
|
||||||
- variable: global.cattle.windowsCluster.enabled
|
|
||||||
default: "false"
|
|
||||||
description: "Enable this to allow Longhorn to run on the Rancher deployed Windows cluster."
|
|
||||||
label: Rancher Windows Cluster
|
|
||||||
type: boolean
|
|
||||||
group: "Other Settings"
|
|
||||||
- variable: networkPolicies.enabled
|
|
||||||
description: "Enable NetworkPolicies to limit access to the longhorn pods.
|
|
||||||
Warning: The Rancher Proxy will not work if this feature is enabled and a custom NetworkPolicy must be added."
|
|
||||||
group: "Other Settings"
|
|
||||||
label: Network Policies
|
|
||||||
default: "false"
|
|
||||||
type: boolean
|
|
||||||
subquestions:
|
|
||||||
- variable: networkPolicies.type
|
|
||||||
label: Network Policies for Ingress
|
|
||||||
description: "Create the policy based on your distribution to allow access for the ingress. Options: `k3s`, `rke2`, `rke1`"
|
|
||||||
show_if: "networkPolicies.enabled=true&&ingress.enabled=true"
|
|
||||||
type: enum
|
|
||||||
default: "rke2"
|
|
||||||
options:
|
|
||||||
- "rke1"
|
|
||||||
- "rke2"
|
|
||||||
- "k3s"
|
|
||||||
512
chart/questions.yml
Normal file
512
chart/questions.yml
Normal file
@ -0,0 +1,512 @@
|
|||||||
|
categories:
|
||||||
|
- storage
|
||||||
|
namespace: longhorn-system
|
||||||
|
questions:
|
||||||
|
- variable: image.defaultImage
|
||||||
|
default: "true"
|
||||||
|
description: "Use default Longhorn images"
|
||||||
|
label: Use Default Images
|
||||||
|
type: boolean
|
||||||
|
show_subquestion_if: false
|
||||||
|
group: "Longhorn Images"
|
||||||
|
subquestions:
|
||||||
|
- variable: image.longhorn.manager.repository
|
||||||
|
default: longhornio/longhorn-manager
|
||||||
|
description: "Specify Longhorn Manager Image Repository"
|
||||||
|
type: string
|
||||||
|
label: Longhorn Manager Image Repository
|
||||||
|
group: "Longhorn Images Settings"
|
||||||
|
- variable: image.longhorn.manager.tag
|
||||||
|
default: v1.1.0
|
||||||
|
description: "Specify Longhorn Manager Image Tag"
|
||||||
|
type: string
|
||||||
|
label: Longhorn Manager Image Tag
|
||||||
|
group: "Longhorn Images Settings"
|
||||||
|
- variable: image.longhorn.engine.repository
|
||||||
|
default: longhornio/longhorn-engine
|
||||||
|
description: "Specify Longhorn Engine Image Repository"
|
||||||
|
type: string
|
||||||
|
label: Longhorn Engine Image Repository
|
||||||
|
group: "Longhorn Images Settings"
|
||||||
|
- variable: image.longhorn.engine.tag
|
||||||
|
default: v1.1.0
|
||||||
|
description: "Specify Longhorn Engine Image Tag"
|
||||||
|
type: string
|
||||||
|
label: Longhorn Engine Image Tag
|
||||||
|
group: "Longhorn Images Settings"
|
||||||
|
- variable: image.longhorn.ui.repository
|
||||||
|
default: longhornio/longhorn-ui
|
||||||
|
description: "Specify Longhorn UI Image Repository"
|
||||||
|
type: string
|
||||||
|
label: Longhorn UI Image Repository
|
||||||
|
group: "Longhorn Images Settings"
|
||||||
|
- variable: image.longhorn.ui.tag
|
||||||
|
default: v1.1.0
|
||||||
|
description: "Specify Longhorn UI Image Tag"
|
||||||
|
type: string
|
||||||
|
label: Longhorn UI Image Tag
|
||||||
|
group: "Longhorn Images Settings"
|
||||||
|
- variable: image.longhorn.instanceManager.repository
|
||||||
|
default: longhornio/longhorn-instance-manager
|
||||||
|
description: "Specify Longhorn Instance Manager Image Repository"
|
||||||
|
type: string
|
||||||
|
label: Longhorn Instance Manager Image Repository
|
||||||
|
group: "Longhorn Images Settings"
|
||||||
|
- variable: image.longhorn.instanceManager.tag
|
||||||
|
default: v1_20201216
|
||||||
|
description: "Specify Longhorn Instance Manager Image Tag"
|
||||||
|
type: string
|
||||||
|
label: Longhorn Instance Manager Image Tag
|
||||||
|
group: "Longhorn Images Settings"
|
||||||
|
- variable: image.longhorn.shareManager.repository
|
||||||
|
default: longhornio/longhorn-share-manager
|
||||||
|
description: "Specify Longhorn Share Manager Image Repository"
|
||||||
|
type: string
|
||||||
|
label: Longhorn Share Manager Image Repository
|
||||||
|
group: "Longhorn Images Settings"
|
||||||
|
- variable: image.longhorn.shareManager.tag
|
||||||
|
default: v1_20201204
|
||||||
|
description: "Specify Longhorn Share Manager Image Tag"
|
||||||
|
type: string
|
||||||
|
label: Longhorn Share Manager Image Tag
|
||||||
|
group: "Longhorn Images Settings"
|
||||||
|
- variable: image.csi.attacher.repository
|
||||||
|
default: longhornio/csi-attacher
|
||||||
|
description: "Specify CSI attacher image repository. Leave blank to autodetect."
|
||||||
|
type: string
|
||||||
|
label: Longhorn CSI Attacher Image Repository
|
||||||
|
group: "Longhorn CSI Driver Images"
|
||||||
|
- variable: image.csi.attacher.tag
|
||||||
|
default: v2.2.1-lh1
|
||||||
|
description: "Specify CSI attacher image tag. Leave blank to autodetect."
|
||||||
|
type: string
|
||||||
|
label: Longhorn CSI Attacher Image Tag
|
||||||
|
group: "Longhorn CSI Driver Images"
|
||||||
|
- variable: image.csi.provisioner.repository
|
||||||
|
default: longhornio/csi-provisioner
|
||||||
|
description: "Specify CSI provisioner image repository. Leave blank to autodetect."
|
||||||
|
type: string
|
||||||
|
label: Longhorn CSI Provisioner Image Repository
|
||||||
|
group: "Longhorn CSI Driver Images"
|
||||||
|
- variable: image.csi.provisioner.tag
|
||||||
|
default: v1.6.0-lh1
|
||||||
|
description: "Specify CSI provisioner image tag. Leave blank to autodetect."
|
||||||
|
type: string
|
||||||
|
label: Longhorn CSI Provisioner Image Tag
|
||||||
|
group: "Longhorn CSI Driver Images"
|
||||||
|
- variable: image.csi.nodeDriverRegistrar.repository
|
||||||
|
default: longhornio/csi-node-driver-registrar
|
||||||
|
description: "Specify CSI Node Driver Registrar image repository. Leave blank to autodetect."
|
||||||
|
type: string
|
||||||
|
label: Longhorn CSI Node Driver Registrar Image Repository
|
||||||
|
group: "Longhorn CSI Driver Images"
|
||||||
|
- variable: image.csi.nodeDriverRegistrar.tag
|
||||||
|
default: v1.2.0-lh1
|
||||||
|
description: "Specify CSI Node Driver Registrar image tag. Leave blank to autodetect."
|
||||||
|
type: string
|
||||||
|
label: Longhorn CSI Node Driver Registrar Image Tag
|
||||||
|
group: "Longhorn CSI Driver Images"
|
||||||
|
- variable: image.csi.resizer.repository
|
||||||
|
default: longhornio/csi-resizer
|
||||||
|
description: "Specify CSI Driver Resizer image repository. Leave blank to autodetect."
|
||||||
|
type: string
|
||||||
|
label: Longhorn CSI Driver Resizer Image Repository
|
||||||
|
group: "Longhorn CSI Driver Images"
|
||||||
|
- variable: image.csi.resizer.tag
|
||||||
|
default: v0.5.1-lh1
|
||||||
|
description: "Specify CSI Driver Resizer image tag. Leave blank to autodetect."
|
||||||
|
type: string
|
||||||
|
label: Longhorn CSI Driver Resizer Image Tag
|
||||||
|
group: "Longhorn CSI Driver Images"
|
||||||
|
- variable: image.csi.snapshotter.repository
|
||||||
|
default: longhornio/csi-snapshotter
|
||||||
|
description: "Specify CSI Driver Snapshotter image repository. Leave blank to autodetect."
|
||||||
|
type: string
|
||||||
|
label: Longhorn CSI Driver Snapshotter Image Repository
|
||||||
|
group: "Longhorn CSI Driver Images"
|
||||||
|
- variable: image.csi.snapshotter.tag
|
||||||
|
default: v2.1.1-lh1
|
||||||
|
description: "Specify CSI Driver Snapshotter image tag. Leave blank to autodetect."
|
||||||
|
type: string
|
||||||
|
label: Longhorn CSI Driver Snapshotter Image Tag
|
||||||
|
group: "Longhorn CSI Driver Images"
|
||||||
|
- variable: privateRegistry.registryUrl
|
||||||
|
label: Private registry URL
|
||||||
|
description: "URL of private registry. Leave blank to apply system default registry."
|
||||||
|
group: "Private Registry Settings"
|
||||||
|
type: string
|
||||||
|
default: ""
|
||||||
|
- variable: privateRegistry.registryUser
|
||||||
|
label: Private registry user
|
||||||
|
description: "User used to authenticate to private registry"
|
||||||
|
group: "Private Registry Settings"
|
||||||
|
type: string
|
||||||
|
default: ""
|
||||||
|
- variable: privateRegistry.registryPasswd
|
||||||
|
label: Private registry password
|
||||||
|
description: "Password used to authenticate to private registry"
|
||||||
|
group: "Private Registry Settings"
|
||||||
|
type: password
|
||||||
|
default: ""
|
||||||
|
- variable: privateRegistry.registrySecret
|
||||||
|
label: Private registry secret name
|
||||||
|
description: "Longhorn will automatically generate a Kubernetes secret with this name and use it to pull images from your private registry."
|
||||||
|
group: "Private Registry Settings"
|
||||||
|
type: string
|
||||||
|
default: ""
|
||||||
|
- variable: longhorn.default_setting
|
||||||
|
default: "false"
|
||||||
|
description: "Customize the default settings before installing Longhorn for the first time. This option will only work if the cluster hasn't installed Longhorn."
|
||||||
|
label: "Customize Default Settings"
|
||||||
|
type: boolean
|
||||||
|
show_subquestion_if: true
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
subquestions:
|
||||||
|
- variable: csi.kubeletRootDir
|
||||||
|
default:
|
||||||
|
description: "Specify kubelet root-dir. Leave blank to autodetect."
|
||||||
|
type: string
|
||||||
|
label: Kubelet Root Directory
|
||||||
|
group: "Longhorn CSI Driver Settings"
|
||||||
|
- variable: csi.attacherReplicaCount
|
||||||
|
type: int
|
||||||
|
default: 3
|
||||||
|
min: 1
|
||||||
|
max: 10
|
||||||
|
description: "Specify replica count of CSI Attacher. By default 3."
|
||||||
|
label: Longhorn CSI Attacher replica count
|
||||||
|
group: "Longhorn CSI Driver Settings"
|
||||||
|
- variable: csi.provisionerReplicaCount
|
||||||
|
type: int
|
||||||
|
default: 3
|
||||||
|
min: 1
|
||||||
|
max: 10
|
||||||
|
description: "Specify replica count of CSI Provisioner. By default 3."
|
||||||
|
label: Longhorn CSI Provisioner replica count
|
||||||
|
group: "Longhorn CSI Driver Settings"
|
||||||
|
- variable: csi.resizerReplicaCount
|
||||||
|
type: int
|
||||||
|
default: 3
|
||||||
|
min: 1
|
||||||
|
max: 10
|
||||||
|
description: "Specify replica count of CSI Resizer. By default 3."
|
||||||
|
label: Longhorn CSI Resizer replica count
|
||||||
|
group: "Longhorn CSI Driver Settings"
|
||||||
|
- variable: csi.snapshotterReplicaCount
|
||||||
|
type: int
|
||||||
|
default: 3
|
||||||
|
min: 1
|
||||||
|
max: 10
|
||||||
|
description: "Specify replica count of CSI Snapshotter. By default 3."
|
||||||
|
label: Longhorn CSI Snapshotter replica count
|
||||||
|
group: "Longhorn CSI Driver Settings"
|
||||||
|
- variable: defaultSettings.backupTarget
|
||||||
|
label: Backup Target
|
||||||
|
description: "The endpoint used to access the backupstore. NFS and S3 are supported."
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: string
|
||||||
|
default:
|
||||||
|
- variable: defaultSettings.backupTargetCredentialSecret
|
||||||
|
label: Backup Target Credential Secret
|
||||||
|
description: "The name of the Kubernetes secret associated with the backup target."
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: string
|
||||||
|
default:
|
||||||
|
- variable: defaultSettings.allowRecurringJobWhileVolumeDetached
|
||||||
|
label: Allow Recurring Job While Volume Is Detached
|
||||||
|
description: 'If this setting is enabled, Longhorn will automatically attaches the volume and takes snapshot/backup when it is the time to do recurring snapshot/backup.
|
||||||
|
Note that the volume is not ready for workload during the period when the volume was automatically attached. Workload will have to wait until the recurring job finishes.'
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: boolean
|
||||||
|
default: "false"
|
||||||
|
- variable: defaultSettings.createDefaultDiskLabeledNodes
|
||||||
|
label: Create Default Disk on Labeled Nodes
|
||||||
|
description: 'Create default Disk automatically only on Nodes with the label "node.longhorn.io/create-default-disk=true" if no other disks exist. If disabled, the default disk will be created on all new nodes when each node is first added.'
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: boolean
|
||||||
|
default: "false"
|
||||||
|
- variable: defaultSettings.defaultDataPath
|
||||||
|
label: Default Data Path
|
||||||
|
description: 'Default path to use for storing data on a host. By default "/var/lib/longhorn/"'
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: string
|
||||||
|
default: "/var/lib/longhorn/"
|
||||||
|
- variable: defaultSettings.defaultDataLocality
|
||||||
|
label: Default Data Locality
|
||||||
|
description: 'We say a Longhorn volume has data locality if there is a local replica of the volume on the same node as the pod which is using the volume.
|
||||||
|
This setting specifies the default data locality when a volume is created from the Longhorn UI. For Kubernetes configuration, update the `dataLocality` in the StorageClass
|
||||||
|
The available modes are:
|
||||||
|
- **disabled**. This is the default option. There may or may not be a replica on the same node as the attached volume (workload)
|
||||||
|
- **best-effort**. This option instructs Longhorn to try to keep a replica on the same node as the attached volume (workload). Longhorn will not stop the volume, even if it cannot keep a replica local to the attached volume (workload) due to environment limitation, e.g. not enough disk space, incompatible disk tags, etc.'
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: enum
|
||||||
|
options:
|
||||||
|
- "disabled"
|
||||||
|
- "best-effort"
|
||||||
|
default: "disabled"
|
||||||
|
- variable: defaultSettings.replicaSoftAntiAffinity
|
||||||
|
label: Replica Node Level Soft Anti-Affinity
|
||||||
|
description: 'Allow scheduling on nodes with existing healthy replicas of the same volume. By default false.'
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: boolean
|
||||||
|
default: "false"
|
||||||
|
- variable: defaultSettings.storageOverProvisioningPercentage
|
||||||
|
label: Storage Over Provisioning Percentage
|
||||||
|
description: "The over-provisioning percentage defines how much storage can be allocated relative to the hard drive's capacity. By default 200."
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: int
|
||||||
|
min: 0
|
||||||
|
default: 200
|
||||||
|
- variable: defaultSettings.storageMinimalAvailablePercentage
|
||||||
|
label: Storage Minimal Available Percentage
|
||||||
|
description: "If the minimum available disk capacity exceeds the actual percentage of available disk capacity, the disk becomes unschedulable until more space is freed up. By default 25."
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: int
|
||||||
|
min: 0
|
||||||
|
max: 100
|
||||||
|
default: 25
|
||||||
|
- variable: defaultSettings.upgradeChecker
|
||||||
|
label: Enable Upgrade Checker
|
||||||
|
description: 'Upgrade Checker will check for new Longhorn version periodically. When there is a new version available, a notification will appear in the UI. By default true.'
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: boolean
|
||||||
|
default: "true"
|
||||||
|
- variable: defaultSettings.defaultReplicaCount
|
||||||
|
label: Default Replica Count
|
||||||
|
description: "The default number of replicas when a volume is created from the Longhorn UI. For Kubernetes configuration, update the `numberOfReplicas` in the StorageClass. By default 3."
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: int
|
||||||
|
min: 1
|
||||||
|
max: 20
|
||||||
|
default: 3
|
||||||
|
- variable: defaultSettings.guaranteedEngineCPU
|
||||||
|
label: Guaranteed Engine CPU
|
||||||
|
description: "Allow Longhorn Instance Managers to have guaranteed CPU allocation. By default 0.25. The value is how many CPUs should be reserved for each Engine/Replica Instance Manager Pod created by Longhorn. For example, 0.1 means one-tenth of a CPU. This will help maintain engine stability during high node workload. It only applies to the Engine/Replica Instance Manager Pods created after the setting took effect.
|
||||||
|
In order to prevent unexpected volume crash, you can use the following formula to calculate an appropriate value for this setting:
|
||||||
|
'Guaranteed Engine CPU = The estimated max Longhorn volume/replica count on a node * 0.1'.
|
||||||
|
The result of above calculation doesn't mean that's the maximum CPU resources the Longhorn workloads require. To fully exploit the Longhorn volume I/O performance, you can allocate/guarantee more CPU resources via this setting.
|
||||||
|
If it's hard to estimate the volume/replica count now, you can leave it with the default value, or allocate 1/8 of total CPU of a node. Then you can tune it when there is no running workload using Longhorn volumes.
|
||||||
|
WARNING: After this setting is changed, all the instance managers on all the nodes will be automatically restarted
|
||||||
|
WARNING: DO NOT CHANGE THIS SETTING WITH ATTACHED VOLUMES."
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: float
|
||||||
|
default: 0.25
|
||||||
|
- variable: defaultSettings.defaultLonghornStaticStorageClass
|
||||||
|
label: Default Longhorn Static StorageClass Name
|
||||||
|
description: "The 'storageClassName' is given to PVs and PVCs that are created for an existing Longhorn volume. The StorageClass name can also be used as a label, so it is possible to use a Longhorn StorageClass to bind a workload to an existing PV without creating a Kubernetes StorageClass object. By default 'longhorn-static'."
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: string
|
||||||
|
default: "longhorn-static"
|
||||||
|
- variable: defaultSettings.backupstorePollInterval
|
||||||
|
label: Backupstore Poll Interval
|
||||||
|
description: "In seconds. The backupstore poll interval determines how often Longhorn checks the backupstore for new backups. Set to 0 to disable the polling. By default 300."
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: int
|
||||||
|
min: 0
|
||||||
|
default: 300
|
||||||
|
- variable: defaultSettings.taintToleration
|
||||||
|
label: Kubernetes Taint Toleration
|
||||||
|
description: "To dedicate nodes to store Longhorn replicas and reject other general workloads, set tolerations for Longhorn and add taints for the storage nodes.
|
||||||
|
All Longhorn volumes should be detached before modifying toleration settings.
|
||||||
|
We recommend setting tolerations during Longhorn deployment because the Longhorn system cannot be operated during the update.
|
||||||
|
Multiple tolerations can be set here, and these tolerations are separated by semicolon. For example:
|
||||||
|
* `key1=value1:NoSchedule; key2:NoExecute`
|
||||||
|
* `:` this toleration tolerates everything because an empty key with operator `Exists` matches all keys, values and effects
|
||||||
|
* `key1=value1:` this toleration has empty effect. It matches all effects with key `key1`
|
||||||
|
Because `kubernetes.io` is used as the key of all Kubernetes default tolerations, it should not be used in the toleration settings.
|
||||||
|
WARNING: DO NOT CHANGE THIS SETTING WITH ATTACHED VOLUMES!"
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: string
|
||||||
|
default: ""
|
||||||
|
- variable: defaultSettings.priorityClass
|
||||||
|
label: Priority Class
|
||||||
|
description: "The name of the Priority Class to set on the Longhorn workloads. This can help prevent Longhorn workloads from being evicted under Node Pressure. WARNING: DO NOT CHANGE THIS SETTING WITH ATTACHED VOLUMES."
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: string
|
||||||
|
default: ""
|
||||||
|
- variable: defaultSettings.autoSalvage
|
||||||
|
label: Automatic salvage
|
||||||
|
description: "If enabled, volumes will be automatically salvaged when all the replicas become faulty e.g. due to network disconnection. Longhorn will try to figure out which replica(s) are usable, then use them for the volume. By default true."
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: boolean
|
||||||
|
default: "true"
|
||||||
|
- variable: defaultSettings.autoDeletePodWhenVolumeDetachedUnexpectedly
|
||||||
|
label: Automatically Delete Workload Pod when The Volume Is Detached Unexpectedly
|
||||||
|
description: 'If enabled, Longhorn will automatically delete the workload pod that is managed by a controller (e.g. deployment, statefulset, daemonset, etc...) when Longhorn volume is detached unexpectedly (e.g. during Kubernetes upgrade, Docker reboot, or network disconnect). By deleting the pod, its controller restarts the pod and Kubernetes handles volume reattachment and remount.
|
||||||
|
If disabled, Longhorn will not delete the workload pod that is managed by a controller. You will have to manually restart the pod to reattach and remount the volume.
|
||||||
|
**Note:** This setting does not apply to the workload pods that do not have a controller. Longhorn never deletes them.'
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: boolean
|
||||||
|
default: "true"
|
||||||
|
- variable: defaultSettings.disableSchedulingOnCordonedNode
|
||||||
|
label: Disable Scheduling On Cordoned Node
|
||||||
|
description: "Disable Longhorn manager to schedule replica on Kubernetes cordoned node. By default true."
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: boolean
|
||||||
|
default: "true"
|
||||||
|
- variable: defaultSettings.replicaZoneSoftAntiAffinity
|
||||||
|
label: Replica Zone Level Soft Anti-Affinity
|
||||||
|
description: "Allow scheduling new Replicas of Volume to the Nodes in the same Zone as existing healthy Replicas. Nodes don't belong to any Zone will be treated as in the same Zone. By default true."
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: boolean
|
||||||
|
default: "true"
|
||||||
|
- variable: defaultSettings.volumeAttachmentRecoveryPolicy
|
||||||
|
label: Volume Attachment Recovery Policy
|
||||||
|
description: "Defines the Longhorn action when a Volume is stuck with a Deployment Pod on a failed node. `wait` leads to the deletion of the volume attachment as soon as the pods deletion time has passed. `never` is the default Kubernetes behavior of never deleting volume attachments on terminating pods. `immediate` leads to the deletion of the volume attachment as soon as all workload pods are pending. By default wait."
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: enum
|
||||||
|
options:
|
||||||
|
- "wait"
|
||||||
|
- "never"
|
||||||
|
- "immediate"
|
||||||
|
default: "wait"
|
||||||
|
- variable: defaultSettings.nodeDownPodDeletionPolicy
|
||||||
|
label: Pod Deletion Policy When Node is Down
|
||||||
|
description: "Defines the Longhorn action when a Volume is stuck with a StatefulSet/Deployment Pod on a node that is down.
|
||||||
|
- **do-nothing** is the default Kubernetes behavior of never force deleting StatefulSet/Deployment terminating pods. Since the pod on the node that is down isn't removed, Longhorn volumes are stuck on nodes that are down.
|
||||||
|
- **delete-statefulset-pod** Longhorn will force delete StatefulSet terminating pods on nodes that are down to release Longhorn volumes so that Kubernetes can spin up replacement pods.
|
||||||
|
- **delete-deployment-pod** Longhorn will force delete Deployment terminating pods on nodes that are down to release Longhorn volumes so that Kubernetes can spin up replacement pods.
|
||||||
|
- **delete-both-statefulset-and-deployment-pod** Longhorn will force delete StatefulSet/Deployment terminating pods on nodes that are down to release Longhorn volumes so that Kubernetes can spin up replacement pods."
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: enum
|
||||||
|
options:
|
||||||
|
- "do-nothing"
|
||||||
|
- "delete-statefulset-pod"
|
||||||
|
- "delete-deployment-pod"
|
||||||
|
- "delete-both-statefulset-and-deployment-pod"
|
||||||
|
default: "do-nothing"
|
||||||
|
- variable: defaultSettings.allowNodeDrainWithLastHealthyReplica
|
||||||
|
label: Allow Node Drain with the Last Healthy Replica
|
||||||
|
description: "By default, Longhorn will block `kubectl drain` action on a node if the node contains the last healthy replica of a volume.
|
||||||
|
If this setting is enabled, Longhorn will **not** block `kubectl drain` action on a node even if the node contains the last healthy replica of a volume."
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: boolean
|
||||||
|
default: "false"
|
||||||
|
- variable: defaultSettings.mkfsExt4Parameters
|
||||||
|
label: Custom mkfs.ext4 parameters
|
||||||
|
description: "Allows setting additional filesystem creation parameters for ext4. For older host kernels it might be necessary to disable the optional ext4 metadata_csum feature by specifying `-O ^64bit,^metadata_csum`."
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: string
|
||||||
|
- variable: defaultSettings.disableReplicaRebuild
|
||||||
|
label: Disable Replica Rebuild
|
||||||
|
description: "This setting disable replica rebuild cross the whole cluster, eviction and data locality feature won't work if this setting is true. But doesn't have any impact to any current replica rebuild and restore disaster recovery volume."
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: boolean
|
||||||
|
default: "false"
|
||||||
|
- variable: defaultSettings.replicaReplenishmentWaitInterval
|
||||||
|
label: Replica Replenishment Wait Interval
|
||||||
|
description: "In seconds. The interval determines how long Longhorn will wait at least in order to reuse the existing data on a failed replica rather than directly creating a new replica for a degraded volume.
|
||||||
|
Warning: This option works only when there is a failed replica in the volume. And this option may block the rebuilding for a while in the case."
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: int
|
||||||
|
min: 0
|
||||||
|
default: 600
|
||||||
|
- variable: defaultSettings.disableRevisionCounter
|
||||||
|
label: Disable Revision Counter
|
||||||
|
description: "This setting is only for volumes created by UI. By default, this is false meaning there will be a reivision counter file to track every write to the volume. During salvage recovering Longhorn will pick the repica with largest reivision counter as candidate to recover the whole volume. If revision counter is disabled, Longhorn will not track every write to the volume. During the salvage recovering, Longhorn will use the 'volume-head-xxx.img' file last modification time and file size to pick the replica candidate to recover the whole volume."
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: boolean
|
||||||
|
default: "false"
|
||||||
|
- variable: defaultSettings.systemManagedPodsImagePullPolicy
|
||||||
|
label: System Managed Pod Image Pull Policy
|
||||||
|
description: "This setting defines the Image Pull Policy of Longhorn system managed pods, e.g. instance manager, engine image, CSI driver, etc. The new Image Pull Policy will only apply after the system managed pods restart."
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: enum
|
||||||
|
options:
|
||||||
|
- "if-not-present"
|
||||||
|
- "always"
|
||||||
|
- "never"
|
||||||
|
default: "if-not-present"
|
||||||
|
- variable: defaultSettings.allowVolumeCreationWithDegradedAvailability
|
||||||
|
label: Allow Volume Creation with Degraded Availability
|
||||||
|
description: "This setting allows user to create and attach a volume that doesn't have all the replicas scheduled at the time of creation."
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: boolean
|
||||||
|
default: "true"
|
||||||
|
- variable: defaultSettings.autoCleanupSystemGeneratedSnapshot
|
||||||
|
label: Automatically Cleanup System Generated Snapshot
|
||||||
|
description: "This setting enables Longhorn to automatically cleanup the system generated snapshot after replica rebuild is done."
|
||||||
|
group: "Longhorn Default Settings"
|
||||||
|
type: boolean
|
||||||
|
default: "true"
|
||||||
|
- variable: persistence.defaultClass
|
||||||
|
default: "true"
|
||||||
|
description: "Set as default StorageClass for Longhorn"
|
||||||
|
label: Default Storage Class
|
||||||
|
group: "Longhorn Storage Class Settings"
|
||||||
|
required: true
|
||||||
|
type: boolean
|
||||||
|
- variable: persistence.reclaimPolicy
|
||||||
|
label: Storage Class Retain Policy
|
||||||
|
description: "Define reclaim policy (Retain or Delete)"
|
||||||
|
group: "Longhorn Storage Class Settings"
|
||||||
|
required: true
|
||||||
|
type: enum
|
||||||
|
options:
|
||||||
|
- "Delete"
|
||||||
|
- "Retain"
|
||||||
|
default: "Delete"
|
||||||
|
- variable: persistence.defaultClassReplicaCount
|
||||||
|
description: "Set replica count for Longhorn StorageClass"
|
||||||
|
label: Default Storage Class Replica Count
|
||||||
|
group: "Longhorn Storage Class Settings"
|
||||||
|
type: int
|
||||||
|
min: 1
|
||||||
|
max: 10
|
||||||
|
default: 3
|
||||||
|
- variable: persistence.recurringJobs.enable
|
||||||
|
description: "Enable recurring job for Longhorn StorageClass"
|
||||||
|
group: "Longhorn Storage Class Settings"
|
||||||
|
label: Enable Storage Class Recurring Job
|
||||||
|
type: boolean
|
||||||
|
default: false
|
||||||
|
show_subquestion_if: true
|
||||||
|
subquestions:
|
||||||
|
- variable: persistence.recurringJobs.jobList
|
||||||
|
description: 'Recurring job list for Longhorn StorageClass. Please be careful of quotes of input. e.g., [{"name":"backup", "task":"backup", "cron":"*/2 * * * *", "retain":1,"labels": {"interval":"2m"}}]'
|
||||||
|
label: Storage Class Recurring Job List
|
||||||
|
group: "Longhorn Storage Class Settings"
|
||||||
|
type: string
|
||||||
|
default:
|
||||||
|
- variable: ingress.enabled
|
||||||
|
default: "false"
|
||||||
|
description: "Expose app using Layer 7 Load Balancer - ingress"
|
||||||
|
type: boolean
|
||||||
|
group: "Services and Load Balancing"
|
||||||
|
label: Expose app using Layer 7 Load Balancer
|
||||||
|
show_subquestion_if: true
|
||||||
|
subquestions:
|
||||||
|
- variable: ingress.host
|
||||||
|
default: "xip.io"
|
||||||
|
description: "layer 7 Load Balancer hostname"
|
||||||
|
type: hostname
|
||||||
|
required: true
|
||||||
|
label: Layer 7 Load Balancer Hostname
|
||||||
|
- variable: service.ui.type
|
||||||
|
default: "Rancher-Proxy"
|
||||||
|
description: "Define Longhorn UI service type"
|
||||||
|
type: enum
|
||||||
|
options:
|
||||||
|
- "ClusterIP"
|
||||||
|
- "NodePort"
|
||||||
|
- "LoadBalancer"
|
||||||
|
- "Rancher-Proxy"
|
||||||
|
label: Longhorn UI Service
|
||||||
|
show_if: "ingress.enabled=false"
|
||||||
|
group: "Services and Load Balancing"
|
||||||
|
show_subquestion_if: "NodePort"
|
||||||
|
subquestions:
|
||||||
|
- variable: service.ui.nodePort
|
||||||
|
default: ""
|
||||||
|
description: "NodePort port number(to set explicitly, choose port between 30000-32767)"
|
||||||
|
type: int
|
||||||
|
min: 30000
|
||||||
|
max: 32767
|
||||||
|
show_if: "service.ui.type=NodePort||service.ui.type=LoadBalancer"
|
||||||
|
label: UI Service NodePort number
|
||||||
|
- variable: enablePSP
|
||||||
|
default: "true"
|
||||||
|
description: "Setup a pod security policy for Longhorn workloads."
|
||||||
|
label: Pod Security Policy
|
||||||
|
type: boolean
|
||||||
|
group: "Other Settings"
|
||||||
@ -11,7 +11,7 @@ rules:
|
|||||||
verbs:
|
verbs:
|
||||||
- "*"
|
- "*"
|
||||||
- apiGroups: [""]
|
- apiGroups: [""]
|
||||||
resources: ["pods", "events", "persistentvolumes", "persistentvolumeclaims","persistentvolumeclaims/status", "nodes", "proxy/nodes", "pods/log", "secrets", "services", "endpoints", "configmaps", "serviceaccounts"]
|
resources: ["pods", "events", "persistentvolumes", "persistentvolumeclaims","persistentvolumeclaims/status", "nodes", "proxy/nodes", "pods/log", "secrets", "services", "endpoints", "configmaps"]
|
||||||
verbs: ["*"]
|
verbs: ["*"]
|
||||||
- apiGroups: [""]
|
- apiGroups: [""]
|
||||||
resources: ["namespaces"]
|
resources: ["namespaces"]
|
||||||
@ -23,13 +23,13 @@ rules:
|
|||||||
resources: ["jobs", "cronjobs"]
|
resources: ["jobs", "cronjobs"]
|
||||||
verbs: ["*"]
|
verbs: ["*"]
|
||||||
- apiGroups: ["policy"]
|
- apiGroups: ["policy"]
|
||||||
resources: ["poddisruptionbudgets", "podsecuritypolicies"]
|
resources: ["poddisruptionbudgets"]
|
||||||
verbs: ["*"]
|
verbs: ["*"]
|
||||||
- apiGroups: ["scheduling.k8s.io"]
|
- apiGroups: ["scheduling.k8s.io"]
|
||||||
resources: ["priorityclasses"]
|
resources: ["priorityclasses"]
|
||||||
verbs: ["watch", "list"]
|
verbs: ["watch", "list"]
|
||||||
- apiGroups: ["storage.k8s.io"]
|
- apiGroups: ["storage.k8s.io"]
|
||||||
resources: ["storageclasses", "volumeattachments", "volumeattachments/status", "csinodes", "csidrivers"]
|
resources: ["storageclasses", "volumeattachments", "csinodes", "csidrivers"]
|
||||||
verbs: ["*"]
|
verbs: ["*"]
|
||||||
- apiGroups: ["snapshot.storage.k8s.io"]
|
- apiGroups: ["snapshot.storage.k8s.io"]
|
||||||
resources: ["volumesnapshotclasses", "volumesnapshots", "volumesnapshotcontents", "volumesnapshotcontents/status"]
|
resources: ["volumesnapshotclasses", "volumesnapshots", "volumesnapshotcontents", "volumesnapshotcontents/status"]
|
||||||
@ -37,15 +37,7 @@ rules:
|
|||||||
- apiGroups: ["longhorn.io"]
|
- apiGroups: ["longhorn.io"]
|
||||||
resources: ["volumes", "volumes/status", "engines", "engines/status", "replicas", "replicas/status", "settings",
|
resources: ["volumes", "volumes/status", "engines", "engines/status", "replicas", "replicas/status", "settings",
|
||||||
"engineimages", "engineimages/status", "nodes", "nodes/status", "instancemanagers", "instancemanagers/status",
|
"engineimages", "engineimages/status", "nodes", "nodes/status", "instancemanagers", "instancemanagers/status",
|
||||||
{{- if .Values.openshift.enabled }}
|
"sharemanagers", "sharemanagers/status"]
|
||||||
"engineimages/finalizers", "nodes/finalizers", "instancemanagers/finalizers",
|
|
||||||
{{- end }}
|
|
||||||
"sharemanagers", "sharemanagers/status", "backingimages", "backingimages/status",
|
|
||||||
"backingimagemanagers", "backingimagemanagers/status", "backingimagedatasources", "backingimagedatasources/status",
|
|
||||||
"backuptargets", "backuptargets/status", "backupvolumes", "backupvolumes/status", "backups", "backups/status",
|
|
||||||
"recurringjobs", "recurringjobs/status", "orphans", "orphans/status", "snapshots", "snapshots/status",
|
|
||||||
"supportbundles", "supportbundles/status", "systembackups", "systembackups/status", "systemrestores", "systemrestores/status",
|
|
||||||
"volumeattachments", "volumeattachments/status"]
|
|
||||||
verbs: ["*"]
|
verbs: ["*"]
|
||||||
- apiGroups: ["coordination.k8s.io"]
|
- apiGroups: ["coordination.k8s.io"]
|
||||||
resources: ["leases"]
|
resources: ["leases"]
|
||||||
@ -53,25 +45,3 @@ rules:
|
|||||||
- apiGroups: ["metrics.k8s.io"]
|
- apiGroups: ["metrics.k8s.io"]
|
||||||
resources: ["pods", "nodes"]
|
resources: ["pods", "nodes"]
|
||||||
verbs: ["get", "list"]
|
verbs: ["get", "list"]
|
||||||
- apiGroups: ["apiregistration.k8s.io"]
|
|
||||||
resources: ["apiservices"]
|
|
||||||
verbs: ["list", "watch"]
|
|
||||||
- apiGroups: ["admissionregistration.k8s.io"]
|
|
||||||
resources: ["mutatingwebhookconfigurations", "validatingwebhookconfigurations"]
|
|
||||||
verbs: ["get", "list", "create", "patch", "delete"]
|
|
||||||
- apiGroups: ["rbac.authorization.k8s.io"]
|
|
||||||
resources: ["roles", "rolebindings", "clusterrolebindings", "clusterroles"]
|
|
||||||
verbs: ["*"]
|
|
||||||
{{- if .Values.openshift.enabled }}
|
|
||||||
---
|
|
||||||
apiVersion: rbac.authorization.k8s.io/v1
|
|
||||||
kind: ClusterRole
|
|
||||||
metadata:
|
|
||||||
name: longhorn-ocp-privileged-role
|
|
||||||
labels: {{- include "longhorn.labels" . | nindent 4 }}
|
|
||||||
rules:
|
|
||||||
- apiGroups: ["security.openshift.io"]
|
|
||||||
resources: ["securitycontextconstraints"]
|
|
||||||
resourceNames: ["anyuid", "privileged"]
|
|
||||||
verbs: ["use"]
|
|
||||||
{{- end }}
|
|
||||||
|
|||||||
@ -11,39 +11,3 @@ subjects:
|
|||||||
- kind: ServiceAccount
|
- kind: ServiceAccount
|
||||||
name: longhorn-service-account
|
name: longhorn-service-account
|
||||||
namespace: {{ include "release_namespace" . }}
|
namespace: {{ include "release_namespace" . }}
|
||||||
---
|
|
||||||
apiVersion: rbac.authorization.k8s.io/v1
|
|
||||||
kind: ClusterRoleBinding
|
|
||||||
metadata:
|
|
||||||
name: longhorn-support-bundle
|
|
||||||
labels: {{- include "longhorn.labels" . | nindent 4 }}
|
|
||||||
roleRef:
|
|
||||||
apiGroup: rbac.authorization.k8s.io
|
|
||||||
kind: ClusterRole
|
|
||||||
name: cluster-admin
|
|
||||||
subjects:
|
|
||||||
- kind: ServiceAccount
|
|
||||||
name: longhorn-support-bundle
|
|
||||||
namespace: {{ include "release_namespace" . }}
|
|
||||||
{{- if .Values.openshift.enabled }}
|
|
||||||
---
|
|
||||||
apiVersion: rbac.authorization.k8s.io/v1
|
|
||||||
kind: ClusterRoleBinding
|
|
||||||
metadata:
|
|
||||||
name: longhorn-ocp-privileged-bind
|
|
||||||
labels: {{- include "longhorn.labels" . | nindent 4 }}
|
|
||||||
roleRef:
|
|
||||||
apiGroup: rbac.authorization.k8s.io
|
|
||||||
kind: ClusterRole
|
|
||||||
name: longhorn-ocp-privileged-role
|
|
||||||
subjects:
|
|
||||||
- kind: ServiceAccount
|
|
||||||
name: longhorn-service-account
|
|
||||||
namespace: {{ include "release_namespace" . }}
|
|
||||||
- kind: ServiceAccount
|
|
||||||
name: longhorn-ui-service-account
|
|
||||||
namespace: {{ include "release_namespace" . }}
|
|
||||||
- kind: ServiceAccount
|
|
||||||
name: default # supportbundle-agent-support-bundle uses default sa
|
|
||||||
namespace: {{ include "release_namespace" . }}
|
|
||||||
{{- end }}
|
|
||||||
|
|||||||
File diff suppressed because it is too large
Load Diff
@ -13,23 +13,16 @@ spec:
|
|||||||
metadata:
|
metadata:
|
||||||
labels: {{- include "longhorn.labels" . | nindent 8 }}
|
labels: {{- include "longhorn.labels" . | nindent 8 }}
|
||||||
app: longhorn-manager
|
app: longhorn-manager
|
||||||
{{- with .Values.annotations }}
|
|
||||||
annotations:
|
|
||||||
{{- toYaml . | nindent 8 }}
|
|
||||||
{{- end }}
|
|
||||||
spec:
|
spec:
|
||||||
containers:
|
containers:
|
||||||
- name: longhorn-manager
|
- name: longhorn-manager
|
||||||
image: {{ template "registry_url" . }}{{ .Values.image.longhorn.manager.repository }}:{{ .Values.image.longhorn.manager.tag }}
|
image: {{ template "registry_url" . }}{{ .Values.image.longhorn.manager.repository }}:{{ .Values.image.longhorn.manager.tag }}
|
||||||
imagePullPolicy: {{ .Values.image.pullPolicy }}
|
imagePullPolicy: IfNotPresent
|
||||||
securityContext:
|
securityContext:
|
||||||
privileged: true
|
privileged: true
|
||||||
command:
|
command:
|
||||||
- longhorn-manager
|
- longhorn-manager
|
||||||
- -d
|
- -d
|
||||||
{{- if eq .Values.longhornManager.log.format "json" }}
|
|
||||||
- -j
|
|
||||||
{{- end }}
|
|
||||||
- daemon
|
- daemon
|
||||||
- --engine-image
|
- --engine-image
|
||||||
- "{{ template "registry_url" . }}{{ .Values.image.longhorn.engine.repository }}:{{ .Values.image.longhorn.engine.tag }}"
|
- "{{ template "registry_url" . }}{{ .Values.image.longhorn.engine.repository }}:{{ .Values.image.longhorn.engine.tag }}"
|
||||||
@ -37,10 +30,6 @@ spec:
|
|||||||
- "{{ template "registry_url" . }}{{ .Values.image.longhorn.instanceManager.repository }}:{{ .Values.image.longhorn.instanceManager.tag }}"
|
- "{{ template "registry_url" . }}{{ .Values.image.longhorn.instanceManager.repository }}:{{ .Values.image.longhorn.instanceManager.tag }}"
|
||||||
- --share-manager-image
|
- --share-manager-image
|
||||||
- "{{ template "registry_url" . }}{{ .Values.image.longhorn.shareManager.repository }}:{{ .Values.image.longhorn.shareManager.tag }}"
|
- "{{ template "registry_url" . }}{{ .Values.image.longhorn.shareManager.repository }}:{{ .Values.image.longhorn.shareManager.tag }}"
|
||||||
- --backing-image-manager-image
|
|
||||||
- "{{ template "registry_url" . }}{{ .Values.image.longhorn.backingImageManager.repository }}:{{ .Values.image.longhorn.backingImageManager.tag }}"
|
|
||||||
- --support-bundle-manager-image
|
|
||||||
- "{{ template "registry_url" . }}{{ .Values.image.longhorn.supportBundleKit.repository }}:{{ .Values.image.longhorn.supportBundleKit.tag }}"
|
|
||||||
- --manager-image
|
- --manager-image
|
||||||
- "{{ template "registry_url" . }}{{ .Values.image.longhorn.manager.repository }}:{{ .Values.image.longhorn.manager.tag }}"
|
- "{{ template "registry_url" . }}{{ .Values.image.longhorn.manager.repository }}:{{ .Values.image.longhorn.manager.tag }}"
|
||||||
- --service-account
|
- --service-account
|
||||||
@ -48,27 +37,22 @@ spec:
|
|||||||
ports:
|
ports:
|
||||||
- containerPort: 9500
|
- containerPort: 9500
|
||||||
name: manager
|
name: manager
|
||||||
- containerPort: 9501
|
|
||||||
name: conversion-wh
|
|
||||||
- containerPort: 9502
|
|
||||||
name: admission-wh
|
|
||||||
- containerPort: 9503
|
|
||||||
name: recov-backend
|
|
||||||
readinessProbe:
|
readinessProbe:
|
||||||
httpGet:
|
tcpSocket:
|
||||||
path: /v1/healthz
|
port: 9500
|
||||||
port: 9501
|
|
||||||
scheme: HTTPS
|
|
||||||
volumeMounts:
|
volumeMounts:
|
||||||
- name: dev
|
- name: dev
|
||||||
mountPath: /host/dev/
|
mountPath: /host/dev/
|
||||||
- name: proc
|
- name: proc
|
||||||
mountPath: /host/proc/
|
mountPath: /host/proc/
|
||||||
|
- name: varrun
|
||||||
|
mountPath: /var/run/
|
||||||
|
mountPropagation: Bidirectional
|
||||||
- name: longhorn
|
- name: longhorn
|
||||||
mountPath: /var/lib/longhorn/
|
mountPath: /var/lib/longhorn/
|
||||||
mountPropagation: Bidirectional
|
mountPropagation: Bidirectional
|
||||||
- name: longhorn-grpc-tls
|
- name: longhorn-default-setting
|
||||||
mountPath: /tls-files/
|
mountPath: /var/lib/longhorn-setting/
|
||||||
env:
|
env:
|
||||||
- name: POD_NAMESPACE
|
- name: POD_NAMESPACE
|
||||||
valueFrom:
|
valueFrom:
|
||||||
@ -82,6 +66,8 @@ spec:
|
|||||||
valueFrom:
|
valueFrom:
|
||||||
fieldRef:
|
fieldRef:
|
||||||
fieldPath: spec.nodeName
|
fieldPath: spec.nodeName
|
||||||
|
- name: DEFAULT_SETTING_PATH
|
||||||
|
value: /var/lib/longhorn-setting/default-setting.yaml
|
||||||
volumes:
|
volumes:
|
||||||
- name: dev
|
- name: dev
|
||||||
hostPath:
|
hostPath:
|
||||||
@ -89,38 +75,19 @@ spec:
|
|||||||
- name: proc
|
- name: proc
|
||||||
hostPath:
|
hostPath:
|
||||||
path: /proc/
|
path: /proc/
|
||||||
|
- name: varrun
|
||||||
|
hostPath:
|
||||||
|
path: /var/run/
|
||||||
- name: longhorn
|
- name: longhorn
|
||||||
hostPath:
|
hostPath:
|
||||||
path: /var/lib/longhorn/
|
path: /var/lib/longhorn/
|
||||||
- name: longhorn-grpc-tls
|
- name: longhorn-default-setting
|
||||||
secret:
|
configMap:
|
||||||
secretName: longhorn-grpc-tls
|
name: longhorn-default-setting
|
||||||
optional: true
|
|
||||||
{{- if .Values.privateRegistry.registrySecret }}
|
{{- if .Values.privateRegistry.registrySecret }}
|
||||||
imagePullSecrets:
|
imagePullSecrets:
|
||||||
- name: {{ .Values.privateRegistry.registrySecret }}
|
- name: {{ .Values.privateRegistry.registrySecret }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
{{- if .Values.longhornManager.priorityClass }}
|
|
||||||
priorityClassName: {{ .Values.longhornManager.priorityClass | quote }}
|
|
||||||
{{- end }}
|
|
||||||
{{- if or .Values.longhornManager.tolerations .Values.global.cattle.windowsCluster.enabled }}
|
|
||||||
tolerations:
|
|
||||||
{{- if and .Values.global.cattle.windowsCluster.enabled .Values.global.cattle.windowsCluster.tolerations }}
|
|
||||||
{{ toYaml .Values.global.cattle.windowsCluster.tolerations | indent 6 }}
|
|
||||||
{{- end }}
|
|
||||||
{{- if .Values.longhornManager.tolerations }}
|
|
||||||
{{ toYaml .Values.longhornManager.tolerations | indent 6 }}
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
{{- if or .Values.longhornManager.nodeSelector .Values.global.cattle.windowsCluster.enabled }}
|
|
||||||
nodeSelector:
|
|
||||||
{{- if and .Values.global.cattle.windowsCluster.enabled .Values.global.cattle.windowsCluster.nodeSelector }}
|
|
||||||
{{ toYaml .Values.global.cattle.windowsCluster.nodeSelector | indent 8 }}
|
|
||||||
{{- end }}
|
|
||||||
{{- if .Values.longhornManager.nodeSelector }}
|
|
||||||
{{ toYaml .Values.longhornManager.nodeSelector | indent 8 }}
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
serviceAccountName: longhorn-service-account
|
serviceAccountName: longhorn-service-account
|
||||||
updateStrategy:
|
updateStrategy:
|
||||||
rollingUpdate:
|
rollingUpdate:
|
||||||
@ -133,10 +100,6 @@ metadata:
|
|||||||
app: longhorn-manager
|
app: longhorn-manager
|
||||||
name: longhorn-backend
|
name: longhorn-backend
|
||||||
namespace: {{ include "release_namespace" . }}
|
namespace: {{ include "release_namespace" . }}
|
||||||
{{- if .Values.longhornManager.serviceAnnotations }}
|
|
||||||
annotations:
|
|
||||||
{{ toYaml .Values.longhornManager.serviceAnnotations | indent 4 }}
|
|
||||||
{{- end }}
|
|
||||||
spec:
|
spec:
|
||||||
type: {{ .Values.service.manager.type }}
|
type: {{ .Values.service.manager.type }}
|
||||||
sessionAffinity: ClientIP
|
sessionAffinity: ClientIP
|
||||||
|
|||||||
@ -6,81 +6,33 @@ metadata:
|
|||||||
labels: {{- include "longhorn.labels" . | nindent 4 }}
|
labels: {{- include "longhorn.labels" . | nindent 4 }}
|
||||||
data:
|
data:
|
||||||
default-setting.yaml: |-
|
default-setting.yaml: |-
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.backupTarget) }}backup-target: {{ .Values.defaultSettings.backupTarget }}{{ end }}
|
backup-target: {{ .Values.defaultSettings.backupTarget }}
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.backupTargetCredentialSecret) }}backup-target-credential-secret: {{ .Values.defaultSettings.backupTargetCredentialSecret }}{{ end }}
|
backup-target-credential-secret: {{ .Values.defaultSettings.backupTargetCredentialSecret }}
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.allowRecurringJobWhileVolumeDetached) }}allow-recurring-job-while-volume-detached: {{ .Values.defaultSettings.allowRecurringJobWhileVolumeDetached }}{{ end }}
|
allow-recurring-job-while-volume-detached: {{ .Values.defaultSettings.allowRecurringJobWhileVolumeDetached }}
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.createDefaultDiskLabeledNodes) }}create-default-disk-labeled-nodes: {{ .Values.defaultSettings.createDefaultDiskLabeledNodes }}{{ end }}
|
create-default-disk-labeled-nodes: {{ .Values.defaultSettings.createDefaultDiskLabeledNodes }}
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.defaultDataPath) }}default-data-path: {{ .Values.defaultSettings.defaultDataPath }}{{ end }}
|
default-data-path: {{ .Values.defaultSettings.defaultDataPath }}
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.replicaSoftAntiAffinity) }}replica-soft-anti-affinity: {{ .Values.defaultSettings.replicaSoftAntiAffinity }}{{ end }}
|
replica-soft-anti-affinity: {{ .Values.defaultSettings.replicaSoftAntiAffinity }}
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.replicaAutoBalance) }}replica-auto-balance: {{ .Values.defaultSettings.replicaAutoBalance }}{{ end }}
|
storage-over-provisioning-percentage: {{ .Values.defaultSettings.storageOverProvisioningPercentage }}
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.storageOverProvisioningPercentage) }}storage-over-provisioning-percentage: {{ .Values.defaultSettings.storageOverProvisioningPercentage }}{{ end }}
|
storage-minimal-available-percentage: {{ .Values.defaultSettings.storageMinimalAvailablePercentage }}
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.storageMinimalAvailablePercentage) }}storage-minimal-available-percentage: {{ .Values.defaultSettings.storageMinimalAvailablePercentage }}{{ end }}
|
upgrade-checker: {{ .Values.defaultSettings.upgradeChecker }}
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.storageReservedPercentageForDefaultDisk) }}storage-reserved-percentage-for-default-disk: {{ .Values.defaultSettings.storageReservedPercentageForDefaultDisk }}{{ end }}
|
default-replica-count: {{ .Values.defaultSettings.defaultReplicaCount }}
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.upgradeChecker) }}upgrade-checker: {{ .Values.defaultSettings.upgradeChecker }}{{ end }}
|
default-data-locality: {{ .Values.defaultSettings.defaultDataLocality }}
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.defaultReplicaCount) }}default-replica-count: {{ .Values.defaultSettings.defaultReplicaCount }}{{ end }}
|
guaranteed-engine-cpu: {{ .Values.defaultSettings.guaranteedEngineCPU }}
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.defaultDataLocality) }}default-data-locality: {{ .Values.defaultSettings.defaultDataLocality }}{{ end }}
|
default-longhorn-static-storage-class: {{ .Values.defaultSettings.defaultLonghornStaticStorageClass }}
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.defaultLonghornStaticStorageClass) }}default-longhorn-static-storage-class: {{ .Values.defaultSettings.defaultLonghornStaticStorageClass }}{{ end }}
|
backupstore-poll-interval: {{ .Values.defaultSettings.backupstorePollInterval }}
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.backupstorePollInterval) }}backupstore-poll-interval: {{ .Values.defaultSettings.backupstorePollInterval }}{{ end }}
|
taint-toleration: {{ .Values.defaultSettings.taintToleration }}
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.failedBackupTTL) }}failed-backup-ttl: {{ .Values.defaultSettings.failedBackupTTL }}{{ end }}
|
priority-class: {{ .Values.defaultSettings.priorityClass }}
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.restoreVolumeRecurringJobs) }}restore-volume-recurring-jobs: {{ .Values.defaultSettings.restoreVolumeRecurringJobs }}{{ end }}
|
auto-salvage: {{ .Values.defaultSettings.autoSalvage }}
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.recurringSuccessfulJobsHistoryLimit) }}recurring-successful-jobs-history-limit: {{ .Values.defaultSettings.recurringSuccessfulJobsHistoryLimit }}{{ end }}
|
auto-delete-pod-when-volume-detached-unexpectedly: {{ .Values.defaultSettings.autoDeletePodWhenVolumeDetachedUnexpectedly }}
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.recurringFailedJobsHistoryLimit) }}recurring-failed-jobs-history-limit: {{ .Values.defaultSettings.recurringFailedJobsHistoryLimit }}{{ end }}
|
disable-scheduling-on-cordoned-node: {{ .Values.defaultSettings.disableSchedulingOnCordonedNode }}
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.supportBundleFailedHistoryLimit) }}support-bundle-failed-history-limit: {{ .Values.defaultSettings.supportBundleFailedHistoryLimit }}{{ end }}
|
replica-zone-soft-anti-affinity: {{ .Values.defaultSettings.replicaZoneSoftAntiAffinity }}
|
||||||
{{- if or (not (kindIs "invalid" .Values.defaultSettings.taintToleration)) (.Values.global.cattle.windowsCluster.enabled) }}
|
volume-attachment-recovery-policy: {{ .Values.defaultSettings.volumeAttachmentRecoveryPolicy }}
|
||||||
taint-toleration: {{ $windowsDefaultSettingTaintToleration := list }}{{ $defaultSettingTaintToleration := list -}}
|
node-down-pod-deletion-policy: {{ .Values.defaultSettings.nodeDownPodDeletionPolicy }}
|
||||||
{{- if and .Values.global.cattle.windowsCluster.enabled .Values.global.cattle.windowsCluster.defaultSetting.taintToleration -}}
|
allow-node-drain-with-last-healthy-replica: {{ .Values.defaultSettings.allowNodeDrainWithLastHealthyReplica }}
|
||||||
{{- $windowsDefaultSettingTaintToleration = .Values.global.cattle.windowsCluster.defaultSetting.taintToleration -}}
|
mkfs-ext4-parameters: {{ .Values.defaultSettings.mkfsExt4Parameters }}
|
||||||
{{- end -}}
|
disable-replica-rebuild: {{ .Values.defaultSettings.disableReplicaRebuild }}
|
||||||
{{- if not (kindIs "invalid" .Values.defaultSettings.taintToleration) -}}
|
replica-replenishment-wait-interval: {{ .Values.defaultSettings.replicaReplenishmentWaitInterval }}
|
||||||
{{- $defaultSettingTaintToleration = .Values.defaultSettings.taintToleration -}}
|
disable-revision-counter: {{ .Values.defaultSettings.disableRevisionCounter }}
|
||||||
{{- end -}}
|
system-managed-pods-image-pull-policy: {{ .Values.defaultSettings.systemManagedPodsImagePullPolicy }}
|
||||||
{{- $taintToleration := list $windowsDefaultSettingTaintToleration $defaultSettingTaintToleration }}{{ join ";" (compact $taintToleration) -}}
|
allow-volume-creation-with-degraded-availability: {{ .Values.defaultSettings.allowVolumeCreationWithDegradedAvailability }}
|
||||||
{{- end }}
|
auto-cleanup-system-generated-snapshot: {{ .Values.defaultSettings.autoCleanupSystemGeneratedSnapshot }}
|
||||||
{{- if or (not (kindIs "invalid" .Values.defaultSettings.systemManagedComponentsNodeSelector)) (.Values.global.cattle.windowsCluster.enabled) }}
|
|
||||||
system-managed-components-node-selector: {{ $windowsDefaultSettingNodeSelector := list }}{{ $defaultSettingNodeSelector := list -}}
|
|
||||||
{{- if and .Values.global.cattle.windowsCluster.enabled .Values.global.cattle.windowsCluster.defaultSetting.systemManagedComponentsNodeSelector -}}
|
|
||||||
{{ $windowsDefaultSettingNodeSelector = .Values.global.cattle.windowsCluster.defaultSetting.systemManagedComponentsNodeSelector -}}
|
|
||||||
{{- end -}}
|
|
||||||
{{- if not (kindIs "invalid" .Values.defaultSettings.systemManagedComponentsNodeSelector) -}}
|
|
||||||
{{- $defaultSettingNodeSelector = .Values.defaultSettings.systemManagedComponentsNodeSelector -}}
|
|
||||||
{{- end -}}
|
|
||||||
{{- $nodeSelector := list $windowsDefaultSettingNodeSelector $defaultSettingNodeSelector }}{{ join ";" (compact $nodeSelector) -}}
|
|
||||||
{{- end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.priorityClass) }}priority-class: {{ .Values.defaultSettings.priorityClass }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.autoSalvage) }}auto-salvage: {{ .Values.defaultSettings.autoSalvage }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.autoDeletePodWhenVolumeDetachedUnexpectedly) }}auto-delete-pod-when-volume-detached-unexpectedly: {{ .Values.defaultSettings.autoDeletePodWhenVolumeDetachedUnexpectedly }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.disableSchedulingOnCordonedNode) }}disable-scheduling-on-cordoned-node: {{ .Values.defaultSettings.disableSchedulingOnCordonedNode }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.replicaZoneSoftAntiAffinity) }}replica-zone-soft-anti-affinity: {{ .Values.defaultSettings.replicaZoneSoftAntiAffinity }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.replicaDiskSoftAntiAffinity) }}replica-disk-soft-anti-affinity: {{ .Values.defaultSettings.replicaDiskSoftAntiAffinity }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.nodeDownPodDeletionPolicy) }}node-down-pod-deletion-policy: {{ .Values.defaultSettings.nodeDownPodDeletionPolicy }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.nodeDrainPolicy) }}node-drain-policy: {{ .Values.defaultSettings.nodeDrainPolicy }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.replicaReplenishmentWaitInterval) }}replica-replenishment-wait-interval: {{ .Values.defaultSettings.replicaReplenishmentWaitInterval }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.concurrentReplicaRebuildPerNodeLimit) }}concurrent-replica-rebuild-per-node-limit: {{ .Values.defaultSettings.concurrentReplicaRebuildPerNodeLimit }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.concurrentVolumeBackupRestorePerNodeLimit) }}concurrent-volume-backup-restore-per-node-limit: {{ .Values.defaultSettings.concurrentVolumeBackupRestorePerNodeLimit }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.disableRevisionCounter) }}disable-revision-counter: {{ .Values.defaultSettings.disableRevisionCounter }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.systemManagedPodsImagePullPolicy) }}system-managed-pods-image-pull-policy: {{ .Values.defaultSettings.systemManagedPodsImagePullPolicy }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.allowVolumeCreationWithDegradedAvailability) }}allow-volume-creation-with-degraded-availability: {{ .Values.defaultSettings.allowVolumeCreationWithDegradedAvailability }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.autoCleanupSystemGeneratedSnapshot) }}auto-cleanup-system-generated-snapshot: {{ .Values.defaultSettings.autoCleanupSystemGeneratedSnapshot }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.concurrentAutomaticEngineUpgradePerNodeLimit) }}concurrent-automatic-engine-upgrade-per-node-limit: {{ .Values.defaultSettings.concurrentAutomaticEngineUpgradePerNodeLimit }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.backingImageCleanupWaitInterval) }}backing-image-cleanup-wait-interval: {{ .Values.defaultSettings.backingImageCleanupWaitInterval }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.backingImageRecoveryWaitInterval) }}backing-image-recovery-wait-interval: {{ .Values.defaultSettings.backingImageRecoveryWaitInterval }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.guaranteedInstanceManagerCPU) }}guaranteed-instance-manager-cpu: {{ .Values.defaultSettings.guaranteedInstanceManagerCPU }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.kubernetesClusterAutoscalerEnabled) }}kubernetes-cluster-autoscaler-enabled: {{ .Values.defaultSettings.kubernetesClusterAutoscalerEnabled }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.orphanAutoDeletion) }}orphan-auto-deletion: {{ .Values.defaultSettings.orphanAutoDeletion }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.storageNetwork) }}storage-network: {{ .Values.defaultSettings.storageNetwork }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.deletingConfirmationFlag) }}deleting-confirmation-flag: {{ .Values.defaultSettings.deletingConfirmationFlag }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.engineReplicaTimeout) }}engine-replica-timeout: {{ .Values.defaultSettings.engineReplicaTimeout }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.snapshotDataIntegrity) }}snapshot-data-integrity: {{ .Values.defaultSettings.snapshotDataIntegrity }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.snapshotDataIntegrityImmediateCheckAfterSnapshotCreation) }}snapshot-data-integrity-immediate-check-after-snapshot-creation: {{ .Values.defaultSettings.snapshotDataIntegrityImmediateCheckAfterSnapshotCreation }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.snapshotDataIntegrityCronjob) }}snapshot-data-integrity-cronjob: {{ .Values.defaultSettings.snapshotDataIntegrityCronjob }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.removeSnapshotsDuringFilesystemTrim) }}remove-snapshots-during-filesystem-trim: {{ .Values.defaultSettings.removeSnapshotsDuringFilesystemTrim }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.fastReplicaRebuildEnabled) }}fast-replica-rebuild-enabled: {{ .Values.defaultSettings.fastReplicaRebuildEnabled }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.replicaFileSyncHttpClientTimeout) }}replica-file-sync-http-client-timeout: {{ .Values.defaultSettings.replicaFileSyncHttpClientTimeout }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.logLevel) }}log-level: {{ .Values.defaultSettings.logLevel }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.backupCompressionMethod) }}backup-compression-method: {{ .Values.defaultSettings.backupCompressionMethod }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.backupConcurrentLimit) }}backup-concurrent-limit: {{ .Values.defaultSettings.backupConcurrentLimit }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.restoreConcurrentLimit) }}restore-concurrent-limit: {{ .Values.defaultSettings.restoreConcurrentLimit }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.v2DataEngine) }}v2-data-engine: {{ .Values.defaultSettings.v2DataEngine }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.offlineReplicaRebuilding) }}offline-replica-rebuilding: {{ .Values.defaultSettings.offlineReplicaRebuilding }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.allowEmptyNodeSelectorVolume) }}allow-empty-node-selector-volume: {{ .Values.defaultSettings.allowEmptyNodeSelectorVolume }}{{ end }}
|
|
||||||
{{ if not (kindIs "invalid" .Values.defaultSettings.allowEmptyDiskSelectorVolume) }}allow-empty-disk-selector-volume: {{ .Values.defaultSettings.allowEmptyDiskSelectorVolume }}{{ end }}
|
|
||||||
|
|||||||
@ -21,7 +21,7 @@ spec:
|
|||||||
containers:
|
containers:
|
||||||
- name: longhorn-driver-deployer
|
- name: longhorn-driver-deployer
|
||||||
image: {{ template "registry_url" . }}{{ .Values.image.longhorn.manager.repository }}:{{ .Values.image.longhorn.manager.tag }}
|
image: {{ template "registry_url" . }}{{ .Values.image.longhorn.manager.repository }}:{{ .Values.image.longhorn.manager.tag }}
|
||||||
imagePullPolicy: {{ .Values.image.pullPolicy }}
|
imagePullPolicy: IfNotPresent
|
||||||
command:
|
command:
|
||||||
- longhorn-manager
|
- longhorn-manager
|
||||||
- -d
|
- -d
|
||||||
@ -67,10 +67,6 @@ spec:
|
|||||||
- name: CSI_SNAPSHOTTER_IMAGE
|
- name: CSI_SNAPSHOTTER_IMAGE
|
||||||
value: "{{ template "registry_url" . }}{{ .Values.image.csi.snapshotter.repository }}:{{ .Values.image.csi.snapshotter.tag }}"
|
value: "{{ template "registry_url" . }}{{ .Values.image.csi.snapshotter.repository }}:{{ .Values.image.csi.snapshotter.tag }}"
|
||||||
{{- end }}
|
{{- end }}
|
||||||
{{- if and .Values.image.csi.livenessProbe.repository .Values.image.csi.livenessProbe.tag }}
|
|
||||||
- name: CSI_LIVENESS_PROBE_IMAGE
|
|
||||||
value: "{{ template "registry_url" . }}{{ .Values.image.csi.livenessProbe.repository }}:{{ .Values.image.csi.livenessProbe.tag }}"
|
|
||||||
{{- end }}
|
|
||||||
{{- if .Values.csi.attacherReplicaCount }}
|
{{- if .Values.csi.attacherReplicaCount }}
|
||||||
- name: CSI_ATTACHER_REPLICA_COUNT
|
- name: CSI_ATTACHER_REPLICA_COUNT
|
||||||
value: {{ .Values.csi.attacherReplicaCount | quote }}
|
value: {{ .Values.csi.attacherReplicaCount | quote }}
|
||||||
@ -92,27 +88,6 @@ spec:
|
|||||||
imagePullSecrets:
|
imagePullSecrets:
|
||||||
- name: {{ .Values.privateRegistry.registrySecret }}
|
- name: {{ .Values.privateRegistry.registrySecret }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
{{- if .Values.longhornDriver.priorityClass }}
|
|
||||||
priorityClassName: {{ .Values.longhornDriver.priorityClass | quote }}
|
|
||||||
{{- end }}
|
|
||||||
{{- if or .Values.longhornDriver.tolerations .Values.global.cattle.windowsCluster.enabled }}
|
|
||||||
tolerations:
|
|
||||||
{{- if and .Values.global.cattle.windowsCluster.enabled .Values.global.cattle.windowsCluster.tolerations }}
|
|
||||||
{{ toYaml .Values.global.cattle.windowsCluster.tolerations | indent 6 }}
|
|
||||||
{{- end }}
|
|
||||||
{{- if .Values.longhornDriver.tolerations }}
|
|
||||||
{{ toYaml .Values.longhornDriver.tolerations | indent 6 }}
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
{{- if or .Values.longhornDriver.nodeSelector .Values.global.cattle.windowsCluster.enabled }}
|
|
||||||
nodeSelector:
|
|
||||||
{{- if and .Values.global.cattle.windowsCluster.enabled .Values.global.cattle.windowsCluster.nodeSelector }}
|
|
||||||
{{ toYaml .Values.global.cattle.windowsCluster.nodeSelector | indent 8 }}
|
|
||||||
{{- end }}
|
|
||||||
{{- if .Values.longhornDriver.nodeSelector }}
|
|
||||||
{{ toYaml .Values.longhornDriver.nodeSelector | indent 8 }}
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
serviceAccountName: longhorn-service-account
|
serviceAccountName: longhorn-service-account
|
||||||
securityContext:
|
securityContext:
|
||||||
runAsUser: 0
|
runAsUser: 0
|
||||||
|
|||||||
@ -1,41 +1,3 @@
|
|||||||
{{- if .Values.openshift.enabled }}
|
|
||||||
{{- if .Values.openshift.ui.route }}
|
|
||||||
# https://github.com/openshift/oauth-proxy/blob/master/contrib/sidecar.yaml
|
|
||||||
# Create a proxy service account and ensure it will use the route "proxy"
|
|
||||||
# Create a secure connection to the proxy via a route
|
|
||||||
apiVersion: route.openshift.io/v1
|
|
||||||
kind: Route
|
|
||||||
metadata:
|
|
||||||
labels: {{- include "longhorn.labels" . | nindent 4 }}
|
|
||||||
app: longhorn-ui
|
|
||||||
name: {{ .Values.openshift.ui.route }}
|
|
||||||
namespace: {{ include "release_namespace" . }}
|
|
||||||
spec:
|
|
||||||
to:
|
|
||||||
kind: Service
|
|
||||||
name: longhorn-ui
|
|
||||||
tls:
|
|
||||||
termination: reencrypt
|
|
||||||
---
|
|
||||||
apiVersion: v1
|
|
||||||
kind: Service
|
|
||||||
metadata:
|
|
||||||
labels: {{- include "longhorn.labels" . | nindent 4 }}
|
|
||||||
app: longhorn-ui
|
|
||||||
name: longhorn-ui
|
|
||||||
namespace: {{ include "release_namespace" . }}
|
|
||||||
annotations:
|
|
||||||
service.alpha.openshift.io/serving-cert-secret-name: longhorn-ui-tls
|
|
||||||
spec:
|
|
||||||
ports:
|
|
||||||
- name: longhorn-ui
|
|
||||||
port: {{ .Values.openshift.ui.port | default 443 }}
|
|
||||||
targetPort: {{ .Values.openshift.ui.proxy | default 8443 }}
|
|
||||||
selector:
|
|
||||||
app: longhorn-ui
|
|
||||||
---
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
apiVersion: apps/v1
|
apiVersion: apps/v1
|
||||||
kind: Deployment
|
kind: Deployment
|
||||||
metadata:
|
metadata:
|
||||||
@ -44,7 +6,7 @@ metadata:
|
|||||||
name: longhorn-ui
|
name: longhorn-ui
|
||||||
namespace: {{ include "release_namespace" . }}
|
namespace: {{ include "release_namespace" . }}
|
||||||
spec:
|
spec:
|
||||||
replicas: {{ .Values.longhornUI.replicas }}
|
replicas: 1
|
||||||
selector:
|
selector:
|
||||||
matchLabels:
|
matchLabels:
|
||||||
app: longhorn-ui
|
app: longhorn-ui
|
||||||
@ -53,99 +15,22 @@ spec:
|
|||||||
labels: {{- include "longhorn.labels" . | nindent 8 }}
|
labels: {{- include "longhorn.labels" . | nindent 8 }}
|
||||||
app: longhorn-ui
|
app: longhorn-ui
|
||||||
spec:
|
spec:
|
||||||
serviceAccountName: longhorn-ui-service-account
|
|
||||||
affinity:
|
|
||||||
podAntiAffinity:
|
|
||||||
preferredDuringSchedulingIgnoredDuringExecution:
|
|
||||||
- weight: 1
|
|
||||||
podAffinityTerm:
|
|
||||||
labelSelector:
|
|
||||||
matchExpressions:
|
|
||||||
- key: app
|
|
||||||
operator: In
|
|
||||||
values:
|
|
||||||
- longhorn-ui
|
|
||||||
topologyKey: kubernetes.io/hostname
|
|
||||||
containers:
|
containers:
|
||||||
{{- if .Values.openshift.enabled }}
|
|
||||||
{{- if .Values.openshift.ui.route }}
|
|
||||||
- name: oauth-proxy
|
|
||||||
image: {{ template "registry_url" . }}{{ .Values.image.openshift.oauthProxy.repository }}:{{ .Values.image.openshift.oauthProxy.tag }}
|
|
||||||
imagePullPolicy: IfNotPresent
|
|
||||||
ports:
|
|
||||||
- containerPort: {{ .Values.openshift.ui.proxy | default 8443 }}
|
|
||||||
name: public
|
|
||||||
args:
|
|
||||||
- --https-address=:{{ .Values.openshift.ui.proxy | default 8443 }}
|
|
||||||
- --provider=openshift
|
|
||||||
- --openshift-service-account=longhorn-ui-service-account
|
|
||||||
- --upstream=http://localhost:8000
|
|
||||||
- --tls-cert=/etc/tls/private/tls.crt
|
|
||||||
- --tls-key=/etc/tls/private/tls.key
|
|
||||||
- --cookie-secret=SECRET
|
|
||||||
- --openshift-sar={"namespace":"{{ include "release_namespace" . }}","group":"longhorn.io","resource":"setting","verb":"delete"}
|
|
||||||
volumeMounts:
|
|
||||||
- mountPath: /etc/tls/private
|
|
||||||
name: longhorn-ui-tls
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
- name: longhorn-ui
|
- name: longhorn-ui
|
||||||
image: {{ template "registry_url" . }}{{ .Values.image.longhorn.ui.repository }}:{{ .Values.image.longhorn.ui.tag }}
|
image: {{ template "registry_url" . }}{{ .Values.image.longhorn.ui.repository }}:{{ .Values.image.longhorn.ui.tag }}
|
||||||
imagePullPolicy: {{ .Values.image.pullPolicy }}
|
imagePullPolicy: IfNotPresent
|
||||||
volumeMounts:
|
securityContext:
|
||||||
- name : nginx-cache
|
runAsUser: 0
|
||||||
mountPath: /var/cache/nginx/
|
|
||||||
- name : nginx-config
|
|
||||||
mountPath: /var/config/nginx/
|
|
||||||
- name: var-run
|
|
||||||
mountPath: /var/run/
|
|
||||||
ports:
|
ports:
|
||||||
- containerPort: 8000
|
- containerPort: 8000
|
||||||
name: http
|
name: http
|
||||||
env:
|
env:
|
||||||
- name: LONGHORN_MANAGER_IP
|
- name: LONGHORN_MANAGER_IP
|
||||||
value: "http://longhorn-backend:9500"
|
value: "http://longhorn-backend:9500"
|
||||||
- name: LONGHORN_UI_PORT
|
|
||||||
value: "8000"
|
|
||||||
volumes:
|
|
||||||
{{- if .Values.openshift.enabled }}
|
|
||||||
{{- if .Values.openshift.ui.route }}
|
|
||||||
- name: longhorn-ui-tls
|
|
||||||
secret:
|
|
||||||
secretName: longhorn-ui-tls
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
- emptyDir: {}
|
|
||||||
name: nginx-cache
|
|
||||||
- emptyDir: {}
|
|
||||||
name: nginx-config
|
|
||||||
- emptyDir: {}
|
|
||||||
name: var-run
|
|
||||||
{{- if .Values.privateRegistry.registrySecret }}
|
{{- if .Values.privateRegistry.registrySecret }}
|
||||||
imagePullSecrets:
|
imagePullSecrets:
|
||||||
- name: {{ .Values.privateRegistry.registrySecret }}
|
- name: {{ .Values.privateRegistry.registrySecret }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
{{- if .Values.longhornUI.priorityClass }}
|
|
||||||
priorityClassName: {{ .Values.longhornUI.priorityClass | quote }}
|
|
||||||
{{- end }}
|
|
||||||
{{- if or .Values.longhornUI.tolerations .Values.global.cattle.windowsCluster.enabled }}
|
|
||||||
tolerations:
|
|
||||||
{{- if and .Values.global.cattle.windowsCluster.enabled .Values.global.cattle.windowsCluster.tolerations }}
|
|
||||||
{{ toYaml .Values.global.cattle.windowsCluster.tolerations | indent 6 }}
|
|
||||||
{{- end }}
|
|
||||||
{{- if .Values.longhornUI.tolerations }}
|
|
||||||
{{ toYaml .Values.longhornUI.tolerations | indent 6 }}
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
{{- if or .Values.longhornUI.nodeSelector .Values.global.cattle.windowsCluster.enabled }}
|
|
||||||
nodeSelector:
|
|
||||||
{{- if and .Values.global.cattle.windowsCluster.enabled .Values.global.cattle.windowsCluster.nodeSelector }}
|
|
||||||
{{ toYaml .Values.global.cattle.windowsCluster.nodeSelector | indent 8 }}
|
|
||||||
{{- end }}
|
|
||||||
{{- if .Values.longhornUI.nodeSelector }}
|
|
||||||
{{ toYaml .Values.longhornUI.nodeSelector | indent 8 }}
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
---
|
---
|
||||||
kind: Service
|
kind: Service
|
||||||
apiVersion: v1
|
apiVersion: v1
|
||||||
@ -163,12 +48,6 @@ spec:
|
|||||||
{{- else }}
|
{{- else }}
|
||||||
type: {{ .Values.service.ui.type }}
|
type: {{ .Values.service.ui.type }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
{{- if and .Values.service.ui.loadBalancerIP (eq .Values.service.ui.type "LoadBalancer") }}
|
|
||||||
loadBalancerIP: {{ .Values.service.ui.loadBalancerIP }}
|
|
||||||
{{- end }}
|
|
||||||
{{- if and (eq .Values.service.ui.type "LoadBalancer") .Values.service.ui.loadBalancerSourceRanges }}
|
|
||||||
loadBalancerSourceRanges: {{- toYaml .Values.service.ui.loadBalancerSourceRanges | nindent 4 }}
|
|
||||||
{{- end }}
|
|
||||||
selector:
|
selector:
|
||||||
app: longhorn-ui
|
app: longhorn-ui
|
||||||
ports:
|
ports:
|
||||||
|
|||||||
@ -1,9 +1,5 @@
|
|||||||
{{- if .Values.ingress.enabled }}
|
{{- if .Values.ingress.enabled }}
|
||||||
{{- if semverCompare ">=1.19-0" .Capabilities.KubeVersion.GitVersion -}}
|
apiVersion: extensions/v1beta1
|
||||||
apiVersion: networking.k8s.io/v1
|
|
||||||
{{- else -}}
|
|
||||||
apiVersion: networking.k8s.io/v1beta1
|
|
||||||
{{- end }}
|
|
||||||
kind: Ingress
|
kind: Ingress
|
||||||
metadata:
|
metadata:
|
||||||
name: longhorn-ingress
|
name: longhorn-ingress
|
||||||
@ -11,34 +7,21 @@ metadata:
|
|||||||
labels: {{- include "longhorn.labels" . | nindent 4 }}
|
labels: {{- include "longhorn.labels" . | nindent 4 }}
|
||||||
app: longhorn-ingress
|
app: longhorn-ingress
|
||||||
annotations:
|
annotations:
|
||||||
{{- if .Values.ingress.secureBackends }}
|
{{- if .Values.ingress.tls }}
|
||||||
ingress.kubernetes.io/secure-backends: "true"
|
ingress.kubernetes.io/secure-backends: "true"
|
||||||
{{- end }}
|
{{- end }}
|
||||||
{{- range $key, $value := .Values.ingress.annotations }}
|
{{- range $key, $value := .Values.ingress.annotations }}
|
||||||
{{ $key }}: {{ $value | quote }}
|
{{ $key }}: {{ $value | quote }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
spec:
|
spec:
|
||||||
{{- if and .Values.ingress.ingressClassName (semverCompare ">=1.18-0" .Capabilities.KubeVersion.GitVersion) }}
|
|
||||||
ingressClassName: {{ .Values.ingress.ingressClassName }}
|
|
||||||
{{- end }}
|
|
||||||
rules:
|
rules:
|
||||||
- host: {{ .Values.ingress.host }}
|
- host: {{ .Values.ingress.host }}
|
||||||
http:
|
http:
|
||||||
paths:
|
paths:
|
||||||
- path: {{ default "" .Values.ingress.path }}
|
- path: {{ default "" .Values.ingress.path }}
|
||||||
{{- if (semverCompare ">=1.18-0" $.Capabilities.KubeVersion.GitVersion) }}
|
|
||||||
pathType: ImplementationSpecific
|
|
||||||
{{- end }}
|
|
||||||
backend:
|
backend:
|
||||||
{{- if semverCompare ">=1.19-0" $.Capabilities.KubeVersion.GitVersion }}
|
|
||||||
service:
|
|
||||||
name: longhorn-frontend
|
|
||||||
port:
|
|
||||||
number: 80
|
|
||||||
{{- else }}
|
|
||||||
serviceName: longhorn-frontend
|
serviceName: longhorn-frontend
|
||||||
servicePort: 80
|
servicePort: 80
|
||||||
{{- end }}
|
|
||||||
{{- if .Values.ingress.tls }}
|
{{- if .Values.ingress.tls }}
|
||||||
tls:
|
tls:
|
||||||
- hosts:
|
- hosts:
|
||||||
|
|||||||
@ -1,27 +0,0 @@
|
|||||||
{{- if .Values.networkPolicies.enabled }}
|
|
||||||
apiVersion: networking.k8s.io/v1
|
|
||||||
kind: NetworkPolicy
|
|
||||||
metadata:
|
|
||||||
name: backing-image-data-source
|
|
||||||
namespace: longhorn-system
|
|
||||||
spec:
|
|
||||||
podSelector:
|
|
||||||
matchLabels:
|
|
||||||
longhorn.io/component: backing-image-data-source
|
|
||||||
policyTypes:
|
|
||||||
- Ingress
|
|
||||||
ingress:
|
|
||||||
- from:
|
|
||||||
- podSelector:
|
|
||||||
matchLabels:
|
|
||||||
app: longhorn-manager
|
|
||||||
- podSelector:
|
|
||||||
matchLabels:
|
|
||||||
longhorn.io/component: instance-manager
|
|
||||||
- podSelector:
|
|
||||||
matchLabels:
|
|
||||||
longhorn.io/component: backing-image-manager
|
|
||||||
- podSelector:
|
|
||||||
matchLabels:
|
|
||||||
longhorn.io/component: backing-image-data-source
|
|
||||||
{{- end }}
|
|
||||||
@ -1,27 +0,0 @@
|
|||||||
{{- if .Values.networkPolicies.enabled }}
|
|
||||||
apiVersion: networking.k8s.io/v1
|
|
||||||
kind: NetworkPolicy
|
|
||||||
metadata:
|
|
||||||
name: backing-image-manager
|
|
||||||
namespace: longhorn-system
|
|
||||||
spec:
|
|
||||||
podSelector:
|
|
||||||
matchLabels:
|
|
||||||
longhorn.io/component: backing-image-manager
|
|
||||||
policyTypes:
|
|
||||||
- Ingress
|
|
||||||
ingress:
|
|
||||||
- from:
|
|
||||||
- podSelector:
|
|
||||||
matchLabels:
|
|
||||||
app: longhorn-manager
|
|
||||||
- podSelector:
|
|
||||||
matchLabels:
|
|
||||||
longhorn.io/component: instance-manager
|
|
||||||
- podSelector:
|
|
||||||
matchLabels:
|
|
||||||
longhorn.io/component: backing-image-manager
|
|
||||||
- podSelector:
|
|
||||||
matchLabels:
|
|
||||||
longhorn.io/component: backing-image-data-source
|
|
||||||
{{- end }}
|
|
||||||
@ -1,27 +0,0 @@
|
|||||||
{{- if .Values.networkPolicies.enabled }}
|
|
||||||
apiVersion: networking.k8s.io/v1
|
|
||||||
kind: NetworkPolicy
|
|
||||||
metadata:
|
|
||||||
name: instance-manager
|
|
||||||
namespace: longhorn-system
|
|
||||||
spec:
|
|
||||||
podSelector:
|
|
||||||
matchLabels:
|
|
||||||
longhorn.io/component: instance-manager
|
|
||||||
policyTypes:
|
|
||||||
- Ingress
|
|
||||||
ingress:
|
|
||||||
- from:
|
|
||||||
- podSelector:
|
|
||||||
matchLabels:
|
|
||||||
app: longhorn-manager
|
|
||||||
- podSelector:
|
|
||||||
matchLabels:
|
|
||||||
longhorn.io/component: instance-manager
|
|
||||||
- podSelector:
|
|
||||||
matchLabels:
|
|
||||||
longhorn.io/component: backing-image-manager
|
|
||||||
- podSelector:
|
|
||||||
matchLabels:
|
|
||||||
longhorn.io/component: backing-image-data-source
|
|
||||||
{{- end }}
|
|
||||||
@ -1,35 +0,0 @@
|
|||||||
{{- if .Values.networkPolicies.enabled }}
|
|
||||||
apiVersion: networking.k8s.io/v1
|
|
||||||
kind: NetworkPolicy
|
|
||||||
metadata:
|
|
||||||
name: longhorn-manager
|
|
||||||
namespace: longhorn-system
|
|
||||||
spec:
|
|
||||||
podSelector:
|
|
||||||
matchLabels:
|
|
||||||
app: longhorn-manager
|
|
||||||
policyTypes:
|
|
||||||
- Ingress
|
|
||||||
ingress:
|
|
||||||
- from:
|
|
||||||
- podSelector:
|
|
||||||
matchLabels:
|
|
||||||
app: longhorn-manager
|
|
||||||
- podSelector:
|
|
||||||
matchLabels:
|
|
||||||
app: longhorn-ui
|
|
||||||
- podSelector:
|
|
||||||
matchLabels:
|
|
||||||
app: longhorn-csi-plugin
|
|
||||||
- podSelector:
|
|
||||||
matchLabels:
|
|
||||||
longhorn.io/managed-by: longhorn-manager
|
|
||||||
matchExpressions:
|
|
||||||
- { key: recurring-job.longhorn.io, operator: Exists }
|
|
||||||
- podSelector:
|
|
||||||
matchExpressions:
|
|
||||||
- { key: longhorn.io/job-task, operator: Exists }
|
|
||||||
- podSelector:
|
|
||||||
matchLabels:
|
|
||||||
app: longhorn-driver-deployer
|
|
||||||
{{- end }}
|
|
||||||
@ -1,17 +0,0 @@
|
|||||||
{{- if .Values.networkPolicies.enabled }}
|
|
||||||
apiVersion: networking.k8s.io/v1
|
|
||||||
kind: NetworkPolicy
|
|
||||||
metadata:
|
|
||||||
name: longhorn-recovery-backend
|
|
||||||
namespace: longhorn-system
|
|
||||||
spec:
|
|
||||||
podSelector:
|
|
||||||
matchLabels:
|
|
||||||
app: longhorn-manager
|
|
||||||
policyTypes:
|
|
||||||
- Ingress
|
|
||||||
ingress:
|
|
||||||
- ports:
|
|
||||||
- protocol: TCP
|
|
||||||
port: 9503
|
|
||||||
{{- end }}
|
|
||||||
@ -1,46 +0,0 @@
|
|||||||
{{- if and .Values.networkPolicies.enabled .Values.ingress.enabled (not (eq .Values.networkPolicies.type "")) }}
|
|
||||||
apiVersion: networking.k8s.io/v1
|
|
||||||
kind: NetworkPolicy
|
|
||||||
metadata:
|
|
||||||
name: longhorn-ui-frontend
|
|
||||||
namespace: longhorn-system
|
|
||||||
spec:
|
|
||||||
podSelector:
|
|
||||||
matchLabels:
|
|
||||||
app: longhorn-ui
|
|
||||||
policyTypes:
|
|
||||||
- Ingress
|
|
||||||
ingress:
|
|
||||||
- from:
|
|
||||||
{{- if eq .Values.networkPolicies.type "rke1"}}
|
|
||||||
- namespaceSelector:
|
|
||||||
matchLabels:
|
|
||||||
kubernetes.io/metadata.name: ingress-nginx
|
|
||||||
podSelector:
|
|
||||||
matchLabels:
|
|
||||||
app.kubernetes.io/component: controller
|
|
||||||
app.kubernetes.io/instance: ingress-nginx
|
|
||||||
app.kubernetes.io/name: ingress-nginx
|
|
||||||
{{- else if eq .Values.networkPolicies.type "rke2" }}
|
|
||||||
- namespaceSelector:
|
|
||||||
matchLabels:
|
|
||||||
kubernetes.io/metadata.name: kube-system
|
|
||||||
podSelector:
|
|
||||||
matchLabels:
|
|
||||||
app.kubernetes.io/component: controller
|
|
||||||
app.kubernetes.io/instance: rke2-ingress-nginx
|
|
||||||
app.kubernetes.io/name: rke2-ingress-nginx
|
|
||||||
{{- else if eq .Values.networkPolicies.type "k3s" }}
|
|
||||||
- namespaceSelector:
|
|
||||||
matchLabels:
|
|
||||||
kubernetes.io/metadata.name: kube-system
|
|
||||||
podSelector:
|
|
||||||
matchLabels:
|
|
||||||
app.kubernetes.io/name: traefik
|
|
||||||
ports:
|
|
||||||
- port: 8000
|
|
||||||
protocol: TCP
|
|
||||||
- port: 80
|
|
||||||
protocol: TCP
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
@ -1,33 +0,0 @@
|
|||||||
{{- if .Values.networkPolicies.enabled }}
|
|
||||||
apiVersion: networking.k8s.io/v1
|
|
||||||
kind: NetworkPolicy
|
|
||||||
metadata:
|
|
||||||
name: longhorn-conversion-webhook
|
|
||||||
namespace: longhorn-system
|
|
||||||
spec:
|
|
||||||
podSelector:
|
|
||||||
matchLabels:
|
|
||||||
app: longhorn-manager
|
|
||||||
policyTypes:
|
|
||||||
- Ingress
|
|
||||||
ingress:
|
|
||||||
- ports:
|
|
||||||
- protocol: TCP
|
|
||||||
port: 9501
|
|
||||||
---
|
|
||||||
apiVersion: networking.k8s.io/v1
|
|
||||||
kind: NetworkPolicy
|
|
||||||
metadata:
|
|
||||||
name: longhorn-admission-webhook
|
|
||||||
namespace: longhorn-system
|
|
||||||
spec:
|
|
||||||
podSelector:
|
|
||||||
matchLabels:
|
|
||||||
app: longhorn-manager
|
|
||||||
policyTypes:
|
|
||||||
- Ingress
|
|
||||||
ingress:
|
|
||||||
- ports:
|
|
||||||
- protocol: TCP
|
|
||||||
port: 9502
|
|
||||||
{{- end }}
|
|
||||||
@ -18,7 +18,7 @@ spec:
|
|||||||
containers:
|
containers:
|
||||||
- name: longhorn-post-upgrade
|
- name: longhorn-post-upgrade
|
||||||
image: {{ template "registry_url" . }}{{ .Values.image.longhorn.manager.repository }}:{{ .Values.image.longhorn.manager.tag }}
|
image: {{ template "registry_url" . }}{{ .Values.image.longhorn.manager.repository }}:{{ .Values.image.longhorn.manager.tag }}
|
||||||
imagePullPolicy: {{ .Values.image.pullPolicy }}
|
imagePullPolicy: IfNotPresent
|
||||||
command:
|
command:
|
||||||
- longhorn-manager
|
- longhorn-manager
|
||||||
- post-upgrade
|
- post-upgrade
|
||||||
@ -32,25 +32,4 @@ spec:
|
|||||||
imagePullSecrets:
|
imagePullSecrets:
|
||||||
- name: {{ .Values.privateRegistry.registrySecret }}
|
- name: {{ .Values.privateRegistry.registrySecret }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
{{- if .Values.longhornManager.priorityClass }}
|
|
||||||
priorityClassName: {{ .Values.longhornManager.priorityClass | quote }}
|
|
||||||
{{- end }}
|
|
||||||
serviceAccountName: longhorn-service-account
|
serviceAccountName: longhorn-service-account
|
||||||
{{- if or .Values.longhornManager.tolerations .Values.global.cattle.windowsCluster.enabled }}
|
|
||||||
tolerations:
|
|
||||||
{{- if and .Values.global.cattle.windowsCluster.enabled .Values.global.cattle.windowsCluster.tolerations }}
|
|
||||||
{{ toYaml .Values.global.cattle.windowsCluster.tolerations | indent 6 }}
|
|
||||||
{{- end }}
|
|
||||||
{{- if .Values.longhornManager.tolerations }}
|
|
||||||
{{ toYaml .Values.longhornManager.tolerations | indent 6 }}
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
{{- if or .Values.longhornManager.nodeSelector .Values.global.cattle.windowsCluster.enabled }}
|
|
||||||
nodeSelector:
|
|
||||||
{{- if and .Values.global.cattle.windowsCluster.enabled .Values.global.cattle.windowsCluster.nodeSelector }}
|
|
||||||
{{ toYaml .Values.global.cattle.windowsCluster.nodeSelector | indent 8 }}
|
|
||||||
{{- end }}
|
|
||||||
{{- if .Values.longhornManager.nodeSelector }}
|
|
||||||
{{ toYaml .Values.longhornManager.nodeSelector | indent 8 }}
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
|
|||||||
@ -1,58 +0,0 @@
|
|||||||
{{- if .Values.helmPreUpgradeCheckerJob.enabled }}
|
|
||||||
apiVersion: batch/v1
|
|
||||||
kind: Job
|
|
||||||
metadata:
|
|
||||||
annotations:
|
|
||||||
"helm.sh/hook": pre-upgrade
|
|
||||||
"helm.sh/hook-delete-policy": hook-succeeded,before-hook-creation,hook-failed
|
|
||||||
name: longhorn-pre-upgrade
|
|
||||||
namespace: {{ include "release_namespace" . }}
|
|
||||||
labels: {{- include "longhorn.labels" . | nindent 4 }}
|
|
||||||
spec:
|
|
||||||
activeDeadlineSeconds: 900
|
|
||||||
backoffLimit: 1
|
|
||||||
template:
|
|
||||||
metadata:
|
|
||||||
name: longhorn-pre-upgrade
|
|
||||||
labels: {{- include "longhorn.labels" . | nindent 8 }}
|
|
||||||
spec:
|
|
||||||
containers:
|
|
||||||
- name: longhorn-pre-upgrade
|
|
||||||
image: {{ template "registry_url" . }}{{ .Values.image.longhorn.manager.repository }}:{{ .Values.image.longhorn.manager.tag }}
|
|
||||||
imagePullPolicy: {{ .Values.image.pullPolicy }}
|
|
||||||
command:
|
|
||||||
- longhorn-manager
|
|
||||||
- pre-upgrade
|
|
||||||
env:
|
|
||||||
- name: POD_NAMESPACE
|
|
||||||
valueFrom:
|
|
||||||
fieldRef:
|
|
||||||
fieldPath: metadata.namespace
|
|
||||||
restartPolicy: OnFailure
|
|
||||||
{{- if .Values.privateRegistry.registrySecret }}
|
|
||||||
imagePullSecrets:
|
|
||||||
- name: {{ .Values.privateRegistry.registrySecret }}
|
|
||||||
{{- end }}
|
|
||||||
{{- if .Values.longhornManager.priorityClass }}
|
|
||||||
priorityClassName: {{ .Values.longhornManager.priorityClass | quote }}
|
|
||||||
{{- end }}
|
|
||||||
serviceAccountName: longhorn-service-account
|
|
||||||
{{- if or .Values.longhornManager.tolerations .Values.global.cattle.windowsCluster.enabled }}
|
|
||||||
tolerations:
|
|
||||||
{{- if and .Values.global.cattle.windowsCluster.enabled .Values.global.cattle.windowsCluster.tolerations }}
|
|
||||||
{{ toYaml .Values.global.cattle.windowsCluster.tolerations | indent 6 }}
|
|
||||||
{{- end }}
|
|
||||||
{{- if .Values.longhornManager.tolerations }}
|
|
||||||
{{ toYaml .Values.longhornManager.tolerations | indent 6 }}
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
{{- if or .Values.longhornManager.nodeSelector .Values.global.cattle.windowsCluster.enabled }}
|
|
||||||
nodeSelector:
|
|
||||||
{{- if and .Values.global.cattle.windowsCluster.enabled .Values.global.cattle.windowsCluster.nodeSelector }}
|
|
||||||
{{ toYaml .Values.global.cattle.windowsCluster.nodeSelector | indent 8 }}
|
|
||||||
{{- end }}
|
|
||||||
{{- if .Values.longhornManager.nodeSelector }}
|
|
||||||
{{ toYaml .Values.longhornManager.nodeSelector | indent 8 }}
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
@ -1,4 +1,3 @@
|
|||||||
{{- if .Values.privateRegistry.createSecret }}
|
|
||||||
{{- if .Values.privateRegistry.registrySecret }}
|
{{- if .Values.privateRegistry.registrySecret }}
|
||||||
apiVersion: v1
|
apiVersion: v1
|
||||||
kind: Secret
|
kind: Secret
|
||||||
@ -10,4 +9,3 @@ type: kubernetes.io/dockerconfigjson
|
|||||||
data:
|
data:
|
||||||
.dockerconfigjson: {{ template "secret" . }}
|
.dockerconfigjson: {{ template "secret" . }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
{{- end }}
|
|
||||||
@ -4,37 +4,3 @@ metadata:
|
|||||||
name: longhorn-service-account
|
name: longhorn-service-account
|
||||||
namespace: {{ include "release_namespace" . }}
|
namespace: {{ include "release_namespace" . }}
|
||||||
labels: {{- include "longhorn.labels" . | nindent 4 }}
|
labels: {{- include "longhorn.labels" . | nindent 4 }}
|
||||||
{{- with .Values.serviceAccount.annotations }}
|
|
||||||
annotations:
|
|
||||||
{{- toYaml . | nindent 4 }}
|
|
||||||
{{- end }}
|
|
||||||
---
|
|
||||||
apiVersion: v1
|
|
||||||
kind: ServiceAccount
|
|
||||||
metadata:
|
|
||||||
name: longhorn-ui-service-account
|
|
||||||
namespace: {{ include "release_namespace" . }}
|
|
||||||
labels: {{- include "longhorn.labels" . | nindent 4 }}
|
|
||||||
{{- with .Values.serviceAccount.annotations }}
|
|
||||||
annotations:
|
|
||||||
{{- toYaml . | nindent 4 }}
|
|
||||||
{{- end }}
|
|
||||||
{{- if .Values.openshift.enabled }}
|
|
||||||
{{- if .Values.openshift.ui.route }}
|
|
||||||
{{- if not .Values.serviceAccount.annotations }}
|
|
||||||
annotations:
|
|
||||||
{{- end }}
|
|
||||||
serviceaccounts.openshift.io/oauth-redirectreference.primary: '{"kind":"OAuthRedirectReference","apiVersion":"v1","reference":{"kind":"Route","name":"longhorn-ui"}}'
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
---
|
|
||||||
apiVersion: v1
|
|
||||||
kind: ServiceAccount
|
|
||||||
metadata:
|
|
||||||
name: longhorn-support-bundle
|
|
||||||
namespace: {{ include "release_namespace" . }}
|
|
||||||
labels: {{- include "longhorn.labels" . | nindent 4 }}
|
|
||||||
{{- with .Values.serviceAccount.annotations }}
|
|
||||||
annotations:
|
|
||||||
{{- toYaml . | nindent 4 }}
|
|
||||||
{{- end }}
|
|
||||||
@ -1,74 +0,0 @@
|
|||||||
apiVersion: v1
|
|
||||||
kind: Service
|
|
||||||
metadata:
|
|
||||||
labels: {{- include "longhorn.labels" . | nindent 4 }}
|
|
||||||
app: longhorn-conversion-webhook
|
|
||||||
name: longhorn-conversion-webhook
|
|
||||||
namespace: {{ include "release_namespace" . }}
|
|
||||||
spec:
|
|
||||||
type: ClusterIP
|
|
||||||
sessionAffinity: ClientIP
|
|
||||||
selector:
|
|
||||||
app: longhorn-manager
|
|
||||||
ports:
|
|
||||||
- name: conversion-webhook
|
|
||||||
port: 9501
|
|
||||||
targetPort: conversion-wh
|
|
||||||
---
|
|
||||||
apiVersion: v1
|
|
||||||
kind: Service
|
|
||||||
metadata:
|
|
||||||
labels: {{- include "longhorn.labels" . | nindent 4 }}
|
|
||||||
app: longhorn-admission-webhook
|
|
||||||
name: longhorn-admission-webhook
|
|
||||||
namespace: {{ include "release_namespace" . }}
|
|
||||||
spec:
|
|
||||||
type: ClusterIP
|
|
||||||
sessionAffinity: ClientIP
|
|
||||||
selector:
|
|
||||||
app: longhorn-manager
|
|
||||||
ports:
|
|
||||||
- name: admission-webhook
|
|
||||||
port: 9502
|
|
||||||
targetPort: admission-wh
|
|
||||||
---
|
|
||||||
apiVersion: v1
|
|
||||||
kind: Service
|
|
||||||
metadata:
|
|
||||||
labels: {{- include "longhorn.labels" . | nindent 4 }}
|
|
||||||
app: longhorn-recovery-backend
|
|
||||||
name: longhorn-recovery-backend
|
|
||||||
namespace: {{ include "release_namespace" . }}
|
|
||||||
spec:
|
|
||||||
type: ClusterIP
|
|
||||||
sessionAffinity: ClientIP
|
|
||||||
selector:
|
|
||||||
app: longhorn-manager
|
|
||||||
ports:
|
|
||||||
- name: recovery-backend
|
|
||||||
port: 9503
|
|
||||||
targetPort: recov-backend
|
|
||||||
---
|
|
||||||
apiVersion: v1
|
|
||||||
kind: Service
|
|
||||||
metadata:
|
|
||||||
labels: {{- include "longhorn.labels" . | nindent 4 }}
|
|
||||||
name: longhorn-engine-manager
|
|
||||||
namespace: {{ include "release_namespace" . }}
|
|
||||||
spec:
|
|
||||||
clusterIP: None
|
|
||||||
selector:
|
|
||||||
longhorn.io/component: instance-manager
|
|
||||||
longhorn.io/instance-manager-type: engine
|
|
||||||
---
|
|
||||||
apiVersion: v1
|
|
||||||
kind: Service
|
|
||||||
metadata:
|
|
||||||
labels: {{- include "longhorn.labels" . | nindent 4 }}
|
|
||||||
name: longhorn-replica-manager
|
|
||||||
namespace: {{ include "release_namespace" . }}
|
|
||||||
spec:
|
|
||||||
clusterIP: None
|
|
||||||
selector:
|
|
||||||
longhorn.io/component: instance-manager
|
|
||||||
longhorn.io/instance-manager-type: replica
|
|
||||||
@ -20,25 +20,7 @@ data:
|
|||||||
numberOfReplicas: "{{ .Values.persistence.defaultClassReplicaCount }}"
|
numberOfReplicas: "{{ .Values.persistence.defaultClassReplicaCount }}"
|
||||||
staleReplicaTimeout: "30"
|
staleReplicaTimeout: "30"
|
||||||
fromBackup: ""
|
fromBackup: ""
|
||||||
{{- if .Values.persistence.defaultFsType }}
|
baseImage: ""
|
||||||
fsType: "{{ .Values.persistence.defaultFsType }}"
|
{{- if .Values.persistence.recurringJobs.enable }}
|
||||||
{{- end }}
|
recurringJobs: '{{ .Values.persistence.recurringJobs.jobList }}'
|
||||||
{{- if .Values.persistence.defaultMkfsParams }}
|
|
||||||
mkfsParams: "{{ .Values.persistence.defaultMkfsParams }}"
|
|
||||||
{{- end }}
|
|
||||||
{{- if .Values.persistence.migratable }}
|
|
||||||
migratable: "{{ .Values.persistence.migratable }}"
|
|
||||||
{{- end }}
|
|
||||||
{{- if .Values.persistence.backingImage.enable }}
|
|
||||||
backingImage: {{ .Values.persistence.backingImage.name }}
|
|
||||||
backingImageDataSourceType: {{ .Values.persistence.backingImage.dataSourceType }}
|
|
||||||
backingImageDataSourceParameters: {{ .Values.persistence.backingImage.dataSourceParameters }}
|
|
||||||
backingImageChecksum: {{ .Values.persistence.backingImage.expectedChecksum }}
|
|
||||||
{{- end }}
|
|
||||||
{{- if .Values.persistence.recurringJobSelector.enable }}
|
|
||||||
recurringJobSelector: '{{ .Values.persistence.recurringJobSelector.jobList }}'
|
|
||||||
{{- end }}
|
|
||||||
dataLocality: {{ .Values.persistence.defaultDataLocality | quote }}
|
|
||||||
{{- if .Values.persistence.defaultNodeSelector.enable }}
|
|
||||||
nodeSelector: "{{ .Values.persistence.defaultNodeSelector.selector }}"
|
|
||||||
{{- end }}
|
{{- end }}
|
||||||
|
|||||||
@ -3,9 +3,9 @@
|
|||||||
apiVersion: v1
|
apiVersion: v1
|
||||||
kind: Secret
|
kind: Secret
|
||||||
metadata:
|
metadata:
|
||||||
name: {{ .name }}
|
name: longhorn
|
||||||
namespace: {{ include "release_namespace" $ }}
|
namespace: {{ include "release_namespace" . }}
|
||||||
labels: {{- include "longhorn.labels" $ | nindent 4 }}
|
labels: {{- include "longhorn.labels" . | nindent 4 }}
|
||||||
app: longhorn
|
app: longhorn
|
||||||
type: kubernetes.io/tls
|
type: kubernetes.io/tls
|
||||||
data:
|
data:
|
||||||
|
|||||||
@ -3,7 +3,7 @@ kind: Job
|
|||||||
metadata:
|
metadata:
|
||||||
annotations:
|
annotations:
|
||||||
"helm.sh/hook": pre-delete
|
"helm.sh/hook": pre-delete
|
||||||
"helm.sh/hook-delete-policy": before-hook-creation,hook-succeeded
|
"helm.sh/hook-delete-policy": hook-succeeded
|
||||||
name: longhorn-uninstall
|
name: longhorn-uninstall
|
||||||
namespace: {{ include "release_namespace" . }}
|
namespace: {{ include "release_namespace" . }}
|
||||||
labels: {{- include "longhorn.labels" . | nindent 4 }}
|
labels: {{- include "longhorn.labels" . | nindent 4 }}
|
||||||
@ -18,7 +18,7 @@ spec:
|
|||||||
containers:
|
containers:
|
||||||
- name: longhorn-uninstall
|
- name: longhorn-uninstall
|
||||||
image: {{ template "registry_url" . }}{{ .Values.image.longhorn.manager.repository }}:{{ .Values.image.longhorn.manager.tag }}
|
image: {{ template "registry_url" . }}{{ .Values.image.longhorn.manager.repository }}:{{ .Values.image.longhorn.manager.tag }}
|
||||||
imagePullPolicy: {{ .Values.image.pullPolicy }}
|
imagePullPolicy: IfNotPresent
|
||||||
command:
|
command:
|
||||||
- longhorn-manager
|
- longhorn-manager
|
||||||
- uninstall
|
- uninstall
|
||||||
@ -28,30 +28,9 @@ spec:
|
|||||||
valueFrom:
|
valueFrom:
|
||||||
fieldRef:
|
fieldRef:
|
||||||
fieldPath: metadata.namespace
|
fieldPath: metadata.namespace
|
||||||
restartPolicy: Never
|
restartPolicy: OnFailure
|
||||||
{{- if .Values.privateRegistry.registrySecret }}
|
{{- if .Values.privateRegistry.registrySecret }}
|
||||||
imagePullSecrets:
|
imagePullSecrets:
|
||||||
- name: {{ .Values.privateRegistry.registrySecret }}
|
- name: {{ .Values.privateRegistry.registrySecret }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
{{- if .Values.longhornManager.priorityClass }}
|
|
||||||
priorityClassName: {{ .Values.longhornManager.priorityClass | quote }}
|
|
||||||
{{- end }}
|
|
||||||
serviceAccountName: longhorn-service-account
|
serviceAccountName: longhorn-service-account
|
||||||
{{- if or .Values.longhornManager.tolerations .Values.global.cattle.windowsCluster.enabled }}
|
|
||||||
tolerations:
|
|
||||||
{{- if and .Values.global.cattle.windowsCluster.enabled .Values.global.cattle.windowsCluster.tolerations }}
|
|
||||||
{{ toYaml .Values.global.cattle.windowsCluster.tolerations | indent 6 }}
|
|
||||||
{{- end }}
|
|
||||||
{{- if .Values.longhornManager.tolerations }}
|
|
||||||
{{ toYaml .Values.longhornManager.tolerations | indent 6 }}
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
{{- if or .Values.longhornManager.nodeSelector .Values.global.cattle.windowsCluster.enabled }}
|
|
||||||
nodeSelector:
|
|
||||||
{{- if and .Values.global.cattle.windowsCluster.enabled .Values.global.cattle.windowsCluster.nodeSelector }}
|
|
||||||
{{ toYaml .Values.global.cattle.windowsCluster.nodeSelector | indent 8 }}
|
|
||||||
{{- end }}
|
|
||||||
{{- if or .Values.longhornManager.nodeSelector }}
|
|
||||||
{{ toYaml .Values.longhornManager.nodeSelector | indent 8 }}
|
|
||||||
{{- end }}
|
|
||||||
{{- end }}
|
|
||||||
|
|||||||
@ -1,7 +0,0 @@
|
|||||||
#{{- if gt (len (lookup "rbac.authorization.k8s.io/v1" "ClusterRole" "" "")) 0 -}}
|
|
||||||
#{{- if .Values.enablePSP }}
|
|
||||||
#{{- if not (.Capabilities.APIVersions.Has "policy/v1beta1/PodSecurityPolicy") }}
|
|
||||||
#{{- fail "The target cluster does not have the PodSecurityPolicy API resource. Please disable PSPs in this chart before proceeding." -}}
|
|
||||||
#{{- end }}
|
|
||||||
#{{- end }}
|
|
||||||
#{{- end }}
|
|
||||||
@ -3,432 +3,132 @@
|
|||||||
# Declare variables to be passed into your templates.
|
# Declare variables to be passed into your templates.
|
||||||
global:
|
global:
|
||||||
cattle:
|
cattle:
|
||||||
# -- System default registry
|
|
||||||
systemDefaultRegistry: ""
|
systemDefaultRegistry: ""
|
||||||
windowsCluster:
|
|
||||||
# -- Enable this to allow Longhorn to run on the Rancher deployed Windows cluster
|
|
||||||
enabled: false
|
|
||||||
# -- Tolerate Linux nodes to run Longhorn user deployed components
|
|
||||||
tolerations:
|
|
||||||
- key: "cattle.io/os"
|
|
||||||
value: "linux"
|
|
||||||
effect: "NoSchedule"
|
|
||||||
operator: "Equal"
|
|
||||||
# -- Select Linux nodes to run Longhorn user deployed components
|
|
||||||
nodeSelector:
|
|
||||||
kubernetes.io/os: "linux"
|
|
||||||
defaultSetting:
|
|
||||||
# -- Toleration for Longhorn system managed components
|
|
||||||
taintToleration: cattle.io/os=linux:NoSchedule
|
|
||||||
# -- Node selector for Longhorn system managed components
|
|
||||||
systemManagedComponentsNodeSelector: kubernetes.io/os:linux
|
|
||||||
|
|
||||||
networkPolicies:
|
|
||||||
# -- Enable NetworkPolicies to limit access to the Longhorn pods
|
|
||||||
enabled: false
|
|
||||||
# -- Create the policy based on your distribution to allow access for the ingress. Options: `k3s`, `rke2`, `rke1`
|
|
||||||
type: "k3s"
|
|
||||||
|
|
||||||
image:
|
image:
|
||||||
longhorn:
|
longhorn:
|
||||||
engine:
|
engine:
|
||||||
# -- Specify Longhorn engine image repository
|
|
||||||
repository: longhornio/longhorn-engine
|
repository: longhornio/longhorn-engine
|
||||||
# -- Specify Longhorn engine image tag
|
tag: v1.1.0
|
||||||
tag: master-head
|
|
||||||
manager:
|
manager:
|
||||||
# -- Specify Longhorn manager image repository
|
|
||||||
repository: longhornio/longhorn-manager
|
repository: longhornio/longhorn-manager
|
||||||
# -- Specify Longhorn manager image tag
|
tag: v1.1.0
|
||||||
tag: master-head
|
|
||||||
ui:
|
ui:
|
||||||
# -- Specify Longhorn ui image repository
|
|
||||||
repository: longhornio/longhorn-ui
|
repository: longhornio/longhorn-ui
|
||||||
# -- Specify Longhorn ui image tag
|
tag: v1.1.0
|
||||||
tag: master-head
|
|
||||||
instanceManager:
|
instanceManager:
|
||||||
# -- Specify Longhorn instance manager image repository
|
|
||||||
repository: longhornio/longhorn-instance-manager
|
repository: longhornio/longhorn-instance-manager
|
||||||
# -- Specify Longhorn instance manager image tag
|
tag: v1_20201216
|
||||||
tag: master-head
|
|
||||||
shareManager:
|
shareManager:
|
||||||
# -- Specify Longhorn share manager image repository
|
|
||||||
repository: longhornio/longhorn-share-manager
|
repository: longhornio/longhorn-share-manager
|
||||||
# -- Specify Longhorn share manager image tag
|
tag: v1_20201204
|
||||||
tag: master-head
|
|
||||||
backingImageManager:
|
|
||||||
# -- Specify Longhorn backing image manager image repository
|
|
||||||
repository: longhornio/backing-image-manager
|
|
||||||
# -- Specify Longhorn backing image manager image tag
|
|
||||||
tag: master-head
|
|
||||||
supportBundleKit:
|
|
||||||
# -- Specify Longhorn support bundle manager image repository
|
|
||||||
repository: longhornio/support-bundle-kit
|
|
||||||
# -- Specify Longhorn support bundle manager image tag
|
|
||||||
tag: v0.0.27
|
|
||||||
csi:
|
csi:
|
||||||
attacher:
|
attacher:
|
||||||
# -- Specify CSI attacher image repository. Leave blank to autodetect
|
|
||||||
repository: longhornio/csi-attacher
|
repository: longhornio/csi-attacher
|
||||||
# -- Specify CSI attacher image tag. Leave blank to autodetect
|
tag: v2.2.1-lh1
|
||||||
tag: v4.2.0
|
|
||||||
provisioner:
|
provisioner:
|
||||||
# -- Specify CSI provisioner image repository. Leave blank to autodetect
|
|
||||||
repository: longhornio/csi-provisioner
|
repository: longhornio/csi-provisioner
|
||||||
# -- Specify CSI provisioner image tag. Leave blank to autodetect
|
tag: v1.6.0-lh1
|
||||||
tag: v3.4.1
|
|
||||||
nodeDriverRegistrar:
|
nodeDriverRegistrar:
|
||||||
# -- Specify CSI node driver registrar image repository. Leave blank to autodetect
|
|
||||||
repository: longhornio/csi-node-driver-registrar
|
repository: longhornio/csi-node-driver-registrar
|
||||||
# -- Specify CSI node driver registrar image tag. Leave blank to autodetect
|
tag: v1.2.0-lh1
|
||||||
tag: v2.7.0
|
|
||||||
resizer:
|
resizer:
|
||||||
# -- Specify CSI driver resizer image repository. Leave blank to autodetect
|
|
||||||
repository: longhornio/csi-resizer
|
repository: longhornio/csi-resizer
|
||||||
# -- Specify CSI driver resizer image tag. Leave blank to autodetect
|
tag: v0.5.1-lh1
|
||||||
tag: v1.7.0
|
|
||||||
snapshotter:
|
snapshotter:
|
||||||
# -- Specify CSI driver snapshotter image repository. Leave blank to autodetect
|
|
||||||
repository: longhornio/csi-snapshotter
|
repository: longhornio/csi-snapshotter
|
||||||
# -- Specify CSI driver snapshotter image tag. Leave blank to autodetect.
|
tag: v2.1.1-lh1
|
||||||
tag: v6.2.1
|
|
||||||
livenessProbe:
|
|
||||||
# -- Specify CSI liveness probe image repository. Leave blank to autodetect
|
|
||||||
repository: longhornio/livenessprobe
|
|
||||||
# -- Specify CSI liveness probe image tag. Leave blank to autodetect
|
|
||||||
tag: v2.9.0
|
|
||||||
openshift:
|
|
||||||
oauthProxy:
|
|
||||||
# -- For openshift user. Specify oauth proxy image repository
|
|
||||||
repository: quay.io/openshift/origin-oauth-proxy
|
|
||||||
# -- For openshift user. Specify oauth proxy image tag. Note: Use your OCP/OKD 4.X Version, Current Stable is 4.14
|
|
||||||
tag: 4.14
|
|
||||||
# -- Image pull policy which applies to all user deployed Longhorn Components. e.g, Longhorn manager, Longhorn driver, Longhorn UI
|
|
||||||
pullPolicy: IfNotPresent
|
pullPolicy: IfNotPresent
|
||||||
|
|
||||||
service:
|
service:
|
||||||
ui:
|
ui:
|
||||||
# -- Define Longhorn UI service type. Options: `ClusterIP`, `NodePort`, `LoadBalancer`, `Rancher-Proxy`
|
|
||||||
type: ClusterIP
|
type: ClusterIP
|
||||||
# -- NodePort port number (to set explicitly, choose port between 30000-32767)
|
|
||||||
nodePort: null
|
nodePort: null
|
||||||
manager:
|
manager:
|
||||||
# -- Define Longhorn manager service type.
|
|
||||||
type: ClusterIP
|
type: ClusterIP
|
||||||
# -- NodePort port number (to set explicitly, choose port between 30000-32767)
|
|
||||||
nodePort: ""
|
nodePort: ""
|
||||||
|
|
||||||
persistence:
|
persistence:
|
||||||
# -- Set Longhorn StorageClass as default
|
|
||||||
defaultClass: true
|
defaultClass: true
|
||||||
# -- Set filesystem type for Longhorn StorageClass
|
|
||||||
defaultFsType: ext4
|
|
||||||
# -- Set mkfs options for Longhorn StorageClass
|
|
||||||
defaultMkfsParams: ""
|
|
||||||
# -- Set replica count for Longhorn StorageClass
|
|
||||||
defaultClassReplicaCount: 3
|
defaultClassReplicaCount: 3
|
||||||
# -- Set data locality for Longhorn StorageClass. Options: `disabled`, `best-effort`
|
|
||||||
defaultDataLocality: disabled
|
|
||||||
# -- Define reclaim policy. Options: `Retain`, `Delete`
|
|
||||||
reclaimPolicy: Delete
|
reclaimPolicy: Delete
|
||||||
# -- Set volume migratable for Longhorn StorageClass
|
recurringJobs:
|
||||||
migratable: false
|
|
||||||
recurringJobSelector:
|
|
||||||
# -- Enable recurring job selector for Longhorn StorageClass
|
|
||||||
enable: false
|
enable: false
|
||||||
# -- Recurring job selector list for Longhorn StorageClass. Please be careful of quotes of input. e.g., `[{"name":"backup", "isGroup":true}]`
|
|
||||||
jobList: []
|
jobList: []
|
||||||
backingImage:
|
|
||||||
# -- Set backing image for Longhorn StorageClass
|
|
||||||
enable: false
|
|
||||||
# -- Specify a backing image that will be used by Longhorn volumes in Longhorn StorageClass. If not exists, the backing image data source type and backing image data source parameters should be specified so that Longhorn will create the backing image before using it
|
|
||||||
name: ~
|
|
||||||
# -- Specify the data source type for the backing image used in Longhorn StorageClass.
|
|
||||||
# If the backing image does not exists, Longhorn will use this field to create a backing image. Otherwise, Longhorn will use it to verify the selected backing image.
|
|
||||||
dataSourceType: ~
|
|
||||||
# -- Specify the data source parameters for the backing image used in Longhorn StorageClass. This option accepts a json string of a map. e.g., `'{\"url\":\"https://backing-image-example.s3-region.amazonaws.com/test-backing-image\"}'`.
|
|
||||||
dataSourceParameters: ~
|
|
||||||
# -- Specify the expected SHA512 checksum of the selected backing image in Longhorn StorageClass
|
|
||||||
expectedChecksum: ~
|
|
||||||
defaultNodeSelector:
|
|
||||||
# -- Enable Node selector for Longhorn StorageClass
|
|
||||||
enable: false
|
|
||||||
# -- This selector enables only certain nodes having these tags to be used for the volume. e.g. `"storage,fast"`
|
|
||||||
selector: ""
|
|
||||||
# -- Allow automatically removing snapshots during filesystem trim for Longhorn StorageClass. Options: `ignored`, `enabled`, `disabled`
|
|
||||||
removeSnapshotsDuringFilesystemTrim: ignored
|
|
||||||
|
|
||||||
helmPreUpgradeCheckerJob:
|
|
||||||
enabled: true
|
|
||||||
|
|
||||||
csi:
|
csi:
|
||||||
# -- Specify kubelet root-dir. Leave blank to autodetect
|
|
||||||
kubeletRootDir: ~
|
kubeletRootDir: ~
|
||||||
# -- Specify replica count of CSI Attacher. Leave blank to use default count: 3
|
|
||||||
attacherReplicaCount: ~
|
attacherReplicaCount: ~
|
||||||
# -- Specify replica count of CSI Provisioner. Leave blank to use default count: 3
|
|
||||||
provisionerReplicaCount: ~
|
provisionerReplicaCount: ~
|
||||||
# -- Specify replica count of CSI Resizer. Leave blank to use default count: 3
|
|
||||||
resizerReplicaCount: ~
|
resizerReplicaCount: ~
|
||||||
# -- Specify replica count of CSI Snapshotter. Leave blank to use default count: 3
|
|
||||||
snapshotterReplicaCount: ~
|
snapshotterReplicaCount: ~
|
||||||
|
|
||||||
defaultSettings:
|
defaultSettings:
|
||||||
# -- The endpoint used to access the backupstore. Available: NFS, CIFS, AWS, GCP, AZURE.
|
|
||||||
backupTarget: ~
|
backupTarget: ~
|
||||||
# -- The name of the Kubernetes secret associated with the backup target.
|
|
||||||
backupTargetCredentialSecret: ~
|
backupTargetCredentialSecret: ~
|
||||||
# -- If this setting is enabled, Longhorn will automatically attaches the volume and takes snapshot/backup
|
|
||||||
# when it is the time to do recurring snapshot/backup.
|
|
||||||
allowRecurringJobWhileVolumeDetached: ~
|
allowRecurringJobWhileVolumeDetached: ~
|
||||||
# -- Create default Disk automatically only on Nodes with the label "node.longhorn.io/create-default-disk=true" if no other disks exist.
|
|
||||||
# If disabled, the default disk will be created on all new nodes when each node is first added.
|
|
||||||
createDefaultDiskLabeledNodes: ~
|
createDefaultDiskLabeledNodes: ~
|
||||||
# -- Default path to use for storing data on a host. By default "/var/lib/longhorn/"
|
|
||||||
defaultDataPath: ~
|
defaultDataPath: ~
|
||||||
# -- Longhorn volume has data locality if there is a local replica of the volume on the same node as the pod which is using the volume.
|
|
||||||
defaultDataLocality: ~
|
defaultDataLocality: ~
|
||||||
# -- Allow scheduling on nodes with existing healthy replicas of the same volume. By default false.
|
|
||||||
replicaSoftAntiAffinity: ~
|
replicaSoftAntiAffinity: ~
|
||||||
# -- Enable this setting automatically rebalances replicas when discovered an available node.
|
|
||||||
replicaAutoBalance: ~
|
|
||||||
# -- The over-provisioning percentage defines how much storage can be allocated relative to the hard drive's capacity. By default 200.
|
|
||||||
storageOverProvisioningPercentage: ~
|
storageOverProvisioningPercentage: ~
|
||||||
# -- If the minimum available disk capacity exceeds the actual percentage of available disk capacity,
|
|
||||||
# the disk becomes unschedulable until more space is freed up. By default 25.
|
|
||||||
storageMinimalAvailablePercentage: ~
|
storageMinimalAvailablePercentage: ~
|
||||||
# -- The reserved percentage specifies the percentage of disk space that will not be allocated to the default disk on each new Longhorn node.
|
|
||||||
storageReservedPercentageForDefaultDisk: ~
|
|
||||||
# -- Upgrade Checker will check for new Longhorn version periodically.
|
|
||||||
# When there is a new version available, a notification will appear in the UI. By default true.
|
|
||||||
upgradeChecker: ~
|
upgradeChecker: ~
|
||||||
# -- The default number of replicas when a volume is created from the Longhorn UI.
|
|
||||||
# For Kubernetes configuration, update the `numberOfReplicas` in the StorageClass. By default 3.
|
|
||||||
defaultReplicaCount: ~
|
defaultReplicaCount: ~
|
||||||
# -- The 'storageClassName' is given to PVs and PVCs that are created for an existing Longhorn volume. The StorageClass name can also be used as a label,
|
guaranteedEngineCPU: ~
|
||||||
# so it is possible to use a Longhorn StorageClass to bind a workload to an existing PV without creating a Kubernetes StorageClass object.
|
|
||||||
# By default 'longhorn-static'.
|
|
||||||
defaultLonghornStaticStorageClass: ~
|
defaultLonghornStaticStorageClass: ~
|
||||||
# -- In seconds. The backupstore poll interval determines how often Longhorn checks the backupstore for new backups.
|
|
||||||
# Set to 0 to disable the polling. By default 300.
|
|
||||||
backupstorePollInterval: ~
|
backupstorePollInterval: ~
|
||||||
# -- In minutes. This setting determines how long Longhorn will keep the backup resource that was failed. Set to 0 to disable the auto-deletion.
|
|
||||||
failedBackupTTL: ~
|
|
||||||
# -- Restore recurring jobs from the backup volume on the backup target and create recurring jobs if not exist during a backup restoration.
|
|
||||||
restoreVolumeRecurringJobs: ~
|
|
||||||
# -- This setting specifies how many successful backup or snapshot job histories should be retained. History will not be retained if the value is 0.
|
|
||||||
recurringSuccessfulJobsHistoryLimit: ~
|
|
||||||
# -- This setting specifies how many failed backup or snapshot job histories should be retained. History will not be retained if the value is 0.
|
|
||||||
recurringFailedJobsHistoryLimit: ~
|
|
||||||
# -- This setting specifies how many failed support bundles can exist in the cluster.
|
|
||||||
# Set this value to **0** to have Longhorn automatically purge all failed support bundles.
|
|
||||||
supportBundleFailedHistoryLimit: ~
|
|
||||||
# -- taintToleration for longhorn system components
|
|
||||||
taintToleration: ~
|
taintToleration: ~
|
||||||
# -- nodeSelector for longhorn system components
|
|
||||||
systemManagedComponentsNodeSelector: ~
|
|
||||||
# -- priorityClass for longhorn system componentss
|
|
||||||
priorityClass: ~
|
priorityClass: ~
|
||||||
# -- If enabled, volumes will be automatically salvaged when all the replicas become faulty e.g. due to network disconnection.
|
|
||||||
# Longhorn will try to figure out which replica(s) are usable, then use them for the volume. By default true.
|
|
||||||
autoSalvage: ~
|
autoSalvage: ~
|
||||||
# -- If enabled, Longhorn will automatically delete the workload pod that is managed by a controller (e.g. deployment, statefulset, daemonset, etc...)
|
|
||||||
# when Longhorn volume is detached unexpectedly (e.g. during Kubernetes upgrade, Docker reboot, or network disconnect).
|
|
||||||
# By deleting the pod, its controller restarts the pod and Kubernetes handles volume reattachment and remount.
|
|
||||||
autoDeletePodWhenVolumeDetachedUnexpectedly: ~
|
autoDeletePodWhenVolumeDetachedUnexpectedly: ~
|
||||||
# -- Disable Longhorn manager to schedule replica on Kubernetes cordoned node. By default true.
|
|
||||||
disableSchedulingOnCordonedNode: ~
|
disableSchedulingOnCordonedNode: ~
|
||||||
# -- Allow scheduling new Replicas of Volume to the Nodes in the same Zone as existing healthy Replicas.
|
|
||||||
# Nodes don't belong to any Zone will be treated as in the same Zone.
|
|
||||||
# Notice that Longhorn relies on label `topology.kubernetes.io/zone=<Zone name of the node>` in the Kubernetes node object to identify the zone.
|
|
||||||
# By default true.
|
|
||||||
replicaZoneSoftAntiAffinity: ~
|
replicaZoneSoftAntiAffinity: ~
|
||||||
# -- Allow scheduling on disks with existing healthy replicas of the same volume. By default true.
|
volumeAttachmentRecoveryPolicy: ~
|
||||||
replicaDiskSoftAntiAffinity: ~
|
|
||||||
# -- Defines the Longhorn action when a Volume is stuck with a StatefulSet/Deployment Pod on a node that is down.
|
|
||||||
nodeDownPodDeletionPolicy: ~
|
nodeDownPodDeletionPolicy: ~
|
||||||
# -- Define the policy to use when a node with the last healthy replica of a volume is drained.
|
allowNodeDrainWithLastHealthyReplica: ~
|
||||||
nodeDrainPolicy: ~
|
mkfsExt4Parameters: ~
|
||||||
# -- In seconds. The interval determines how long Longhorn will wait at least in order to reuse the existing data on a failed replica
|
disableReplicaRebuild: ~
|
||||||
# rather than directly creating a new replica for a degraded volume.
|
|
||||||
replicaReplenishmentWaitInterval: ~
|
replicaReplenishmentWaitInterval: ~
|
||||||
# -- This setting controls how many replicas on a node can be rebuilt simultaneously.
|
|
||||||
concurrentReplicaRebuildPerNodeLimit: ~
|
|
||||||
# -- This setting controls how many volumes on a node can restore the backup concurrently. Set the value to **0** to disable backup restore.
|
|
||||||
concurrentVolumeBackupRestorePerNodeLimit: ~
|
|
||||||
# -- This setting is only for volumes created by UI.
|
|
||||||
# By default, this is false meaning there will be a reivision counter file to track every write to the volume.
|
|
||||||
# During salvage recovering Longhorn will pick the replica with largest reivision counter as candidate to recover the whole volume.
|
|
||||||
# If revision counter is disabled, Longhorn will not track every write to the volume.
|
|
||||||
# During the salvage recovering, Longhorn will use the 'volume-head-xxx.img' file last modification time and
|
|
||||||
# file size to pick the replica candidate to recover the whole volume.
|
|
||||||
disableRevisionCounter: ~
|
disableRevisionCounter: ~
|
||||||
# -- This setting defines the Image Pull Policy of Longhorn system managed pod.
|
|
||||||
# e.g. instance manager, engine image, CSI driver, etc.
|
|
||||||
# The new Image Pull Policy will only apply after the system managed pods restart.
|
|
||||||
systemManagedPodsImagePullPolicy: ~
|
systemManagedPodsImagePullPolicy: ~
|
||||||
# -- This setting allows user to create and attach a volume that doesn't have all the replicas scheduled at the time of creation.
|
|
||||||
allowVolumeCreationWithDegradedAvailability: ~
|
allowVolumeCreationWithDegradedAvailability: ~
|
||||||
# -- This setting enables Longhorn to automatically cleanup the system generated snapshot after replica rebuild is done.
|
|
||||||
autoCleanupSystemGeneratedSnapshot: ~
|
autoCleanupSystemGeneratedSnapshot: ~
|
||||||
# -- This setting controls how Longhorn automatically upgrades volumes' engines to the new default engine image after upgrading Longhorn manager.
|
|
||||||
# The value of this setting specifies the maximum number of engines per node that are allowed to upgrade to the default engine image at the same time.
|
|
||||||
# If the value is 0, Longhorn will not automatically upgrade volumes' engines to default version.
|
|
||||||
concurrentAutomaticEngineUpgradePerNodeLimit: ~
|
|
||||||
# -- This interval in minutes determines how long Longhorn will wait before cleaning up the backing image file when there is no replica in the disk using it.
|
|
||||||
backingImageCleanupWaitInterval: ~
|
|
||||||
# -- This interval in seconds determines how long Longhorn will wait before re-downloading the backing image file
|
|
||||||
# when all disk files of this backing image become failed or unknown.
|
|
||||||
backingImageRecoveryWaitInterval: ~
|
|
||||||
# -- This integer value indicates how many percentage of the total allocatable CPU on each node will be reserved for each instance manager Pod.
|
|
||||||
# You can leave it with the default value, which is 12%.
|
|
||||||
guaranteedInstanceManagerCPU: ~
|
|
||||||
# -- Enabling this setting will notify Longhorn that the cluster is using Kubernetes Cluster Autoscaler.
|
|
||||||
kubernetesClusterAutoscalerEnabled: ~
|
|
||||||
# -- This setting allows Longhorn to delete the orphan resource and its corresponding orphaned data automatically like stale replicas.
|
|
||||||
# Orphan resources on down or unknown nodes will not be cleaned up automatically.
|
|
||||||
orphanAutoDeletion: ~
|
|
||||||
# -- Longhorn uses the storage network for in-cluster data traffic. Leave this blank to use the Kubernetes cluster network.
|
|
||||||
storageNetwork: ~
|
|
||||||
# -- This flag is designed to prevent Longhorn from being accidentally uninstalled which will lead to data lost.
|
|
||||||
deletingConfirmationFlag: ~
|
|
||||||
# -- In seconds. The setting specifies the timeout between the engine and replica(s), and the value should be between 8 to 30 seconds.
|
|
||||||
# The default value is 8 seconds.
|
|
||||||
engineReplicaTimeout: ~
|
|
||||||
# -- This setting allows users to enable or disable snapshot hashing and data integrity checking.
|
|
||||||
snapshotDataIntegrity: ~
|
|
||||||
# -- Hashing snapshot disk files impacts the performance of the system.
|
|
||||||
# The immediate snapshot hashing and checking can be disabled to minimize the impact after creating a snapshot.
|
|
||||||
snapshotDataIntegrityImmediateCheckAfterSnapshotCreation: ~
|
|
||||||
# -- Unix-cron string format. The setting specifies when Longhorn checks the data integrity of snapshot disk files.
|
|
||||||
snapshotDataIntegrityCronjob: ~
|
|
||||||
# -- This setting allows Longhorn filesystem trim feature to automatically mark the latest snapshot and
|
|
||||||
# its ancestors as removed and stops at the snapshot containing multiple children.
|
|
||||||
removeSnapshotsDuringFilesystemTrim: ~
|
|
||||||
# -- This feature supports the fast replica rebuilding.
|
|
||||||
# It relies on the checksum of snapshot disk files, so setting the snapshot-data-integrity to **enable** or **fast-check** is a prerequisite.
|
|
||||||
fastReplicaRebuildEnabled: ~
|
|
||||||
# -- In seconds. The setting specifies the HTTP client timeout to the file sync server.
|
|
||||||
replicaFileSyncHttpClientTimeout: ~
|
|
||||||
# -- The log level Panic, Fatal, Error, Warn, Info, Debug, Trace used in longhorn manager. Default to Info.
|
|
||||||
logLevel: ~
|
|
||||||
# -- This setting allows users to specify backup compression method.
|
|
||||||
backupCompressionMethod: ~
|
|
||||||
# -- This setting controls how many worker threads per backup concurrently.
|
|
||||||
backupConcurrentLimit: ~
|
|
||||||
# -- This setting controls how many worker threads per restore concurrently.
|
|
||||||
restoreConcurrentLimit: ~
|
|
||||||
# -- This allows users to activate v2 data engine based on SPDK.
|
|
||||||
# Currently, it is in the preview phase and should not be utilized in a production environment.
|
|
||||||
v2DataEngine: ~
|
|
||||||
# -- This setting allows users to enable the offline replica rebuilding for volumes using v2 data engine.
|
|
||||||
offlineReplicaRebuilding: ~
|
|
||||||
# -- Allow Scheduling Empty Node Selector Volumes To Any Node
|
|
||||||
allowEmptyNodeSelectorVolume: ~
|
|
||||||
# -- Allow Scheduling Empty Disk Selector Volumes To Any Disk
|
|
||||||
allowEmptyDiskSelectorVolume: ~
|
|
||||||
|
|
||||||
privateRegistry:
|
privateRegistry:
|
||||||
# -- Set `true` to create a new private registry secret
|
|
||||||
createSecret: ~
|
|
||||||
# -- URL of private registry. Leave blank to apply system default registry
|
|
||||||
registryUrl: ~
|
registryUrl: ~
|
||||||
# -- User used to authenticate to private registry
|
|
||||||
registryUser: ~
|
registryUser: ~
|
||||||
# -- Password used to authenticate to private registry
|
|
||||||
registryPasswd: ~
|
registryPasswd: ~
|
||||||
# -- If create a new private registry secret is true, create a Kubernetes secret with this name; else use the existing secret of this name. Use it to pull images from your private registry
|
|
||||||
registrySecret: ~
|
registrySecret: ~
|
||||||
|
|
||||||
longhornManager:
|
resources: {}
|
||||||
log:
|
# We usually recommend not to specify default resources and to leave this as a conscious
|
||||||
# -- Options: `plain`, `json`
|
# choice for the user. This also increases chances charts run on environments with little
|
||||||
format: plain
|
# resources, such as Minikube. If you do want to specify resources, uncomment the following
|
||||||
# -- Priority class for longhorn manager
|
# lines, adjust them as necessary, and remove the curly braces after 'resources:'.
|
||||||
priorityClass: ~
|
# limits:
|
||||||
# -- Tolerate nodes to run Longhorn manager
|
# cpu: 100m
|
||||||
tolerations: []
|
# memory: 128Mi
|
||||||
## If you want to set tolerations for Longhorn Manager DaemonSet, delete the `[]` in the line above
|
# requests:
|
||||||
## and uncomment this example block
|
# cpu: 100m
|
||||||
# - key: "key"
|
# memory: 128Mi
|
||||||
# operator: "Equal"
|
#
|
||||||
# value: "value"
|
|
||||||
# effect: "NoSchedule"
|
|
||||||
# -- Select nodes to run Longhorn manager
|
|
||||||
nodeSelector: {}
|
|
||||||
## If you want to set node selector for Longhorn Manager DaemonSet, delete the `{}` in the line above
|
|
||||||
## and uncomment this example block
|
|
||||||
# label-key1: "label-value1"
|
|
||||||
# label-key2: "label-value2"
|
|
||||||
# -- Annotation used in Longhorn manager service
|
|
||||||
serviceAnnotations: {}
|
|
||||||
## If you want to set annotations for the Longhorn Manager service, delete the `{}` in the line above
|
|
||||||
## and uncomment this example block
|
|
||||||
# annotation-key1: "annotation-value1"
|
|
||||||
# annotation-key2: "annotation-value2"
|
|
||||||
|
|
||||||
longhornDriver:
|
|
||||||
# -- Priority class for longhorn driver
|
|
||||||
priorityClass: ~
|
|
||||||
# -- Tolerate nodes to run Longhorn driver
|
|
||||||
tolerations: []
|
|
||||||
## If you want to set tolerations for Longhorn Driver Deployer Deployment, delete the `[]` in the line above
|
|
||||||
## and uncomment this example block
|
|
||||||
# - key: "key"
|
|
||||||
# operator: "Equal"
|
|
||||||
# value: "value"
|
|
||||||
# effect: "NoSchedule"
|
|
||||||
# -- Select nodes to run Longhorn driver
|
|
||||||
nodeSelector: {}
|
|
||||||
## If you want to set node selector for Longhorn Driver Deployer Deployment, delete the `{}` in the line above
|
|
||||||
## and uncomment this example block
|
|
||||||
# label-key1: "label-value1"
|
|
||||||
# label-key2: "label-value2"
|
|
||||||
|
|
||||||
longhornUI:
|
|
||||||
# -- Replica count for longhorn ui
|
|
||||||
replicas: 2
|
|
||||||
# -- Priority class count for longhorn ui
|
|
||||||
priorityClass: ~
|
|
||||||
# -- Tolerate nodes to run Longhorn UI
|
|
||||||
tolerations: []
|
|
||||||
## If you want to set tolerations for Longhorn UI Deployment, delete the `[]` in the line above
|
|
||||||
## and uncomment this example block
|
|
||||||
# - key: "key"
|
|
||||||
# operator: "Equal"
|
|
||||||
# value: "value"
|
|
||||||
# effect: "NoSchedule"
|
|
||||||
# -- Select nodes to run Longhorn UI
|
|
||||||
nodeSelector: {}
|
|
||||||
## If you want to set node selector for Longhorn UI Deployment, delete the `{}` in the line above
|
|
||||||
## and uncomment this example block
|
|
||||||
# label-key1: "label-value1"
|
|
||||||
# label-key2: "label-value2"
|
|
||||||
|
|
||||||
ingress:
|
ingress:
|
||||||
# -- Set to true to enable ingress record generation
|
## Set to true to enable ingress record generation
|
||||||
enabled: false
|
enabled: false
|
||||||
|
|
||||||
# -- Add ingressClassName to the Ingress
|
|
||||||
# Can replace the kubernetes.io/ingress.class annotation on v1.18+
|
|
||||||
ingressClassName: ~
|
|
||||||
|
|
||||||
# -- Layer 7 Load Balancer hostname
|
host: xip.io
|
||||||
host: sslip.io
|
|
||||||
|
|
||||||
# -- Set this to true in order to enable TLS on the ingress record
|
## Set this to true in order to enable TLS on the ingress record
|
||||||
|
## A side effect of this will be that the backend service will be connected at port 443
|
||||||
tls: false
|
tls: false
|
||||||
|
|
||||||
# -- Enable this in order to enable that the backend service will be connected at port 443
|
## If TLS is set to true, you must declare what secret will store the key/certificate for TLS
|
||||||
secureBackends: false
|
|
||||||
|
|
||||||
# -- If TLS is set to true, you must declare what secret will store the key/certificate for TLS
|
|
||||||
tlsSecret: longhorn.local-tls
|
tlsSecret: longhorn.local-tls
|
||||||
|
|
||||||
# -- If ingress is enabled you can set the default ingress path
|
## Ingress annotations done as key:value pairs
|
||||||
# then you can access the UI by using the following full path {{host}}+{{path}}
|
|
||||||
path: /
|
|
||||||
|
|
||||||
## If you're using kube-lego, you will want to add:
|
## If you're using kube-lego, you will want to add:
|
||||||
## kubernetes.io/tls-acme: true
|
## kubernetes.io/tls-acme: true
|
||||||
##
|
##
|
||||||
@ -436,12 +136,10 @@ ingress:
|
|||||||
## ref: https://github.com/kubernetes/ingress-nginx/blob/master/docs/annotations.md
|
## ref: https://github.com/kubernetes/ingress-nginx/blob/master/docs/annotations.md
|
||||||
##
|
##
|
||||||
## If tls is set to true, annotation ingress.kubernetes.io/secure-backends: "true" will automatically be set
|
## If tls is set to true, annotation ingress.kubernetes.io/secure-backends: "true" will automatically be set
|
||||||
# -- Ingress annotations done as key:value pairs
|
|
||||||
annotations:
|
annotations:
|
||||||
# kubernetes.io/ingress.class: nginx
|
# kubernetes.io/ingress.class: nginx
|
||||||
# kubernetes.io/tls-acme: true
|
# kubernetes.io/tls-acme: true
|
||||||
|
|
||||||
# -- If you're providing your own certificates, please use this to add the certificates as secrets
|
|
||||||
secrets:
|
secrets:
|
||||||
## If you're providing your own certificates, please use this to add the certificates as secrets
|
## If you're providing your own certificates, please use this to add the certificates as secrets
|
||||||
## key and certificate should start with -----BEGIN CERTIFICATE----- or
|
## key and certificate should start with -----BEGIN CERTIFICATE----- or
|
||||||
@ -456,25 +154,9 @@ ingress:
|
|||||||
# key:
|
# key:
|
||||||
# certificate:
|
# certificate:
|
||||||
|
|
||||||
# -- For Kubernetes < v1.25, if your cluster enables Pod Security Policy admission controller,
|
# Configure a pod security policy in the Longhorn namespace to allow privileged pods
|
||||||
# set this to `true` to ship longhorn-psp which allow privileged Longhorn pods to start
|
enablePSP: true
|
||||||
enablePSP: false
|
|
||||||
|
|
||||||
# -- Annotations to add to the Longhorn Manager DaemonSet Pods. Optional.
|
## Specify override namespace, specifically this is useful for using longhorn as sub-chart
|
||||||
annotations: {}
|
## and its release namespace is not the `longhorn-system`
|
||||||
|
namespaceOverride: ""
|
||||||
serviceAccount:
|
|
||||||
# -- Annotations to add to the service account
|
|
||||||
annotations: {}
|
|
||||||
|
|
||||||
## openshift settings
|
|
||||||
openshift:
|
|
||||||
# -- Enable when using openshift
|
|
||||||
enabled: false
|
|
||||||
ui:
|
|
||||||
# -- UI route in openshift environment
|
|
||||||
route: "longhorn-ui"
|
|
||||||
# -- UI port in openshift environment
|
|
||||||
port: 443
|
|
||||||
# -- UI proxy in openshift environment
|
|
||||||
proxy: 8443
|
|
||||||
|
|||||||
@ -1,48 +0,0 @@
|
|||||||
# same secret for longhorn-system namespace
|
|
||||||
apiVersion: v1
|
|
||||||
kind: Secret
|
|
||||||
metadata:
|
|
||||||
name: azblob-secret
|
|
||||||
namespace: longhorn-system
|
|
||||||
type: Opaque
|
|
||||||
data:
|
|
||||||
AZBLOB_ACCOUNT_NAME: ZGV2c3RvcmVhY2NvdW50MQ==
|
|
||||||
AZBLOB_ACCOUNT_KEY: RWJ5OHZkTTAyeE5PY3FGbHFVd0pQTGxtRXRsQ0RYSjFPVXpGVDUwdVNSWjZJRnN1RnEyVVZFckN6NEk2dHEvSzFTWkZQVE90ci9LQkhCZWtzb0dNR3c9PQ==
|
|
||||||
AZBLOB_ENDPOINT: aHR0cDovL2F6YmxvYi1zZXJ2aWNlLmRlZmF1bHQ6MTAwMDAv
|
|
||||||
---
|
|
||||||
apiVersion: apps/v1
|
|
||||||
kind: Deployment
|
|
||||||
metadata:
|
|
||||||
name: longhorn-test-azblob
|
|
||||||
namespace: default
|
|
||||||
labels:
|
|
||||||
app: longhorn-test-azblob
|
|
||||||
spec:
|
|
||||||
replicas: 1
|
|
||||||
selector:
|
|
||||||
matchLabels:
|
|
||||||
app: longhorn-test-azblob
|
|
||||||
template:
|
|
||||||
metadata:
|
|
||||||
labels:
|
|
||||||
app: longhorn-test-azblob
|
|
||||||
spec:
|
|
||||||
containers:
|
|
||||||
- name: azurite
|
|
||||||
image: mcr.microsoft.com/azure-storage/azurite:3.23.0
|
|
||||||
ports:
|
|
||||||
- containerPort: 10000
|
|
||||||
---
|
|
||||||
apiVersion: v1
|
|
||||||
kind: Service
|
|
||||||
metadata:
|
|
||||||
name: azblob-service
|
|
||||||
namespace: default
|
|
||||||
spec:
|
|
||||||
selector:
|
|
||||||
app: longhorn-test-azblob
|
|
||||||
ports:
|
|
||||||
- port: 10000
|
|
||||||
targetPort: 10000
|
|
||||||
protocol: TCP
|
|
||||||
sessionAffinity: ClientIP
|
|
||||||
@ -1,87 +0,0 @@
|
|||||||
apiVersion: v1
|
|
||||||
kind: Secret
|
|
||||||
metadata:
|
|
||||||
name: cifs-secret
|
|
||||||
namespace: longhorn-system
|
|
||||||
type: Opaque
|
|
||||||
data:
|
|
||||||
CIFS_USERNAME: bG9uZ2hvcm4tY2lmcy11c2VybmFtZQ== # longhorn-cifs-username
|
|
||||||
CIFS_PASSWORD: bG9uZ2hvcm4tY2lmcy1wYXNzd29yZA== # longhorn-cifs-password
|
|
||||||
---
|
|
||||||
apiVersion: v1
|
|
||||||
kind: Secret
|
|
||||||
metadata:
|
|
||||||
name: cifs-secret
|
|
||||||
namespace: default
|
|
||||||
type: Opaque
|
|
||||||
data:
|
|
||||||
CIFS_USERNAME: bG9uZ2hvcm4tY2lmcy11c2VybmFtZQ== # longhorn-cifs-username
|
|
||||||
CIFS_PASSWORD: bG9uZ2hvcm4tY2lmcy1wYXNzd29yZA== # longhorn-cifs-password
|
|
||||||
---
|
|
||||||
apiVersion: apps/v1
|
|
||||||
kind: Deployment
|
|
||||||
metadata:
|
|
||||||
name: longhorn-test-cifs
|
|
||||||
namespace: default
|
|
||||||
labels:
|
|
||||||
app: longhorn-test-cifs
|
|
||||||
spec:
|
|
||||||
replicas: 1
|
|
||||||
selector:
|
|
||||||
matchLabels:
|
|
||||||
app: longhorn-test-cifs
|
|
||||||
template:
|
|
||||||
metadata:
|
|
||||||
labels:
|
|
||||||
app: longhorn-test-cifs
|
|
||||||
spec:
|
|
||||||
volumes:
|
|
||||||
- name: cifs-volume
|
|
||||||
emptyDir: {}
|
|
||||||
containers:
|
|
||||||
- name: longhorn-test-cifs-container
|
|
||||||
image: derekbit/samba:latest
|
|
||||||
ports:
|
|
||||||
- containerPort: 139
|
|
||||||
- containerPort: 445
|
|
||||||
imagePullPolicy: Always
|
|
||||||
env:
|
|
||||||
- name: EXPORT_PATH
|
|
||||||
value: /opt/backupstore
|
|
||||||
- name: CIFS_DISK_IMAGE_SIZE_MB
|
|
||||||
value: "4096"
|
|
||||||
- name: CIFS_USERNAME
|
|
||||||
valueFrom:
|
|
||||||
secretKeyRef:
|
|
||||||
name: cifs-secret
|
|
||||||
key: CIFS_USERNAME
|
|
||||||
- name: CIFS_PASSWORD
|
|
||||||
valueFrom:
|
|
||||||
secretKeyRef:
|
|
||||||
name: cifs-secret
|
|
||||||
key: CIFS_PASSWORD
|
|
||||||
securityContext:
|
|
||||||
privileged: true
|
|
||||||
capabilities:
|
|
||||||
add: ["SYS_ADMIN", "DAC_READ_SEARCH"]
|
|
||||||
volumeMounts:
|
|
||||||
- name: cifs-volume
|
|
||||||
mountPath: "/opt/backupstore"
|
|
||||||
args: ["-u", "$(CIFS_USERNAME);$(CIFS_PASSWORD)", "-s", "backupstore;$(EXPORT_PATH);yes;no;no;all;none"]
|
|
||||||
---
|
|
||||||
kind: Service
|
|
||||||
apiVersion: v1
|
|
||||||
metadata:
|
|
||||||
name: longhorn-test-cifs-svc
|
|
||||||
namespace: default
|
|
||||||
spec:
|
|
||||||
selector:
|
|
||||||
app: longhorn-test-cifs
|
|
||||||
clusterIP: None
|
|
||||||
ports:
|
|
||||||
- name: netbios-port
|
|
||||||
port: 139
|
|
||||||
targetPort: 139
|
|
||||||
- name: microsoft-port
|
|
||||||
port: 445
|
|
||||||
targetPort: 445
|
|
||||||
@ -8,8 +8,8 @@ data:
|
|||||||
AWS_ACCESS_KEY_ID: bG9uZ2hvcm4tdGVzdC1hY2Nlc3Mta2V5 # longhorn-test-access-key
|
AWS_ACCESS_KEY_ID: bG9uZ2hvcm4tdGVzdC1hY2Nlc3Mta2V5 # longhorn-test-access-key
|
||||||
AWS_SECRET_ACCESS_KEY: bG9uZ2hvcm4tdGVzdC1zZWNyZXQta2V5 # longhorn-test-secret-key
|
AWS_SECRET_ACCESS_KEY: bG9uZ2hvcm4tdGVzdC1zZWNyZXQta2V5 # longhorn-test-secret-key
|
||||||
AWS_ENDPOINTS: aHR0cHM6Ly9taW5pby1zZXJ2aWNlLmRlZmF1bHQ6OTAwMA== # https://minio-service.default:9000
|
AWS_ENDPOINTS: aHR0cHM6Ly9taW5pby1zZXJ2aWNlLmRlZmF1bHQ6OTAwMA== # https://minio-service.default:9000
|
||||||
AWS_CERT: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSURMRENDQWhTZ0F3SUJBZ0lSQU1kbzQycGhUZXlrMTcvYkxyWjVZRHN3RFFZSktvWklodmNOQVFFTEJRQXcKR2pFWU1CWUdBMVVFQ2hNUFRHOXVaMmh2Y200Z0xTQlVaWE4wTUNBWERUSXdNRFF5TnpJek1EQXhNVm9ZRHpJeApNakF3TkRBek1qTXdNREV4V2pBYU1SZ3dGZ1lEVlFRS0V3OU1iMjVuYUc5eWJpQXRJRlJsYzNRd2dnRWlNQTBHCkNTcUdTSWIzRFFFQkFRVUFBNElCRHdBd2dnRUtBb0lCQVFEWHpVdXJnUFpEZ3pUM0RZdWFlYmdld3Fvd2RlQUQKODRWWWF6ZlN1USs3K21Oa2lpUVBvelVVMmZvUWFGL1BxekJiUW1lZ29hT3l5NVhqM1VFeG1GcmV0eDBaRjVOVgpKTi85ZWFJNWRXRk9teHhpMElPUGI2T0RpbE1qcXVEbUVPSXljdjRTaCsvSWo5Zk1nS0tXUDdJZGxDNUJPeThkCncwOVdkckxxaE9WY3BKamNxYjN6K3hISHd5Q05YeGhoRm9tb2xQVnpJbnlUUEJTZkRuSDBuS0lHUXl2bGhCMGsKVHBHSzYxc2prZnFTK3hpNTlJeHVrbHZIRXNQcjFXblRzYU9oaVh6N3lQSlorcTNBMWZoVzBVa1JaRFlnWnNFbQovZ05KM3JwOFhZdURna2kzZ0UrOElXQWRBWHExeWhqRDdSSkI4VFNJYTV0SGpKUUtqZ0NlSG5HekFnTUJBQUdqCmF6QnBNQTRHQTFVZER3RUIvd1FFQXdJQ3BEQVRCZ05WSFNVRUREQUtCZ2dyQmdFRkJRY0RBVEFQQmdOVkhSTUIKQWY4RUJUQURBUUgvTURFR0ExVWRFUVFxTUNpQ0NXeHZZMkZzYUc5emRJSVZiV2x1YVc4dGMyVnlkbWxqWlM1awpaV1poZFd4MGh3Ui9BQUFCTUEwR0NTcUdTSWIzRFFFQkN3VUFBNElCQVFDbUZMMzlNSHVZMzFhMTFEajRwMjVjCnFQRUM0RHZJUWozTk9kU0dWMmQrZjZzZ3pGejFXTDhWcnF2QjFCMVM2cjRKYjJQRXVJQkQ4NFlwVXJIT1JNU2MKd3ViTEppSEtEa0Jmb2U5QWI1cC9VakpyS0tuajM0RGx2c1cvR3AwWTZYc1BWaVdpVWorb1JLbUdWSTI0Q0JIdgpnK0JtVzNDeU5RR1RLajk0eE02czNBV2xHRW95YXFXUGU1eHllVWUzZjFBWkY5N3RDaklKUmVWbENtaENGK0JtCmFUY1RSUWN3cVdvQ3AwYmJZcHlERFlwUmxxOEdQbElFOW8yWjZBc05mTHJVcGFtZ3FYMmtYa2gxa3lzSlEralAKelFadHJSMG1tdHVyM0RuRW0yYmk0TktIQVFIcFc5TXUxNkdRakUxTmJYcVF0VEI4OGpLNzZjdEg5MzRDYWw2VgotLS0tLUVORCBDRVJUSUZJQ0FURS0tLS0t
|
AWS_CERT: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUREekNDQWZlZ0F3SUJBZ0lSQU91d1oybTZ6SXl3c1h2a2UyNS9LYzB3RFFZSktvWklodmNOQVFFTEJRQXcKRWpFUU1BNEdBMVVFQ2hNSFFXTnRaU0JEYnpBZUZ3MHlNREEwTWpVd01qRTJNalphRncweU1UQTBNalV3TWpFMgpNalphTUJJeEVEQU9CZ05WQkFvVEIwRmpiV1VnUTI4d2dnRWlNQTBHQ1NxR1NJYjNEUUVCQVFVQUE0SUJEd0F3CmdnRUtBb0lCQVFEWkpyWVUraVJhc1huSExvb1d0Tm9OQWpxN0U3YWNlQTJQZnQ1ZFM3aExzVUtCbExMOVVQMmUKZ0QrVFl3RmtCWVJNU3BsV0tNT0tuWEErNDZSVkRwSkhwSTF4YjhHNDV0L3gzVXhVaWc2WUFVbDBnTFV6N01rMQpYSUtRaWZZUllaL0FjUzJqU0VOYjRISFJ1aFZ5NzV0ZDdCaXNhd2J2TTJwTXI0dWNSR1lwZ3J6Z2V2eFBXSHZ1CnkxT29yRnIvNjFwV28wcG9aSXhtRmM2YXMzekw0NWlrRzRHN1A2ejJPamc4NGdrdnR4RFUzYVdmWXRNb3VhL3gKQVhkRlRCd2NqMkNHMHJtdmd4cE5KeEx5Kzl5NDVLVGU1SFlSd0xxUjVCeWtnVGt2RGplcWdXTnJyQWdCL3lLTApwU1ZjRmZkKzBWNjhyQmtNMEt3VlQ3bXF2WWRsZDVrTkFnTUJBQUdqWURCZU1BNEdBMVVkRHdFQi93UUVBd0lDCnBEQVRCZ05WSFNVRUREQUtCZ2dyQmdFRkJRY0RBVEFQQmdOVkhSTUJBZjhFQlRBREFRSC9NQ1lHQTFVZEVRUWYKTUIyQ0ZXMXBibWx2TFhObGNuWnBZMlV1WkdWbVlYVnNkSWNFZndBQUFUQU5CZ2txaGtpRzl3MEJBUXNGQUFPQwpBUUVBdDBQYjM5QWliS0EyU1BPTHJHSmVRVlNaVTdZbFUyU0h0M2lhcFVBS1Rtb2o1RTQrTU8yV2NnbktoRktrCnNxeW9CYjBPYTNPMHdXUnRvVnhNUGdPQS9FaXNtZExQWmJIVTUzS2w3SDVWMm8rb0tQY0YydTk2ajdlcUZxSkUKMlltQkpBTHlUVks5LzZhS1hOSnRYZE5xRmpPMWJRcDJRTURXbjQyZGgyNjJLZmgvekM4enRyK0h4RzhuTVpQQwpsZUpxbzU3S0tkZ0YvZHVBWTdUaUI2cThTelE4RmViMklQQ2FhdVVLNzdBZ0d5b3kzK1JuWkdZV2U1MG1KVnN6CmdkQTFURmg0TVdMeUxWSFdIbnl2cEFvTjJIUjQrdzhYRkpJS2VRRFM1YklJM1pFeU5OQUZNRDg0bTVReGY4cjUKMEovQWhXTVVyMFUwcCtiRi9KM3FDQVNSK3c9PQotLS0tLUVORCBDRVJUSUZJQ0FURS0tLS0tCg==
|
||||||
AWS_CERT_KEY: LS0tLS1CRUdJTiBQUklWQVRFIEtFWS0tLS0tCk1JSUV2UUlCQURBTkJna3Foa2lHOXcwQkFRRUZBQVNDQktjd2dnU2pBZ0VBQW9JQkFRRFh6VXVyZ1BaRGd6VDMKRFl1YWViZ2V3cW93ZGVBRDg0VllhemZTdVErNyttTmtpaVFQb3pVVTJmb1FhRi9QcXpCYlFtZWdvYU95eTVYagozVUV4bUZyZXR4MFpGNU5WSk4vOWVhSTVkV0ZPbXh4aTBJT1BiNk9EaWxNanF1RG1FT0l5Y3Y0U2grL0lqOWZNCmdLS1dQN0lkbEM1Qk95OGR3MDlXZHJMcWhPVmNwSmpjcWIzeit4SEh3eUNOWHhoaEZvbW9sUFZ6SW55VFBCU2YKRG5IMG5LSUdReXZsaEIwa1RwR0s2MXNqa2ZxUyt4aTU5SXh1a2x2SEVzUHIxV25Uc2FPaGlYejd5UEpaK3EzQQoxZmhXMFVrUlpEWWdac0VtL2dOSjNycDhYWXVEZ2tpM2dFKzhJV0FkQVhxMXloakQ3UkpCOFRTSWE1dEhqSlFLCmpnQ2VIbkd6QWdNQkFBRUNnZ0VBZlVyQ1hrYTN0Q2JmZjNpcnp2cFFmZnVEbURNMzV0TmlYaDJTQVpSVW9FMFYKbSsvZ1UvdnIrN2s2eUgvdzhMOXhpZXFhQTljVkZkL0JuTlIrMzI2WGc2dEpCNko2ZGZxODJZdmZOZ0VDaUFMaQpqalNGemFlQmhnT3ZsWXZHbTR5OTU1Q0FGdjQ1cDNac1VsMTFDRXJlL1BGbGtaWHRHeGlrWFl6NC85UTgzblhZCnM2eDdPYTgyUjdwT2lraWh3Q0FvVTU3Rjc4ZWFKOG1xTmkwRlF2bHlxSk9QMTFCbVp4dm54ZU11S2poQjlPTnAKTFNwMWpzZXk5bDZNR2pVbjBGTG53RHZkVWRiK0ZlUEkxTjdWYUNBd3hJK3JHa3JTWkhnekhWWE92VUpON2t2QQpqNUZPNW9uNGgvK3hXbkYzM3lxZ0VvWWZ0MFFJL2pXS2NOV1d1a2pCd1FLQmdRRGVFNlJGRUpsT2Q1aVcxeW1qCm45RENnczVFbXFtRXN3WU95bkN3U2RhK1lNNnZVYmlac1k4WW9wMVRmVWN4cUh2NkFQWGpVd2NBUG1QVE9KRW8KMlJtS0xTYkhsTnc4bFNOMWJsWDBEL3Mzamc1R3VlVW9nbW5TVnhMa0h1OFhKR0o3VzFReEUzZG9IUHRrcTNpagpoa09QTnJpZFM0UmxqNTJwYkhscjUvQzRjUUtCZ1FENHhFYmpuck1heFV2b0xxVTRvT2xiOVc5UytSUllTc0cxCmxJUmgzNzZTV0ZuTTlSdGoyMTI0M1hkaE4zUFBtSTNNeiswYjdyMnZSUi9LMS9Cc1JUQnlrTi9kbkVuNVUxQkEKYm90cGZIS1Jvc1FUR1hIQkEvM0JrNC9qOWplU3RmVXgzZ2x3eUI0L2hORy9KM1ZVV2FXeURTRm5qZFEvcGJsRwp6VWlsSVBmK1l3S0JnUUNwMkdYYmVJMTN5TnBJQ3psS2JqRlFncEJWUWVDQ29CVHkvUHRncUtoM3BEeVBNN1kyCnZla09VMWgyQVN1UkhDWHRtQXgzRndvVXNxTFFhY1FEZEw4bXdjK1Y5eERWdU02TXdwMDBjNENVQmE1L2d5OXoKWXdLaUgzeFFRaVJrRTZ6S1laZ3JqSkxYYXNzT1BHS2cxbEFYV1NlckRaV3R3MEEyMHNLdXQ0NlEwUUtCZ0hGZQpxZHZVR0ZXcjhvTDJ0dzlPcmVyZHVJVTh4RnZVZmVFdHRRTVJ2N3pjRE5qT0gxUnJ4Wk9aUW0ySW92dkp6MTIyCnFKMWhPUXJtV3EzTHFXTCtTU3o4L3pqMG4vWERWVUIzNElzTFR2ODJDVnVXN2ZPRHlTSnVDRlpnZ0VVWkxZd3oKWDJRSm4xZGRSV1Z6S3hKczVJbDNXSERqL3dXZWxnaEJSOGtSZEZOM0FvR0FJNldDdjJQQ1lUS1ZZNjAwOFYwbgpyTDQ3YTlPanZ0Yy81S2ZxSjFpMkpKTUgyQi9jbU1WRSs4M2dpODFIU1FqMWErNnBjektmQVppZWcwRk9nL015ClB6VlZRYmpKTnY0QzM5KzdxSDg1WGdZTXZhcTJ0aDFEZWUvQ3NsMlM4QlV0cW5mc0VuMUYwcWhlWUJZb2RibHAKV3RUaE5oRi9oRVhzbkJROURyWkJKT1U9Ci0tLS0tRU5EIFBSSVZBVEUgS0VZLS0tLS0K
|
AWS_CERT_KEY: LS0tLS1CRUdJTiBQUklWQVRFIEtFWS0tLS0tCk1JSUV2UUlCQURBTkJna3Foa2lHOXcwQkFRRUZBQVNDQktjd2dnU2pBZ0VBQW9JQkFRRFpKcllVK2lSYXNYbkgKTG9vV3ROb05BanE3RTdhY2VBMlBmdDVkUzdoTHNVS0JsTEw5VVAyZWdEK1RZd0ZrQllSTVNwbFdLTU9LblhBKwo0NlJWRHBKSHBJMXhiOEc0NXQveDNVeFVpZzZZQVVsMGdMVXo3TWsxWElLUWlmWVJZWi9BY1MyalNFTmI0SEhSCnVoVnk3NXRkN0Jpc2F3YnZNMnBNcjR1Y1JHWXBncnpnZXZ4UFdIdnV5MU9vckZyLzYxcFdvMHBvWkl4bUZjNmEKczN6TDQ1aWtHNEc3UDZ6Mk9qZzg0Z2t2dHhEVTNhV2ZZdE1vdWEveEFYZEZUQndjajJDRzBybXZneHBOSnhMeQorOXk0NUtUZTVIWVJ3THFSNUJ5a2dUa3ZEamVxZ1dOcnJBZ0IveUtMcFNWY0ZmZCswVjY4ckJrTTBLd1ZUN21xCnZZZGxkNWtOQWdNQkFBRUNnZ0VBQUlwREc2dy9tT1ltR21PNFBqUTI4cDlWekE5UmZmUWlmSC9oUjdRZmdqaXYKcEtqZEJScEZkelowY2dabUEzeXNCcENNN3hUczM1UmlxaFZnM0VGTUJkZVg3bmRMc1EwSjg0ME1XbzE1V2RGdgpBRll0blRKeWthcG9QTG5MSGVIelJzUkJTODJyTlRoS3NDM1pUYzdnd1F3TVI2bUFlK25SMHQwQTZPT1dxWFhECm5ENmdmdk9vNXJqUjE2WFhibE9vMkIwQ2RITStIb3lXTjJhbXhVL1pUNUlsVGFjVDBHT0FaajN4QW4yclRqSTYKRXRsRGx2cUhIYy8vY3c3ck1xSHZFVEdNbnBjakpRaEZic0pmR2p2OHcxSFQ3VFd6dHphdXZoektkbHBRakc3VgpJcFlsTXBObHl1RzJVVDJqQnBEcXIyT0hqTE5CWktXWFNVL0x3VWU5WVFLQmdRRHFWVzJRcUNVNmhxalQvMHlICml6OFVOK2J3ZHdKZ2tZdXRmQWxkbG94OG1WZ1BYZHdnVkZnNUFkZktLa2hLRkhBN3Nad1dnRFA2Mlovd0IxZWEKRVNIVkZYc1V5ay9pMjQ1THVUQm5UcGRIUXNTc0F3TGl0MVFRZk16dWxiR0ZYdHlUSVkrU3FVbGhCeXY0ckg5aApRakpFYWFTcEhxZzhFeGt0VjNqUVNqRVM1UUtCZ1FEdE9wVGxQMHlkZUVkT1BZQ3ZFWllFZzNzUStiWVdLMkdwCnh1dlF2UUZTV2lVRXZpcEd5OHJGaGVRb1dyOHh3cnVFZ25MUEg3TWFwSTBYcFFpRjQvVVZjNFBweDczWFg2cmwKQkxRZUZWbnZNR1lUMElDMWJ5Ty9oUmw1ZlhGRXdOWXQzVTE4RVJteFg0N1poVUZienNYNDNPYU5hUGVha1NpRQpvQmlpa2R4RENRS0JnRU5mK3BlYjhOQktCV0tteGI4M0J4VHVHY1ZMd25BM2lMeUJyRU92VklkQ283SVBYNG9nCkZobVY4UkJjWmRwKzArSWw1K1lFU0cyNGdxYkZ4YWN6ZzlHN1VsOGc2Q1VtMFZ2dVMvOTM5a0R6N280eWMzTHkKR1FhQWkzK1JwSy9mSFhaa01ONlBNOXprN2Z5YXhDa1htbEpYT1pPeWo5WnQrMUF4RlRoMkRIUU5Bb0dCQU9JSgpXSWdheVRpZHUydU1aSW5yT3NMd09KblRKVEY0Z21VUG1lL1p0Mkd0Yk9wWSs5VmJKc2tRSzNaY0NTTXp4aEtiCmJTTjNzK05sK040WHJNaE9qVjYwSTNQa2t6bWMrU3VnVUxMOWF5VGlPOUVUY1IvdlZ1T013ZG9sc1lCdU1XV2cKSU0xZlNkamRFVEtucXIvOGhGdjh0MXowTUVEQm9SYkZxTk4ySWFacEFvR0FKVUN5SFcyS1o4cWJlWkJleW9PWApxeDF2VFVMRWtDMkdjZCs2a3VQdGlxdEpxMWVGNmc1N1BNWktoUHpoeTVVcGlxeDZZS1hrQ0tqZDlVc3FNQ2pNCm5KU2pJY3VXOWxFTmdCRmlWYjVzVVViTDdDVlhUalJkM1hab3BvemMyZjc5a1lNazVzYVpoWDdHL2Y3aGM1WWoKNUxqbkVJTWw3WWRyeUNsOHRyZjA0em89Ci0tLS0tRU5EIFBSSVZBVEUgS0VZLS0tLS0K
|
||||||
---
|
---
|
||||||
# same secret for longhorn-system namespace
|
# same secret for longhorn-system namespace
|
||||||
apiVersion: v1
|
apiVersion: v1
|
||||||
@ -22,24 +22,15 @@ data:
|
|||||||
AWS_ACCESS_KEY_ID: bG9uZ2hvcm4tdGVzdC1hY2Nlc3Mta2V5 # longhorn-test-access-key
|
AWS_ACCESS_KEY_ID: bG9uZ2hvcm4tdGVzdC1hY2Nlc3Mta2V5 # longhorn-test-access-key
|
||||||
AWS_SECRET_ACCESS_KEY: bG9uZ2hvcm4tdGVzdC1zZWNyZXQta2V5 # longhorn-test-secret-key
|
AWS_SECRET_ACCESS_KEY: bG9uZ2hvcm4tdGVzdC1zZWNyZXQta2V5 # longhorn-test-secret-key
|
||||||
AWS_ENDPOINTS: aHR0cHM6Ly9taW5pby1zZXJ2aWNlLmRlZmF1bHQ6OTAwMA== # https://minio-service.default:9000
|
AWS_ENDPOINTS: aHR0cHM6Ly9taW5pby1zZXJ2aWNlLmRlZmF1bHQ6OTAwMA== # https://minio-service.default:9000
|
||||||
AWS_CERT: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSURMRENDQWhTZ0F3SUJBZ0lSQU1kbzQycGhUZXlrMTcvYkxyWjVZRHN3RFFZSktvWklodmNOQVFFTEJRQXcKR2pFWU1CWUdBMVVFQ2hNUFRHOXVaMmh2Y200Z0xTQlVaWE4wTUNBWERUSXdNRFF5TnpJek1EQXhNVm9ZRHpJeApNakF3TkRBek1qTXdNREV4V2pBYU1SZ3dGZ1lEVlFRS0V3OU1iMjVuYUc5eWJpQXRJRlJsYzNRd2dnRWlNQTBHCkNTcUdTSWIzRFFFQkFRVUFBNElCRHdBd2dnRUtBb0lCQVFEWHpVdXJnUFpEZ3pUM0RZdWFlYmdld3Fvd2RlQUQKODRWWWF6ZlN1USs3K21Oa2lpUVBvelVVMmZvUWFGL1BxekJiUW1lZ29hT3l5NVhqM1VFeG1GcmV0eDBaRjVOVgpKTi85ZWFJNWRXRk9teHhpMElPUGI2T0RpbE1qcXVEbUVPSXljdjRTaCsvSWo5Zk1nS0tXUDdJZGxDNUJPeThkCncwOVdkckxxaE9WY3BKamNxYjN6K3hISHd5Q05YeGhoRm9tb2xQVnpJbnlUUEJTZkRuSDBuS0lHUXl2bGhCMGsKVHBHSzYxc2prZnFTK3hpNTlJeHVrbHZIRXNQcjFXblRzYU9oaVh6N3lQSlorcTNBMWZoVzBVa1JaRFlnWnNFbQovZ05KM3JwOFhZdURna2kzZ0UrOElXQWRBWHExeWhqRDdSSkI4VFNJYTV0SGpKUUtqZ0NlSG5HekFnTUJBQUdqCmF6QnBNQTRHQTFVZER3RUIvd1FFQXdJQ3BEQVRCZ05WSFNVRUREQUtCZ2dyQmdFRkJRY0RBVEFQQmdOVkhSTUIKQWY4RUJUQURBUUgvTURFR0ExVWRFUVFxTUNpQ0NXeHZZMkZzYUc5emRJSVZiV2x1YVc4dGMyVnlkbWxqWlM1awpaV1poZFd4MGh3Ui9BQUFCTUEwR0NTcUdTSWIzRFFFQkN3VUFBNElCQVFDbUZMMzlNSHVZMzFhMTFEajRwMjVjCnFQRUM0RHZJUWozTk9kU0dWMmQrZjZzZ3pGejFXTDhWcnF2QjFCMVM2cjRKYjJQRXVJQkQ4NFlwVXJIT1JNU2MKd3ViTEppSEtEa0Jmb2U5QWI1cC9VakpyS0tuajM0RGx2c1cvR3AwWTZYc1BWaVdpVWorb1JLbUdWSTI0Q0JIdgpnK0JtVzNDeU5RR1RLajk0eE02czNBV2xHRW95YXFXUGU1eHllVWUzZjFBWkY5N3RDaklKUmVWbENtaENGK0JtCmFUY1RSUWN3cVdvQ3AwYmJZcHlERFlwUmxxOEdQbElFOW8yWjZBc05mTHJVcGFtZ3FYMmtYa2gxa3lzSlEralAKelFadHJSMG1tdHVyM0RuRW0yYmk0TktIQVFIcFc5TXUxNkdRakUxTmJYcVF0VEI4OGpLNzZjdEg5MzRDYWw2VgotLS0tLUVORCBDRVJUSUZJQ0FURS0tLS0t
|
AWS_CERT: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUREekNDQWZlZ0F3SUJBZ0lSQU91d1oybTZ6SXl3c1h2a2UyNS9LYzB3RFFZSktvWklodmNOQVFFTEJRQXcKRWpFUU1BNEdBMVVFQ2hNSFFXTnRaU0JEYnpBZUZ3MHlNREEwTWpVd01qRTJNalphRncweU1UQTBNalV3TWpFMgpNalphTUJJeEVEQU9CZ05WQkFvVEIwRmpiV1VnUTI4d2dnRWlNQTBHQ1NxR1NJYjNEUUVCQVFVQUE0SUJEd0F3CmdnRUtBb0lCQVFEWkpyWVUraVJhc1huSExvb1d0Tm9OQWpxN0U3YWNlQTJQZnQ1ZFM3aExzVUtCbExMOVVQMmUKZ0QrVFl3RmtCWVJNU3BsV0tNT0tuWEErNDZSVkRwSkhwSTF4YjhHNDV0L3gzVXhVaWc2WUFVbDBnTFV6N01rMQpYSUtRaWZZUllaL0FjUzJqU0VOYjRISFJ1aFZ5NzV0ZDdCaXNhd2J2TTJwTXI0dWNSR1lwZ3J6Z2V2eFBXSHZ1CnkxT29yRnIvNjFwV28wcG9aSXhtRmM2YXMzekw0NWlrRzRHN1A2ejJPamc4NGdrdnR4RFUzYVdmWXRNb3VhL3gKQVhkRlRCd2NqMkNHMHJtdmd4cE5KeEx5Kzl5NDVLVGU1SFlSd0xxUjVCeWtnVGt2RGplcWdXTnJyQWdCL3lLTApwU1ZjRmZkKzBWNjhyQmtNMEt3VlQ3bXF2WWRsZDVrTkFnTUJBQUdqWURCZU1BNEdBMVVkRHdFQi93UUVBd0lDCnBEQVRCZ05WSFNVRUREQUtCZ2dyQmdFRkJRY0RBVEFQQmdOVkhSTUJBZjhFQlRBREFRSC9NQ1lHQTFVZEVRUWYKTUIyQ0ZXMXBibWx2TFhObGNuWnBZMlV1WkdWbVlYVnNkSWNFZndBQUFUQU5CZ2txaGtpRzl3MEJBUXNGQUFPQwpBUUVBdDBQYjM5QWliS0EyU1BPTHJHSmVRVlNaVTdZbFUyU0h0M2lhcFVBS1Rtb2o1RTQrTU8yV2NnbktoRktrCnNxeW9CYjBPYTNPMHdXUnRvVnhNUGdPQS9FaXNtZExQWmJIVTUzS2w3SDVWMm8rb0tQY0YydTk2ajdlcUZxSkUKMlltQkpBTHlUVks5LzZhS1hOSnRYZE5xRmpPMWJRcDJRTURXbjQyZGgyNjJLZmgvekM4enRyK0h4RzhuTVpQQwpsZUpxbzU3S0tkZ0YvZHVBWTdUaUI2cThTelE4RmViMklQQ2FhdVVLNzdBZ0d5b3kzK1JuWkdZV2U1MG1KVnN6CmdkQTFURmg0TVdMeUxWSFdIbnl2cEFvTjJIUjQrdzhYRkpJS2VRRFM1YklJM1pFeU5OQUZNRDg0bTVReGY4cjUKMEovQWhXTVVyMFUwcCtiRi9KM3FDQVNSK3c9PQotLS0tLUVORCBDRVJUSUZJQ0FURS0tLS0tCg==
|
||||||
---
|
---
|
||||||
apiVersion: apps/v1
|
apiVersion: v1
|
||||||
kind: Deployment
|
kind: Pod
|
||||||
metadata:
|
metadata:
|
||||||
name: longhorn-test-minio
|
name: longhorn-test-minio
|
||||||
namespace: default
|
namespace: default
|
||||||
labels:
|
labels:
|
||||||
app: longhorn-test-minio
|
app: longhorn-test-minio
|
||||||
spec:
|
|
||||||
replicas: 1
|
|
||||||
selector:
|
|
||||||
matchLabels:
|
|
||||||
app: longhorn-test-minio
|
|
||||||
template:
|
|
||||||
metadata:
|
|
||||||
labels:
|
|
||||||
app: longhorn-test-minio
|
|
||||||
spec:
|
spec:
|
||||||
volumes:
|
volumes:
|
||||||
- name: minio-volume
|
- name: minio-volume
|
||||||
@ -52,17 +43,18 @@ spec:
|
|||||||
path: public.crt
|
path: public.crt
|
||||||
- key: AWS_CERT_KEY
|
- key: AWS_CERT_KEY
|
||||||
path: private.key
|
path: private.key
|
||||||
|
|
||||||
containers:
|
containers:
|
||||||
- name: minio
|
- name: minio
|
||||||
image: minio/minio:RELEASE.2022-02-01T18-00-14Z
|
image: longhornio/minio:RELEASE.2020-10-18T21-54-12Z
|
||||||
command: ["sh", "-c", "mkdir -p /storage/backupbucket && mkdir -p /root/.minio/certs && ln -s /root/certs/private.key /root/.minio/certs/private.key && ln -s /root/certs/public.crt /root/.minio/certs/public.crt && exec minio server /storage"]
|
command: ["sh", "-c", "mkdir -p /storage/backupbucket && mkdir -p /root/.minio/certs && ln -s /root/certs/private.key /root/.minio/certs/private.key && ln -s /root/certs/public.crt /root/.minio/certs/public.crt && exec /usr/bin/minio server /storage"]
|
||||||
env:
|
env:
|
||||||
- name: MINIO_ROOT_USER
|
- name: MINIO_ACCESS_KEY
|
||||||
valueFrom:
|
valueFrom:
|
||||||
secretKeyRef:
|
secretKeyRef:
|
||||||
name: minio-secret
|
name: minio-secret
|
||||||
key: AWS_ACCESS_KEY_ID
|
key: AWS_ACCESS_KEY_ID
|
||||||
- name: MINIO_ROOT_PASSWORD
|
- name: MINIO_SECRET_KEY
|
||||||
valueFrom:
|
valueFrom:
|
||||||
secretKeyRef:
|
secretKeyRef:
|
||||||
name: minio-secret
|
name: minio-secret
|
||||||
|
|||||||
@ -1,18 +1,10 @@
|
|||||||
apiVersion: apps/v1
|
apiVersion: v1
|
||||||
kind: Deployment
|
kind: Pod
|
||||||
metadata:
|
metadata:
|
||||||
name: longhorn-test-nfs
|
name: longhorn-test-nfs
|
||||||
namespace: default
|
namespace: default
|
||||||
labels:
|
labels:
|
||||||
app: longhorn-test-nfs
|
app: longhorn-test-nfs
|
||||||
spec:
|
|
||||||
selector:
|
|
||||||
matchLabels:
|
|
||||||
app: longhorn-test-nfs
|
|
||||||
template:
|
|
||||||
metadata:
|
|
||||||
labels:
|
|
||||||
app: longhorn-test-nfs
|
|
||||||
spec:
|
spec:
|
||||||
volumes:
|
volumes:
|
||||||
- name: nfs-volume
|
- name: nfs-volume
|
||||||
@ -28,8 +20,6 @@ spec:
|
|||||||
value: /opt/backupstore
|
value: /opt/backupstore
|
||||||
- name: PSEUDO_PATH
|
- name: PSEUDO_PATH
|
||||||
value: /opt/backupstore
|
value: /opt/backupstore
|
||||||
- name: NFS_DISK_IMAGE_SIZE_MB
|
|
||||||
value: "4096"
|
|
||||||
command: ["bash", "-c", "chmod 700 /opt/backupstore && /opt/start_nfs.sh | tee /var/log/ganesha.log"]
|
command: ["bash", "-c", "chmod 700 /opt/backupstore && /opt/start_nfs.sh | tee /var/log/ganesha.log"]
|
||||||
securityContext:
|
securityContext:
|
||||||
privileged: true
|
privileged: true
|
||||||
@ -43,7 +33,6 @@ spec:
|
|||||||
command: ["bash", "-c", "grep \"No export entries found\" /var/log/ganesha.log > /dev/null 2>&1 ; [ $? -ne 0 ]"]
|
command: ["bash", "-c", "grep \"No export entries found\" /var/log/ganesha.log > /dev/null 2>&1 ; [ $? -ne 0 ]"]
|
||||||
initialDelaySeconds: 5
|
initialDelaySeconds: 5
|
||||||
periodSeconds: 5
|
periodSeconds: 5
|
||||||
timeoutSeconds: 4
|
|
||||||
---
|
---
|
||||||
kind: Service
|
kind: Service
|
||||||
apiVersion: v1
|
apiVersion: v1
|
||||||
|
|||||||
36
deploy/iscsi/longhorn-iscsi-installation.yaml
Normal file
36
deploy/iscsi/longhorn-iscsi-installation.yaml
Normal file
@ -0,0 +1,36 @@
|
|||||||
|
apiVersion: apps/v1
|
||||||
|
kind: DaemonSet
|
||||||
|
metadata:
|
||||||
|
name: longhorn-iscsi-installation
|
||||||
|
labels:
|
||||||
|
app: longhorn-iscsi-installation
|
||||||
|
annotations:
|
||||||
|
command: &cmd OS=$(grep "ID_LIKE" /etc/os-release | cut -d '=' -f 2); if [[ $OS == *"debian"* ]]; then apt-get update -qy && apt-get install -qy open-iscsi && sudo systemctl enable iscsid && sudo systemctl start iscsid; else yum install iscsi-initiator-utils -y && sudo systemctl enable iscsid && sudo systemctl start iscsid; fi && if [ $? -eq 0 ]; then echo "iscsi install successfully"; else echo "iscsi install failed error code " $?; fi
|
||||||
|
spec:
|
||||||
|
selector:
|
||||||
|
matchLabels:
|
||||||
|
app: longhorn-iscsi-installation
|
||||||
|
template:
|
||||||
|
metadata:
|
||||||
|
labels:
|
||||||
|
app: longhorn-iscsi-installation
|
||||||
|
spec:
|
||||||
|
hostNetwork: true
|
||||||
|
hostPID: true
|
||||||
|
initContainers:
|
||||||
|
- name: iscsi-installation
|
||||||
|
command:
|
||||||
|
- nsenter
|
||||||
|
- --mount=/proc/1/ns/mnt
|
||||||
|
- --
|
||||||
|
- sh
|
||||||
|
- -c
|
||||||
|
- *cmd
|
||||||
|
image: alpine:3.7
|
||||||
|
securityContext:
|
||||||
|
privileged: true
|
||||||
|
containers:
|
||||||
|
- name: sleep
|
||||||
|
image: k8s.gcr.io/pause:3.1
|
||||||
|
updateStrategy:
|
||||||
|
type: RollingUpdate
|
||||||
@ -1,13 +1,10 @@
|
|||||||
longhornio/csi-attacher:v4.2.0
|
longhornio/longhorn-engine:v1.1.0
|
||||||
longhornio/csi-provisioner:v3.4.1
|
longhornio/longhorn-instance-manager:v1_20201216
|
||||||
longhornio/csi-resizer:v1.7.0
|
longhornio/longhorn-share-manager:v1_20201204
|
||||||
longhornio/csi-snapshotter:v6.2.1
|
longhornio/longhorn-manager:v1.1.0
|
||||||
longhornio/csi-node-driver-registrar:v2.7.0
|
longhornio/longhorn-ui:v1.1.0
|
||||||
longhornio/livenessprobe:v2.9.0
|
longhornio/csi-attacher:v2.2.1-lh1
|
||||||
longhornio/backing-image-manager:master-head
|
longhornio/csi-provisioner:v1.6.0-lh1
|
||||||
longhornio/longhorn-engine:master-head
|
longhornio/csi-resizer:v0.5.1-lh1
|
||||||
longhornio/longhorn-instance-manager:master-head
|
longhornio/csi-snapshotter:v2.1.1-lh1
|
||||||
longhornio/longhorn-manager:master-head
|
longhornio/csi-node-driver-registrar:v1.2.0-lh1
|
||||||
longhornio/longhorn-share-manager:master-head
|
|
||||||
longhornio/longhorn-ui:master-head
|
|
||||||
longhornio/support-bundle-kit:v0.0.27
|
|
||||||
|
|||||||
4628
deploy/longhorn.yaml
4628
deploy/longhorn.yaml
File diff suppressed because it is too large
Load Diff
@ -1,61 +0,0 @@
|
|||||||
apiVersion: policy/v1beta1
|
|
||||||
kind: PodSecurityPolicy
|
|
||||||
metadata:
|
|
||||||
name: longhorn-psp
|
|
||||||
spec:
|
|
||||||
privileged: true
|
|
||||||
allowPrivilegeEscalation: true
|
|
||||||
requiredDropCapabilities:
|
|
||||||
- NET_RAW
|
|
||||||
allowedCapabilities:
|
|
||||||
- SYS_ADMIN
|
|
||||||
hostNetwork: false
|
|
||||||
hostIPC: false
|
|
||||||
hostPID: true
|
|
||||||
runAsUser:
|
|
||||||
rule: RunAsAny
|
|
||||||
seLinux:
|
|
||||||
rule: RunAsAny
|
|
||||||
fsGroup:
|
|
||||||
rule: RunAsAny
|
|
||||||
supplementalGroups:
|
|
||||||
rule: RunAsAny
|
|
||||||
volumes:
|
|
||||||
- configMap
|
|
||||||
- downwardAPI
|
|
||||||
- emptyDir
|
|
||||||
- secret
|
|
||||||
- projected
|
|
||||||
- hostPath
|
|
||||||
---
|
|
||||||
apiVersion: rbac.authorization.k8s.io/v1
|
|
||||||
kind: Role
|
|
||||||
metadata:
|
|
||||||
name: longhorn-psp-role
|
|
||||||
namespace: longhorn-system
|
|
||||||
rules:
|
|
||||||
- apiGroups:
|
|
||||||
- policy
|
|
||||||
resources:
|
|
||||||
- podsecuritypolicies
|
|
||||||
verbs:
|
|
||||||
- use
|
|
||||||
resourceNames:
|
|
||||||
- longhorn-psp
|
|
||||||
---
|
|
||||||
apiVersion: rbac.authorization.k8s.io/v1
|
|
||||||
kind: RoleBinding
|
|
||||||
metadata:
|
|
||||||
name: longhorn-psp-binding
|
|
||||||
namespace: longhorn-system
|
|
||||||
roleRef:
|
|
||||||
apiGroup: rbac.authorization.k8s.io
|
|
||||||
kind: Role
|
|
||||||
name: longhorn-psp-role
|
|
||||||
subjects:
|
|
||||||
- kind: ServiceAccount
|
|
||||||
name: longhorn-service-account
|
|
||||||
namespace: longhorn-system
|
|
||||||
- kind: ServiceAccount
|
|
||||||
name: default
|
|
||||||
namespace: longhorn-system
|
|
||||||
@ -1,36 +0,0 @@
|
|||||||
apiVersion: apps/v1
|
|
||||||
kind: DaemonSet
|
|
||||||
metadata:
|
|
||||||
name: longhorn-cifs-installation
|
|
||||||
labels:
|
|
||||||
app: longhorn-cifs-installation
|
|
||||||
annotations:
|
|
||||||
command: &cmd OS=$(grep -E "^ID_LIKE=" /etc/os-release | cut -d '=' -f 2); if [[ -z "${OS}" ]]; then OS=$(grep -E "^ID=" /etc/os-release | cut -d '=' -f 2); fi; if [[ "${OS}" == *"debian"* ]]; then sudo apt-get update -q -y && sudo apt-get install -q -y cifs-utils; elif [[ "${OS}" == *"suse"* ]]; then sudo zypper --gpg-auto-import-keys -q refresh && sudo zypper --gpg-auto-import-keys -q install -y cifs-utils; else sudo yum makecache -q -y && sudo yum --setopt=tsflags=noscripts install -q -y cifs-utils; fi && if [ $? -eq 0 ]; then echo "cifs install successfully"; else echo "cifs utilities install failed error code $?"; fi
|
|
||||||
spec:
|
|
||||||
selector:
|
|
||||||
matchLabels:
|
|
||||||
app: longhorn-cifs-installation
|
|
||||||
template:
|
|
||||||
metadata:
|
|
||||||
labels:
|
|
||||||
app: longhorn-cifs-installation
|
|
||||||
spec:
|
|
||||||
hostNetwork: true
|
|
||||||
hostPID: true
|
|
||||||
initContainers:
|
|
||||||
- name: cifs-installation
|
|
||||||
command:
|
|
||||||
- nsenter
|
|
||||||
- --mount=/proc/1/ns/mnt
|
|
||||||
- --
|
|
||||||
- bash
|
|
||||||
- -c
|
|
||||||
- *cmd
|
|
||||||
image: alpine:3.12
|
|
||||||
securityContext:
|
|
||||||
privileged: true
|
|
||||||
containers:
|
|
||||||
- name: sleep
|
|
||||||
image: registry.k8s.io/pause:3.1
|
|
||||||
updateStrategy:
|
|
||||||
type: RollingUpdate
|
|
||||||
@ -1,36 +0,0 @@
|
|||||||
apiVersion: apps/v1
|
|
||||||
kind: DaemonSet
|
|
||||||
metadata:
|
|
||||||
name: longhorn-iscsi-installation
|
|
||||||
labels:
|
|
||||||
app: longhorn-iscsi-installation
|
|
||||||
annotations:
|
|
||||||
command: &cmd OS=$(grep -E "^ID_LIKE=" /etc/os-release | cut -d '=' -f 2); if [[ -z "${OS}" ]]; then OS=$(grep -E "^ID=" /etc/os-release | cut -d '=' -f 2); fi; if [[ "${OS}" == *"debian"* ]]; then sudo apt-get update -q -y && sudo apt-get install -q -y open-iscsi && sudo systemctl -q enable iscsid && sudo systemctl start iscsid && sudo modprobe iscsi_tcp; elif [[ "${OS}" == *"suse"* ]]; then sudo zypper --gpg-auto-import-keys -q refresh && sudo zypper --gpg-auto-import-keys -q install -y open-iscsi && sudo systemctl -q enable iscsid && sudo systemctl start iscsid && sudo modprobe iscsi_tcp; else sudo yum makecache -q -y && sudo yum --setopt=tsflags=noscripts install -q -y iscsi-initiator-utils && echo "InitiatorName=$(/sbin/iscsi-iname)" > /etc/iscsi/initiatorname.iscsi && sudo systemctl -q enable iscsid && sudo systemctl start iscsid && sudo modprobe iscsi_tcp; fi && if [ $? -eq 0 ]; then echo "iscsi install successfully"; else echo "iscsi install failed error code $?"; fi
|
|
||||||
spec:
|
|
||||||
selector:
|
|
||||||
matchLabels:
|
|
||||||
app: longhorn-iscsi-installation
|
|
||||||
template:
|
|
||||||
metadata:
|
|
||||||
labels:
|
|
||||||
app: longhorn-iscsi-installation
|
|
||||||
spec:
|
|
||||||
hostNetwork: true
|
|
||||||
hostPID: true
|
|
||||||
initContainers:
|
|
||||||
- name: iscsi-installation
|
|
||||||
command:
|
|
||||||
- nsenter
|
|
||||||
- --mount=/proc/1/ns/mnt
|
|
||||||
- --
|
|
||||||
- bash
|
|
||||||
- -c
|
|
||||||
- *cmd
|
|
||||||
image: alpine:3.17
|
|
||||||
securityContext:
|
|
||||||
privileged: true
|
|
||||||
containers:
|
|
||||||
- name: sleep
|
|
||||||
image: registry.k8s.io/pause:3.1
|
|
||||||
updateStrategy:
|
|
||||||
type: RollingUpdate
|
|
||||||
@ -1,35 +0,0 @@
|
|||||||
apiVersion: apps/v1
|
|
||||||
kind: DaemonSet
|
|
||||||
metadata:
|
|
||||||
name: longhorn-iscsi-selinux-workaround
|
|
||||||
labels:
|
|
||||||
app: longhorn-iscsi-selinux-workaround
|
|
||||||
annotations:
|
|
||||||
command: &cmd if ! rpm -q policycoreutils > /dev/null 2>&1; then echo "failed to apply workaround; only applicable in Fedora based distros with SELinux enabled"; exit; elif cd /tmp && echo '(allow iscsid_t self (capability (dac_override)))' > local_longhorn.cil && semodule -vi local_longhorn.cil && rm -f local_longhorn.cil; then echo "applied workaround successfully"; else echo "failed to apply workaround; error code $?"; fi
|
|
||||||
spec:
|
|
||||||
selector:
|
|
||||||
matchLabels:
|
|
||||||
app: longhorn-iscsi-selinux-workaround
|
|
||||||
template:
|
|
||||||
metadata:
|
|
||||||
labels:
|
|
||||||
app: longhorn-iscsi-selinux-workaround
|
|
||||||
spec:
|
|
||||||
hostPID: true
|
|
||||||
initContainers:
|
|
||||||
- name: iscsi-selinux-workaround
|
|
||||||
command:
|
|
||||||
- nsenter
|
|
||||||
- --mount=/proc/1/ns/mnt
|
|
||||||
- --
|
|
||||||
- bash
|
|
||||||
- -c
|
|
||||||
- *cmd
|
|
||||||
image: alpine:3.17
|
|
||||||
securityContext:
|
|
||||||
privileged: true
|
|
||||||
containers:
|
|
||||||
- name: sleep
|
|
||||||
image: registry.k8s.io/pause:3.1
|
|
||||||
updateStrategy:
|
|
||||||
type: RollingUpdate
|
|
||||||
@ -1,36 +0,0 @@
|
|||||||
apiVersion: apps/v1
|
|
||||||
kind: DaemonSet
|
|
||||||
metadata:
|
|
||||||
name: longhorn-nfs-installation
|
|
||||||
labels:
|
|
||||||
app: longhorn-nfs-installation
|
|
||||||
annotations:
|
|
||||||
command: &cmd OS=$(grep -E "^ID_LIKE=" /etc/os-release | cut -d '=' -f 2); if [[ -z "${OS}" ]]; then OS=$(grep -E "^ID=" /etc/os-release | cut -d '=' -f 2); fi; if [[ "${OS}" == *"debian"* ]]; then sudo apt-get update -q -y && sudo apt-get install -q -y nfs-common && sudo modprobe nfs; elif [[ "${OS}" == *"suse"* ]]; then sudo zypper --gpg-auto-import-keys -q refresh && sudo zypper --gpg-auto-import-keys -q install -y nfs-client && sudo modprobe nfs; else sudo yum makecache -q -y && sudo yum --setopt=tsflags=noscripts install -q -y nfs-utils && sudo modprobe nfs; fi && if [ $? -eq 0 ]; then echo "nfs install successfully"; else echo "nfs install failed error code $?"; fi
|
|
||||||
spec:
|
|
||||||
selector:
|
|
||||||
matchLabels:
|
|
||||||
app: longhorn-nfs-installation
|
|
||||||
template:
|
|
||||||
metadata:
|
|
||||||
labels:
|
|
||||||
app: longhorn-nfs-installation
|
|
||||||
spec:
|
|
||||||
hostNetwork: true
|
|
||||||
hostPID: true
|
|
||||||
initContainers:
|
|
||||||
- name: nfs-installation
|
|
||||||
command:
|
|
||||||
- nsenter
|
|
||||||
- --mount=/proc/1/ns/mnt
|
|
||||||
- --
|
|
||||||
- bash
|
|
||||||
- -c
|
|
||||||
- *cmd
|
|
||||||
image: alpine:3.12
|
|
||||||
securityContext:
|
|
||||||
privileged: true
|
|
||||||
containers:
|
|
||||||
- name: sleep
|
|
||||||
image: registry.k8s.io/pause:3.1
|
|
||||||
updateStrategy:
|
|
||||||
type: RollingUpdate
|
|
||||||
@ -1,36 +0,0 @@
|
|||||||
apiVersion: apps/v1
|
|
||||||
kind: DaemonSet
|
|
||||||
metadata:
|
|
||||||
name: longhorn-nvme-cli-installation
|
|
||||||
labels:
|
|
||||||
app: longhorn-nvme-cli-installation
|
|
||||||
annotations:
|
|
||||||
command: &cmd OS=$(grep -E "^ID_LIKE=" /etc/os-release | cut -d '=' -f 2); if [[ -z "${OS}" ]]; then OS=$(grep -E "^ID=" /etc/os-release | cut -d '=' -f 2); fi; if [[ "${OS}" == *"debian"* ]]; then sudo apt-get update -q -y && sudo apt-get install -q -y nvme-cli && sudo modprobe nvme-tcp; elif [[ "${OS}" == *"suse"* ]]; then sudo zypper --gpg-auto-import-keys -q refresh && sudo zypper --gpg-auto-import-keys -q install -y nvme-cli && sudo modprobe nvme-tcp; else sudo yum makecache -q -y && sudo yum --setopt=tsflags=noscripts install -q -y nvme-cli && sudo modprobe nvme-tcp; fi && if [ $? -eq 0 ]; then echo "nvme-cli install successfully"; else echo "nvme-cli install failed error code $?"; fi
|
|
||||||
spec:
|
|
||||||
selector:
|
|
||||||
matchLabels:
|
|
||||||
app: longhorn-nvme-cli-installation
|
|
||||||
template:
|
|
||||||
metadata:
|
|
||||||
labels:
|
|
||||||
app: longhorn-nvme-cli-installation
|
|
||||||
spec:
|
|
||||||
hostNetwork: true
|
|
||||||
hostPID: true
|
|
||||||
initContainers:
|
|
||||||
- name: nvme-cli-installation
|
|
||||||
command:
|
|
||||||
- nsenter
|
|
||||||
- --mount=/proc/1/ns/mnt
|
|
||||||
- --
|
|
||||||
- bash
|
|
||||||
- -c
|
|
||||||
- *cmd
|
|
||||||
image: alpine:3.12
|
|
||||||
securityContext:
|
|
||||||
privileged: true
|
|
||||||
containers:
|
|
||||||
- name: sleep
|
|
||||||
image: registry.k8s.io/pause:3.1
|
|
||||||
updateStrategy:
|
|
||||||
type: RollingUpdate
|
|
||||||
@ -1,47 +0,0 @@
|
|||||||
apiVersion: apps/v1
|
|
||||||
kind: DaemonSet
|
|
||||||
metadata:
|
|
||||||
name: longhorn-spdk-setup
|
|
||||||
labels:
|
|
||||||
app: longhorn-spdk-setup
|
|
||||||
annotations:
|
|
||||||
command: &cmd OS=$(grep -E "^ID_LIKE=" /etc/os-release | cut -d '=' -f 2); if [[ -z "${OS}" ]]; then OS=$(grep -E "^ID=" /etc/os-release | cut -d '=' -f 2); fi; if [[ "${OS}" == *"debian"* ]]; then sudo apt-get update -q -y && sudo apt-get install -q -y git; elif [[ "${OS}" == *"suse"* ]]; then sudo zypper --gpg-auto-import-keys -q refresh && sudo zypper --gpg-auto-import-keys -q install -y git; else sudo yum makecache -q -y && sudo yum --setopt=tsflags=noscripts install -q -y git; fi && if [ $? -eq 0 ]; then echo "git install successfully"; else echo "git install failed error code $?"; fi && rm -rf ${SPDK_DIR}; git clone -b longhorn https://github.com/longhorn/spdk.git ${SPDK_DIR} && bash ${SPDK_DIR}/scripts/setup.sh ${SPDK_OPTION}; if [ $? -eq 0 ]; then echo "vm.nr_hugepages=$((HUGEMEM/2))" >> /etc/sysctl.conf; echo "SPDK environment is configured successfully"; else echo "Failed to configure SPDK environment error code $?"; fi; rm -rf ${SPDK_DIR}
|
|
||||||
spec:
|
|
||||||
selector:
|
|
||||||
matchLabels:
|
|
||||||
app: longhorn-spdk-setup
|
|
||||||
template:
|
|
||||||
metadata:
|
|
||||||
labels:
|
|
||||||
app: longhorn-spdk-setup
|
|
||||||
spec:
|
|
||||||
hostNetwork: true
|
|
||||||
hostPID: true
|
|
||||||
initContainers:
|
|
||||||
- name: longhorn-spdk-setup
|
|
||||||
command:
|
|
||||||
- nsenter
|
|
||||||
- --mount=/proc/1/ns/mnt
|
|
||||||
- --
|
|
||||||
- bash
|
|
||||||
- -c
|
|
||||||
- *cmd
|
|
||||||
image: alpine:3.12
|
|
||||||
env:
|
|
||||||
- name: SPDK_DIR
|
|
||||||
value: "/tmp/spdk"
|
|
||||||
- name: SPDK_OPTION
|
|
||||||
value: ""
|
|
||||||
- name: HUGEMEM
|
|
||||||
value: "1024"
|
|
||||||
- name: PCI_ALLOWED
|
|
||||||
value: "none"
|
|
||||||
- name: DRIVER_OVERRIDE
|
|
||||||
value: "uio_pci_generic"
|
|
||||||
securityContext:
|
|
||||||
privileged: true
|
|
||||||
containers:
|
|
||||||
- name: sleep
|
|
||||||
image: registry.k8s.io/pause:3.1
|
|
||||||
updateStrategy:
|
|
||||||
type: RollingUpdate
|
|
||||||
10
deploy/release-images.txt
Normal file
10
deploy/release-images.txt
Normal file
@ -0,0 +1,10 @@
|
|||||||
|
longhornio/longhorn-engine:v1.1.0
|
||||||
|
longhornio/longhorn-instance-manager:v1_20201216
|
||||||
|
longhornio/longhorn-share-manager:v1_20201204
|
||||||
|
longhornio/longhorn-manager:v1.1.0
|
||||||
|
longhornio/longhorn-ui:v1.1.0
|
||||||
|
longhornio/csi-attacher:v2.2.1-lh1
|
||||||
|
longhornio/csi-provisioner:v1.6.0-lh1
|
||||||
|
longhornio/csi-resizer:v0.5.1-lh1
|
||||||
|
longhornio/csi-snapshotter:v2.1.1-lh1
|
||||||
|
longhornio/csi-node-driver-registrar:v1.2.0-lh1
|
||||||
@ -1,7 +0,0 @@
|
|||||||
# Upgrade Responder Helm Chart
|
|
||||||
|
|
||||||
This directory contains the helm values for the Longhorn upgrade responder server.
|
|
||||||
The values are in the file `./chart-values.yaml`.
|
|
||||||
When you update the content of `./chart-values.yaml`, automation pipeline will update the Longhorn upgrade responder.
|
|
||||||
Information about the source chart is in `chart.yaml`.
|
|
||||||
See [dev/upgrade-responder](../../dev/upgrade-responder/README.md) for manual deployment steps.
|
|
||||||
@ -1,372 +0,0 @@
|
|||||||
# Specify the name of the application that is using this Upgrade Responder server
|
|
||||||
# This will be used to create a database named <application-name>_upgrade_responder
|
|
||||||
# in the InfluxDB to store all data for this Upgrade Responder
|
|
||||||
# The name must be in snake case format
|
|
||||||
applicationName: longhorn
|
|
||||||
|
|
||||||
image:
|
|
||||||
repository: longhornio/upgrade-responder
|
|
||||||
tag: longhorn-head
|
|
||||||
pullPolicy: Always
|
|
||||||
|
|
||||||
secret:
|
|
||||||
name: upgrade-responder-secret
|
|
||||||
# Set this to false if you don't want to manage these secrets with helm
|
|
||||||
managed: false
|
|
||||||
|
|
||||||
resources:
|
|
||||||
limits:
|
|
||||||
cpu: 400m
|
|
||||||
memory: 512Mi
|
|
||||||
requests:
|
|
||||||
cpu: 200m
|
|
||||||
memory: 256Mi
|
|
||||||
|
|
||||||
# This configmap contains information about the latest release
|
|
||||||
# of the application that is using this Upgrade Responder
|
|
||||||
configMap:
|
|
||||||
responseConfig: |-
|
|
||||||
{
|
|
||||||
"versions": [
|
|
||||||
{
|
|
||||||
"name": "v1.3.3",
|
|
||||||
"releaseDate": "2023-04-19T00:00:00Z",
|
|
||||||
"tags": [
|
|
||||||
"stable"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"name": "v1.4.3",
|
|
||||||
"releaseDate": "2023-07-14T00:00:00Z",
|
|
||||||
"tags": [
|
|
||||||
"latest",
|
|
||||||
"stable"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"name": "v1.5.1",
|
|
||||||
"releaseDate": "2023-07-19T00:00:00Z",
|
|
||||||
"tags": [
|
|
||||||
"latest"
|
|
||||||
]
|
|
||||||
}
|
|
||||||
]
|
|
||||||
}
|
|
||||||
requestSchema: |-
|
|
||||||
{
|
|
||||||
"appVersionSchema": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"extraTagInfoSchema": {
|
|
||||||
"hostKernelRelease": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"hostOsDistro": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"kubernetesNodeProvider": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"kubernetesVersion": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingAllowRecurringJobWhileVolumeDetached": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingAllowVolumeCreationWithDegradedAvailability": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingAutoCleanupSystemGeneratedSnapshot": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingAutoDeletePodWhenVolumeDetachedUnexpectedly": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingAutoSalvage": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingBackupCompressionMethod": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingBackupTarget": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingCrdApiVersion": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingCreateDefaultDiskLabeledNodes": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingDefaultDataLocality": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingDisableRevisionCounter": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingDisableSchedulingOnCordonedNode": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingFastReplicaRebuildEnabled": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingKubernetesClusterAutoscalerEnabled": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingNodeDownPodDeletionPolicy": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingNodeDrainPolicy": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingOfflineReplicaRebuilding": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingOrphanAutoDeletion": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingPriorityClass": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingRegistrySecret": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingRemoveSnapshotsDuringFilesystemTrim": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingReplicaAutoBalance": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingReplicaSoftAntiAffinity": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingReplicaZoneSoftAntiAffinity": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingReplicaDiskSoftAntiAffinity": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
}
|
|
||||||
"longhornSettingRestoreVolumeRecurringJobs": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingSnapshotDataIntegrity": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingSnapshotDataIntegrityCronjob": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingSnapshotDataIntegrityImmediateCheckAfterSnapshotCreation": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingStorageNetwork": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingSystemManagedComponentsNodeSelector": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingSystemManagedPodsImagePullPolicy": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingTaintToleration": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingV2DataEngine": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"extraFieldInfoSchema": {
|
|
||||||
"longhornInstanceManagerAverageCpuUsageMilliCores": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornInstanceManagerAverageMemoryUsageBytes": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornManagerAverageCpuUsageMilliCores": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornManagerAverageMemoryUsageBytes": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornNamespaceUid": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornNodeCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornNodeDiskHDDCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornNodeDiskNVMeCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornNodeDiskSSDCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingBackingImageCleanupWaitInterval": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingBackingImageRecoveryWaitInterval": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingBackupConcurrentLimit": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingBackupstorePollInterval": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingConcurrentAutomaticEngineUpgradePerNodeLimit": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingConcurrentReplicaRebuildPerNodeLimit": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingConcurrentVolumeBackupRestorePerNodeLimit": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingDefaultReplicaCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingEngineReplicaTimeout": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingFailedBackupTtl": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingGuaranteedInstanceManagerCpu": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingRecurringFailedJobsHistoryLimit": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingRecurringSuccessfulJobsHistoryLimit": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingReplicaFileSyncHttpClientTimeout": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingReplicaReplenishmentWaitInterval": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingRestoreConcurrentLimit": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingStorageMinimalAvailablePercentage": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingStorageOverProvisioningPercentage": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingStorageReservedPercentageForDefaultDisk": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingSupportBundleFailedHistoryLimit": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeAccessModeRwoCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeAccessModeRwxCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeAccessModeUnknownCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeAverageActualSizeBytes": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeAverageNumberOfReplicas": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeAverageSizeBytes": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeAverageSnapshotCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeDataLocalityBestEffortCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeDataLocalityDisabledCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeDataLocalityStrictLocalCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeFrontendBlockdevCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeFrontendIscsiCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeOfflineReplicaRebuildingDisabledCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeOfflineReplicaRebuildingEnabledCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeReplicaAutoBalanceDisabledCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeReplicaSoftAntiAffinityFalseCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeReplicaZoneSoftAntiAffinityTrueCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeReplicaDiskSoftAntiAffinityTrueCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeRestoreVolumeRecurringJobFalseCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeSnapshotDataIntegrityDisabledCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeSnapshotDataIntegrityFastCheckCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeUnmapMarkSnapChainRemovedFalseCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
@ -1,5 +0,0 @@
|
|||||||
url: https://github.com/longhorn/upgrade-responder.git
|
|
||||||
commit: 116f807836c29185038cfb005708f0a8d41f4d35
|
|
||||||
releaseName: longhorn-upgrade-responder
|
|
||||||
namespace: longhorn-upgrade-responder
|
|
||||||
|
|
||||||
@ -1,55 +0,0 @@
|
|||||||
## Overview
|
|
||||||
|
|
||||||
### Install
|
|
||||||
|
|
||||||
1. Install Longhorn.
|
|
||||||
1. Install Longhorn [upgrade-responder](https://github.com/longhorn/upgrade-responder) stack.
|
|
||||||
```bash
|
|
||||||
./install.sh
|
|
||||||
```
|
|
||||||
Sample output:
|
|
||||||
```shell
|
|
||||||
secret/influxdb-creds created
|
|
||||||
persistentvolumeclaim/influxdb created
|
|
||||||
deployment.apps/influxdb created
|
|
||||||
service/influxdb created
|
|
||||||
Deployment influxdb is running.
|
|
||||||
Cloning into 'upgrade-responder'...
|
|
||||||
remote: Enumerating objects: 1077, done.
|
|
||||||
remote: Counting objects: 100% (1076/1076), done.
|
|
||||||
remote: Compressing objects: 100% (454/454), done.
|
|
||||||
remote: Total 1077 (delta 573), reused 1049 (delta 565), pack-reused 1
|
|
||||||
Receiving objects: 100% (1077/1077), 55.01 MiB | 18.10 MiB/s, done.
|
|
||||||
Resolving deltas: 100% (573/573), done.
|
|
||||||
Release "longhorn-upgrade-responder" does not exist. Installing it now.
|
|
||||||
NAME: longhorn-upgrade-responder
|
|
||||||
LAST DEPLOYED: Thu May 11 00:42:44 2023
|
|
||||||
NAMESPACE: default
|
|
||||||
STATUS: deployed
|
|
||||||
REVISION: 1
|
|
||||||
TEST SUITE: None
|
|
||||||
NOTES:
|
|
||||||
1. Get the Upgrade Responder server URL by running these commands:
|
|
||||||
export POD_NAME=$(kubectl get pods --namespace default -l "app.kubernetes.io/name=upgrade-responder,app.kubernetes.io/instance=longhorn-upgrade-responder" -o jsonpath="{.items[0].metadata.name}")
|
|
||||||
kubectl port-forward $POD_NAME 8080:8314 --namespace default
|
|
||||||
echo "Upgrade Responder server URL is http://127.0.0.1:8080"
|
|
||||||
Deployment longhorn-upgrade-responder is running.
|
|
||||||
persistentvolumeclaim/grafana-pvc created
|
|
||||||
deployment.apps/grafana created
|
|
||||||
service/grafana created
|
|
||||||
Deployment grafana is running.
|
|
||||||
|
|
||||||
[Upgrade Checker]
|
|
||||||
URL : http://longhorn-upgrade-responder.default.svc.cluster.local:8314/v1/checkupgrade
|
|
||||||
|
|
||||||
[InfluxDB]
|
|
||||||
URL : http://influxdb.default.svc.cluster.local:8086
|
|
||||||
Database : longhorn_upgrade_responder
|
|
||||||
Username : root
|
|
||||||
Password : root
|
|
||||||
|
|
||||||
[Grafana]
|
|
||||||
Dashboard : http://1.2.3.4:30864
|
|
||||||
Username : admin
|
|
||||||
Password : admin
|
|
||||||
```
|
|
||||||
@ -1,424 +0,0 @@
|
|||||||
#!/bin/bash
|
|
||||||
|
|
||||||
UPGRADE_RESPONDER_REPO="https://github.com/longhorn/upgrade-responder.git"
|
|
||||||
UPGRADE_RESPONDER_REPO_BRANCH="master"
|
|
||||||
UPGRADE_RESPONDER_VALUE_YAML="upgrade-responder-value.yaml"
|
|
||||||
UPGRADE_RESPONDER_IMAGE_REPO="longhornio/upgrade-responder"
|
|
||||||
UPGRADE_RESPONDER_IMAGE_TAG="master-head"
|
|
||||||
|
|
||||||
INFLUXDB_URL="http://influxdb.default.svc.cluster.local:8086"
|
|
||||||
|
|
||||||
APP_NAME="longhorn"
|
|
||||||
|
|
||||||
DEPLOYMENT_TIMEOUT_SEC=300
|
|
||||||
DEPLOYMENT_WAIT_INTERVAL_SEC=5
|
|
||||||
|
|
||||||
temp_dir=$(mktemp -d)
|
|
||||||
trap 'rm -rf "${temp_dir}"' EXIT # -f because packed Git files (.pack, .idx) are write protected.
|
|
||||||
|
|
||||||
cp -a ./* ${temp_dir}
|
|
||||||
cd ${temp_dir}
|
|
||||||
|
|
||||||
wait_for_deployment() {
|
|
||||||
local deployment_name="$1"
|
|
||||||
local start_time=$(date +%s)
|
|
||||||
|
|
||||||
while true; do
|
|
||||||
status=$(kubectl rollout status deployment/${deployment_name})
|
|
||||||
if [[ ${status} == *"successfully rolled out"* ]]; then
|
|
||||||
echo "Deployment ${deployment_name} is running."
|
|
||||||
break
|
|
||||||
fi
|
|
||||||
|
|
||||||
elapsed_secs=$(($(date +%s) - ${start_time}))
|
|
||||||
if [[ ${elapsed_secs} -ge ${timeout_secs} ]]; then
|
|
||||||
echo "Timed out waiting for deployment ${deployment_name} to be running."
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo "Deployment ${deployment_name} is not running yet. Waiting..."
|
|
||||||
sleep ${DEPLOYMENT_WAIT_INTERVAL_SEC}
|
|
||||||
done
|
|
||||||
}
|
|
||||||
|
|
||||||
install_influxdb() {
|
|
||||||
kubectl apply -f ./manifests/influxdb.yaml
|
|
||||||
wait_for_deployment "influxdb"
|
|
||||||
}
|
|
||||||
|
|
||||||
install_grafana() {
|
|
||||||
kubectl apply -f ./manifests/grafana.yaml
|
|
||||||
wait_for_deployment "grafana"
|
|
||||||
}
|
|
||||||
|
|
||||||
install_upgrade_responder() {
|
|
||||||
cat << EOF > ${UPGRADE_RESPONDER_VALUE_YAML}
|
|
||||||
applicationName: ${APP_NAME}
|
|
||||||
secret:
|
|
||||||
name: upgrade-responder-secrets
|
|
||||||
managed: true
|
|
||||||
influxDBUrl: "${INFLUXDB_URL}"
|
|
||||||
influxDBUser: "root"
|
|
||||||
influxDBPassword: "root"
|
|
||||||
configMap:
|
|
||||||
responseConfig: |-
|
|
||||||
{
|
|
||||||
"versions": [{
|
|
||||||
"name": "v1.0.0",
|
|
||||||
"releaseDate": "2020-05-18T12:30:00Z",
|
|
||||||
"tags": ["latest"]
|
|
||||||
}]
|
|
||||||
}
|
|
||||||
requestSchema: |-
|
|
||||||
{
|
|
||||||
"appVersionSchema": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"extraTagInfoSchema": {
|
|
||||||
"hostKernelRelease": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"hostOsDistro": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"kubernetesNodeProvider": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"kubernetesVersion": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingAllowRecurringJobWhileVolumeDetached": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingAllowVolumeCreationWithDegradedAvailability": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingAutoCleanupSystemGeneratedSnapshot": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingAutoDeletePodWhenVolumeDetachedUnexpectedly": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingAutoSalvage": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingBackupCompressionMethod": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingBackupTarget": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingCrdApiVersion": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingCreateDefaultDiskLabeledNodes": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingDefaultDataLocality": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingDisableRevisionCounter": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingDisableSchedulingOnCordonedNode": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingFastReplicaRebuildEnabled": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingKubernetesClusterAutoscalerEnabled": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingNodeDownPodDeletionPolicy": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingNodeDrainPolicy": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingOfflineReplicaRebuilding": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingOrphanAutoDeletion": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingPriorityClass": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingRegistrySecret": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingRemoveSnapshotsDuringFilesystemTrim": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingReplicaAutoBalance": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingReplicaSoftAntiAffinity": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingReplicaZoneSoftAntiAffinity": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingReplicaDiskSoftAntiAffinity": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingRestoreVolumeRecurringJobs": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingSnapshotDataIntegrity": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingSnapshotDataIntegrityCronjob": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingSnapshotDataIntegrityImmediateCheckAfterSnapshotCreation": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingStorageNetwork": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingSystemManagedComponentsNodeSelector": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingSystemManagedPodsImagePullPolicy": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingTaintToleration": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornSettingV2DataEngine": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"extraFieldInfoSchema": {
|
|
||||||
"longhornInstanceManagerAverageCpuUsageMilliCores": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornInstanceManagerAverageMemoryUsageBytes": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornManagerAverageCpuUsageMilliCores": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornManagerAverageMemoryUsageBytes": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornNamespaceUid": {
|
|
||||||
"dataType": "string",
|
|
||||||
"maxLen": 200
|
|
||||||
},
|
|
||||||
"longhornNodeCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornNodeDiskHDDCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornNodeDiskNVMeCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornNodeDiskSSDCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingBackingImageCleanupWaitInterval": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingBackingImageRecoveryWaitInterval": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingBackupConcurrentLimit": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingBackupstorePollInterval": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingConcurrentAutomaticEngineUpgradePerNodeLimit": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingConcurrentReplicaRebuildPerNodeLimit": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingConcurrentVolumeBackupRestorePerNodeLimit": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingDefaultReplicaCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingEngineReplicaTimeout": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingFailedBackupTtl": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingGuaranteedInstanceManagerCpu": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingRecurringFailedJobsHistoryLimit": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingRecurringSuccessfulJobsHistoryLimit": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingReplicaFileSyncHttpClientTimeout": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingReplicaReplenishmentWaitInterval": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingRestoreConcurrentLimit": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingStorageMinimalAvailablePercentage": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingStorageOverProvisioningPercentage": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingStorageReservedPercentageForDefaultDisk": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornSettingSupportBundleFailedHistoryLimit": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeAccessModeRwoCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeAccessModeRwxCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeAccessModeUnknownCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeAverageActualSizeBytes": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeAverageNumberOfReplicas": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeAverageSizeBytes": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeAverageSnapshotCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeDataLocalityBestEffortCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeDataLocalityDisabledCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeDataLocalityStrictLocalCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeFrontendBlockdevCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeFrontendIscsiCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeOfflineReplicaRebuildingDisabledCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeOfflineReplicaRebuildingEnabledCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeReplicaAutoBalanceDisabledCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeReplicaSoftAntiAffinityFalseCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeReplicaZoneSoftAntiAffinityTrueCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeReplicaDiskSoftAntiAffinityTrueCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeRestoreVolumeRecurringJobFalseCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeSnapshotDataIntegrityDisabledCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeSnapshotDataIntegrityFastCheckCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
},
|
|
||||||
"longhornVolumeUnmapMarkSnapChainRemovedFalseCount": {
|
|
||||||
"dataType": "float"
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
image:
|
|
||||||
repository: ${UPGRADE_RESPONDER_IMAGE_REPO}
|
|
||||||
tag: ${UPGRADE_RESPONDER_IMAGE_TAG}
|
|
||||||
EOF
|
|
||||||
|
|
||||||
git clone -b ${UPGRADE_RESPONDER_REPO_BRANCH} ${UPGRADE_RESPONDER_REPO}
|
|
||||||
helm upgrade --install ${APP_NAME}-upgrade-responder upgrade-responder/chart -f ${UPGRADE_RESPONDER_VALUE_YAML}
|
|
||||||
wait_for_deployment "${APP_NAME}-upgrade-responder"
|
|
||||||
}
|
|
||||||
|
|
||||||
output() {
|
|
||||||
local upgrade_responder_service_info=$(kubectl get svc/${APP_NAME}-upgrade-responder --no-headers)
|
|
||||||
local upgrade_responder_service_port=$(echo "${upgrade_responder_service_info}" | awk '{print $5}' | cut -d'/' -f1)
|
|
||||||
echo # a blank line to separate the installation outputs for better readability.
|
|
||||||
printf "[Upgrade Checker]\n"
|
|
||||||
printf "%-10s: http://${APP_NAME}-upgrade-responder.default.svc.cluster.local:${upgrade_responder_service_port}/v1/checkupgrade\n\n" "URL"
|
|
||||||
|
|
||||||
printf "[InfluxDB]\n"
|
|
||||||
printf "%-10s: ${INFLUXDB_URL}\n" "URL"
|
|
||||||
printf "%-10s: ${APP_NAME}_upgrade_responder\n" "Database"
|
|
||||||
printf "%-10s: root\n" "Username"
|
|
||||||
printf "%-10s: root\n\n" "Password"
|
|
||||||
|
|
||||||
local public_ip=$(curl -s https://ifconfig.me/ip)
|
|
||||||
local grafana_service_info=$(kubectl get svc/grafana --no-headers)
|
|
||||||
local grafana_service_port=$(echo "${grafana_service_info}" | awk '{print $5}' | cut -d':' -f2 | cut -d'/' -f1)
|
|
||||||
printf "[Grafana]\n"
|
|
||||||
printf "%-10s: http://${public_ip}:${grafana_service_port}\n" "Dashboard"
|
|
||||||
printf "%-10s: admin\n" "Username"
|
|
||||||
printf "%-10s: admin\n" "Password"
|
|
||||||
}
|
|
||||||
|
|
||||||
install_influxdb
|
|
||||||
install_upgrade_responder
|
|
||||||
install_grafana
|
|
||||||
output
|
|
||||||
@ -1,86 +0,0 @@
|
|||||||
---
|
|
||||||
apiVersion: v1
|
|
||||||
kind: PersistentVolumeClaim
|
|
||||||
metadata:
|
|
||||||
name: grafana-pvc
|
|
||||||
spec:
|
|
||||||
accessModes:
|
|
||||||
- ReadWriteOnce
|
|
||||||
storageClassName: longhorn
|
|
||||||
resources:
|
|
||||||
requests:
|
|
||||||
storage: 2Gi
|
|
||||||
---
|
|
||||||
apiVersion: apps/v1
|
|
||||||
kind: Deployment
|
|
||||||
metadata:
|
|
||||||
labels:
|
|
||||||
app: grafana
|
|
||||||
name: grafana
|
|
||||||
spec:
|
|
||||||
selector:
|
|
||||||
matchLabels:
|
|
||||||
app: grafana
|
|
||||||
template:
|
|
||||||
metadata:
|
|
||||||
labels:
|
|
||||||
app: grafana
|
|
||||||
spec:
|
|
||||||
securityContext:
|
|
||||||
fsGroup: 472
|
|
||||||
supplementalGroups:
|
|
||||||
- 0
|
|
||||||
containers:
|
|
||||||
- name: grafana
|
|
||||||
image: grafana/grafana:7.1.0
|
|
||||||
imagePullPolicy: IfNotPresent
|
|
||||||
env:
|
|
||||||
- name: GF_INSTALL_PLUGINS
|
|
||||||
value: "grafana-worldmap-panel"
|
|
||||||
ports:
|
|
||||||
- containerPort: 3000
|
|
||||||
name: http-grafana
|
|
||||||
protocol: TCP
|
|
||||||
readinessProbe:
|
|
||||||
failureThreshold: 3
|
|
||||||
httpGet:
|
|
||||||
path: /robots.txt
|
|
||||||
port: 3000
|
|
||||||
scheme: HTTP
|
|
||||||
initialDelaySeconds: 10
|
|
||||||
periodSeconds: 30
|
|
||||||
successThreshold: 1
|
|
||||||
timeoutSeconds: 2
|
|
||||||
livenessProbe:
|
|
||||||
failureThreshold: 3
|
|
||||||
initialDelaySeconds: 30
|
|
||||||
periodSeconds: 10
|
|
||||||
successThreshold: 1
|
|
||||||
tcpSocket:
|
|
||||||
port: 3000
|
|
||||||
timeoutSeconds: 1
|
|
||||||
resources:
|
|
||||||
requests:
|
|
||||||
cpu: 250m
|
|
||||||
memory: 750Mi
|
|
||||||
volumeMounts:
|
|
||||||
- mountPath: /var/lib/grafana
|
|
||||||
name: grafana-pv
|
|
||||||
volumes:
|
|
||||||
- name: grafana-pv
|
|
||||||
persistentVolumeClaim:
|
|
||||||
claimName: grafana-pvc
|
|
||||||
---
|
|
||||||
apiVersion: v1
|
|
||||||
kind: Service
|
|
||||||
metadata:
|
|
||||||
name: grafana
|
|
||||||
spec:
|
|
||||||
ports:
|
|
||||||
- port: 3000
|
|
||||||
protocol: TCP
|
|
||||||
targetPort: http-grafana
|
|
||||||
selector:
|
|
||||||
app: grafana
|
|
||||||
sessionAffinity: None
|
|
||||||
type: LoadBalancer
|
|
||||||
@ -1,90 +0,0 @@
|
|||||||
apiVersion: v1
|
|
||||||
kind: Secret
|
|
||||||
metadata:
|
|
||||||
name: influxdb-creds
|
|
||||||
namespace: default
|
|
||||||
type: Opaque
|
|
||||||
data:
|
|
||||||
INFLUXDB_HOST: aW5mbHV4ZGI= # influxdb
|
|
||||||
INFLUXDB_PASSWORD: cm9vdA== # root
|
|
||||||
INFLUXDB_USERNAME: cm9vdA== # root
|
|
||||||
---
|
|
||||||
apiVersion: v1
|
|
||||||
kind: PersistentVolumeClaim
|
|
||||||
metadata:
|
|
||||||
name: influxdb
|
|
||||||
namespace: default
|
|
||||||
labels:
|
|
||||||
app: influxdb
|
|
||||||
spec:
|
|
||||||
accessModes:
|
|
||||||
- ReadWriteOnce
|
|
||||||
storageClassName: longhorn
|
|
||||||
resources:
|
|
||||||
requests:
|
|
||||||
storage: 2Gi
|
|
||||||
---
|
|
||||||
apiVersion: apps/v1
|
|
||||||
kind: Deployment
|
|
||||||
metadata:
|
|
||||||
labels:
|
|
||||||
app: influxdb
|
|
||||||
name: influxdb
|
|
||||||
namespace: default
|
|
||||||
spec:
|
|
||||||
progressDeadlineSeconds: 600
|
|
||||||
replicas: 1
|
|
||||||
revisionHistoryLimit: 10
|
|
||||||
selector:
|
|
||||||
matchLabels:
|
|
||||||
app: influxdb
|
|
||||||
strategy:
|
|
||||||
rollingUpdate:
|
|
||||||
maxSurge: 25%
|
|
||||||
maxUnavailable: 25%
|
|
||||||
type: RollingUpdate
|
|
||||||
template:
|
|
||||||
metadata:
|
|
||||||
creationTimestamp: null
|
|
||||||
labels:
|
|
||||||
app: influxdb
|
|
||||||
spec:
|
|
||||||
containers:
|
|
||||||
- image: docker.io/influxdb:1.8.10
|
|
||||||
imagePullPolicy: IfNotPresent
|
|
||||||
name: influxdb
|
|
||||||
resources: {}
|
|
||||||
terminationMessagePath: /dev/termination-log
|
|
||||||
terminationMessagePolicy: File
|
|
||||||
envFrom:
|
|
||||||
- secretRef:
|
|
||||||
name: influxdb-creds
|
|
||||||
volumeMounts:
|
|
||||||
- mountPath: /var/lib/influxdb
|
|
||||||
name: var-lib-influxdb
|
|
||||||
volumes:
|
|
||||||
- name: var-lib-influxdb
|
|
||||||
persistentVolumeClaim:
|
|
||||||
claimName: influxdb
|
|
||||||
dnsPolicy: ClusterFirst
|
|
||||||
restartPolicy: Always
|
|
||||||
schedulerName: default-scheduler
|
|
||||||
securityContext: {}
|
|
||||||
terminationGracePeriodSeconds: 30
|
|
||||||
---
|
|
||||||
apiVersion: v1
|
|
||||||
kind: Service
|
|
||||||
metadata:
|
|
||||||
labels:
|
|
||||||
app: influxdb
|
|
||||||
name: influxdb
|
|
||||||
namespace: default
|
|
||||||
spec:
|
|
||||||
ports:
|
|
||||||
- port: 8086
|
|
||||||
protocol: TCP
|
|
||||||
targetPort: 8086
|
|
||||||
selector:
|
|
||||||
app: influxdb
|
|
||||||
sessionAffinity: None
|
|
||||||
type: ClusterIP
|
|
||||||
@ -15,7 +15,7 @@ https://github.com/longhorn/longhorn/issues/972
|
|||||||
1. Previously Longhorn is using filesystem ID as keys to the map of disks on the node. But we found there is no guarantee that filesystem ID won't change after the node reboots for certain filesystems e.g. XFS.
|
1. Previously Longhorn is using filesystem ID as keys to the map of disks on the node. But we found there is no guarantee that filesystem ID won't change after the node reboots for certain filesystems e.g. XFS.
|
||||||
1. We want to enable the ability to configure CRD directly, prepare for the CRD based API access in the future
|
1. We want to enable the ability to configure CRD directly, prepare for the CRD based API access in the future
|
||||||
1. We also need to make sure previously implemented safe guards are not impacted by this change:
|
1. We also need to make sure previously implemented safe guards are not impacted by this change:
|
||||||
1. If a disk was accidentally unmounted on the node, we should detect that and stop replica from scheduling into it.
|
1. If a disk was accidentally umounted on the node, we should detect that and stop replica from scheduling into it.
|
||||||
1. We shouldn't allow user to add two disks pointed to the same filesystem
|
1. We shouldn't allow user to add two disks pointed to the same filesystem
|
||||||
|
|
||||||
### Non-goals
|
### Non-goals
|
||||||
|
|||||||
@ -75,4 +75,4 @@ No special upgrade strategy is necessary. Once the user upgrades to the new vers
|
|||||||
|
|
||||||
### Notes
|
### Notes
|
||||||
- There is interest in allowing the user to decide on whether or not to retain the `Persistent Volume` (and possibly `Persistent Volume Claim`) for certain use cases such as restoring from a `Backup`. However, this would require changes to the way `go-rancher` generates the `Go` client that we use so that `Delete` requests against resources are able to take inputs.
|
- There is interest in allowing the user to decide on whether or not to retain the `Persistent Volume` (and possibly `Persistent Volume Claim`) for certain use cases such as restoring from a `Backup`. However, this would require changes to the way `go-rancher` generates the `Go` client that we use so that `Delete` requests against resources are able to take inputs.
|
||||||
- In the case that a `Volume` is provisioned from a `Storage Class` (and set to be `Deleted` once the `Persistent Volume Claim` utilizing that `Volume` has been deleted), the `Volume` should still be deleted properly regardless of how the deletion was initiated. If the `Volume` is deleted from the UI, the call that the `Volume Controller` makes to delete the `Persistent Volume` would only trigger one more deletion call from the `CSI` server to delete the `Volume`, which would return successfully and allow the `Persistent Volume` to be deleted and the `Volume` to be deleted as well. If the `Volume` is deleted because of the `Persistent Volume Claim`, the `CSI` server would be able to successfully make a `Volume` deletion call before deleting the `Persistent Volume`. The `Volume Controller` would have no additional resources to delete and be able to finish deletion of the `Volume`.
|
- In the case that a `Volume` is provisioned from a `Storage Class` (and set to be `Deleted` once the `Persistent Volume Claim` utilizing that `Volume` has been deleted), the `Volume` should still be deleted properly regardless of how the deletion was initiated. If the `Volume` is deleted from the UI, the call that the `Volume Controller` makes to delete the `Persistent Volume` would only trigger one more deletion call from the `CSI` server to delete the `Volume`, which would return successfully and allow the `Persistent Volume` to be deleted and the `Volume` to be deleted as wekk. If the `Volume` is deleted because of the `Persistent Volume Claim`, the `CSI` server would be able to successfully make a `Volume` deletion call before deleting the `Persistent Volume`. The `Volume Controller` would have no additional resources to delete and be able to finish deletion of the `Volume`.
|
||||||
|
|||||||
@ -16,7 +16,7 @@ https://github.com/longhorn/longhorn/issues/298
|
|||||||
|
|
||||||
## Proposal
|
## Proposal
|
||||||
1. Add `Eviction Requested` with `true` and `false` selection buttons for disks and nodes. This is for user to evict or cancel the eviction of the disks or the nodes.
|
1. Add `Eviction Requested` with `true` and `false` selection buttons for disks and nodes. This is for user to evict or cancel the eviction of the disks or the nodes.
|
||||||
2. Add new `evictionRequested` field to `Node.Spec`, `Node.Spec.disks` Spec and `Replica.Status`. These will help tracking the request from user and trigger replica controller to update `Replica.Status` and volume controller to do the eviction. And this will reconcile with `scheduledReplica` of selected disks on the nodes.
|
2. Add new `evictionRequested` field to `Node.Spec`, `Node.Spec.disks` Spec and `Replica.Status`. These will help tracking the request from user and trigger replica controller to update `Replica.Status` and volume controler to do the eviction. And this will reconcile with `scheduledReplica` of selected disks on the nodes.
|
||||||
3. Display `fail to evict` error message to `Dashboard` and any other eviction errors to the `Event log`.
|
3. Display `fail to evict` error message to `Dashboard` and any other eviction errors to the `Event log`.
|
||||||
|
|
||||||
### User Stories
|
### User Stories
|
||||||
@ -34,7 +34,7 @@ After this enhancement, user can click `true` to the `Eviction Requested` on sch
|
|||||||
#### Disks and Nodes Eviction
|
#### Disks and Nodes Eviction
|
||||||
1. User can select `true` to the `Eviction Requested` from `Longhorn UI` for disks or nodes. And user has to make sure the selected disks or nodes have been disabled, or select the `Disable` Scheduling at the same time of `true` to the `Eviction Requested`.
|
1. User can select `true` to the `Eviction Requested` from `Longhorn UI` for disks or nodes. And user has to make sure the selected disks or nodes have been disabled, or select the `Disable` Scheduling at the same time of `true` to the `Eviction Requested`.
|
||||||
2. Once `Eviction Requested` has been set to `true` on the disks or nodes, they can not be enabled for `Scheduling`.
|
2. Once `Eviction Requested` has been set to `true` on the disks or nodes, they can not be enabled for `Scheduling`.
|
||||||
3. If the disks or the nodes haven't been disabled for `Scheduling`, there will be error message showed in `Dashboard` immediately to indicate that user need to disable the disk or node for eviction.
|
3. If the disks or the nodes haven't been disabled for `Scheduling`, there will be error message showed in `Dashboard` immediatly to indicate that user need to disable the disk or node for eviction.
|
||||||
4. And user will wait for the replica number for the disks or nodes to be 0.
|
4. And user will wait for the replica number for the disks or nodes to be 0.
|
||||||
5. If there is any error e.g. no space or couldn't find other schedulable disk, the error message will be logged in the `Event log`. And the eviction will be suspended until either user sets the `Eviction Requested` to `false` or cleanup more disk spaces for the new replicas.
|
5. If there is any error e.g. no space or couldn't find other schedulable disk, the error message will be logged in the `Event log`. And the eviction will be suspended until either user sets the `Eviction Requested` to `false` or cleanup more disk spaces for the new replicas.
|
||||||
6. If user cancel the eviction by setting the `Eviction Requested` to `false`, the remaining replicas on the selected disks or nodes will remain on the disks or nodes.
|
6. If user cancel the eviction by setting the `Eviction Requested` to `false`, the remaining replicas on the selected disks or nodes will remain on the disks or nodes.
|
||||||
@ -47,7 +47,7 @@ From an API perspective, the call to set `Eviction Requested` to `true` or `fals
|
|||||||
### Implementation Overview
|
### Implementation Overview
|
||||||
|
|
||||||
1. On `Longhorn UI` `Node` page, for nodes eviction, adding `Eviction Requested` `true` and `false` options in the `Edit Node` sub-selection, next to `Node Scheduling`. For disks eviction, adding `Eviction Requested` `true` and `false` options in `Edit node and disks` sub-selection under `Operation` column next to each disk `Scheduling` options. This is for user to evict or cancel the eviction of the disks or the nodes.
|
1. On `Longhorn UI` `Node` page, for nodes eviction, adding `Eviction Requested` `true` and `false` options in the `Edit Node` sub-selection, next to `Node Scheduling`. For disks eviction, adding `Eviction Requested` `true` and `false` options in `Edit node and disks` sub-selection under `Operation` column next to each disk `Scheduling` options. This is for user to evict or cancel the eviction of the disks or the nodes.
|
||||||
2. Add new `evictionRequested` field to `Node.Spec`, `Node.Spec.disks` Spec and `Replica.Status`. These will help tracking the request from user and trigger replica controller to update `Replica.Status` and volume controller to do the eviction. And this will reconcile with `scheduledReplica` of selected disks on the nodes.
|
2. Add new `evictionRequested` field to `Node.Spec`, `Node.Spec.disks` Spec and `Replica.Status`. These will help tracking the request from user and trigger replica controller to update `Replica.Status` and volume controler to do the eviction. And this will reconcile with `scheduledReplica` of selected disks on the nodes.
|
||||||
3. Add a informer in `Replica Controller` to get these information and update `evictionRequested` field in `Replica.Status`.
|
3. Add a informer in `Replica Controller` to get these information and update `evictionRequested` field in `Replica.Status`.
|
||||||
4. Once `Eviction Requested` has been set to `true` for disks or nodes, the `evictionRequested` fields for the disks and nodes will be set to `true` (default is `false`).
|
4. Once `Eviction Requested` has been set to `true` for disks or nodes, the `evictionRequested` fields for the disks and nodes will be set to `true` (default is `false`).
|
||||||
5. `Replica Controller` will update `evictionRequested` field in `Replica.Status` and `Volume Controller` to get these information from it's replicas.
|
5. `Replica Controller` will update `evictionRequested` field in `Replica.Status` and `Volume Controller` to get these information from it's replicas.
|
||||||
@ -61,11 +61,11 @@ From an API perspective, the call to set `Eviction Requested` to `true` or `fals
|
|||||||
#### Manual Test Plan For Disks and Nodes Eviction
|
#### Manual Test Plan For Disks and Nodes Eviction
|
||||||
Positive Case:
|
Positive Case:
|
||||||
|
|
||||||
For both `Replica Node Level Soft Anti-Affinity` has been enabled and disabled. Also the volume can be 'Attached' or 'Detached'.
|
For both `Replica Node Level Soft Anti-Affinity` has been enabled and disabled. Also the volume can be 'Attaced' or 'Detached'.
|
||||||
1. User can select one or more disks or nodes for eviction. Select `Eviction Requested` to `true` on the disabled disks or nodes, Longhorn should start rebuild replicas for the volumes which have replicas on the eviction disks or nodes, and after rebuild success, the replica number on the evicted disks or nodes should be 0. E.g. When there are 3 nodes in the cluster, and with `Replica Node Level Soft Anti-Affinity` is set to `false`, disable one node, and create a volume with replica count 2. And then evict one of them, the eviction should get stuck, then set `Replica Node Level Soft Anti-Affinity` to `true`, the eviction should go through.
|
1. User can select one or more disks or nodes for eviction. Select `Eviction Requested` to `true` on the disabled disks or nodes, Longhorn should start rebuild replicas for the volumes which have replicas on the eviction disks or nodes, and after rebuild success, the replica number on the evicted disks or nodes should be 0. E.g. When there are 3 nodes in the cluster, and with `Replica Node Level Soft Anti-Affinity` is set to `false`, disable one node, and create a volume with replica count 2. And then evict one of them, the eviction should get stuck, then set `Replica Node Level Soft Anti-Affinity` to `true`, the eviction should go through.
|
||||||
|
|
||||||
Negative Cases:
|
Negative Cases:
|
||||||
1. If user selects the disks or nodes have not been disabled scheduling, Longhorn should display the error message on `Dashboard` immediately. Or during the eviction, the disabled disk or node can not be re-enabled again.
|
1. If user selects the disks or nodes have not been disabled scheduling, Longhorn should display the error message on `Dashboard` immediatly. Or during the eviction, the disabled disk or node can not be re-enabled again.
|
||||||
2. If there is no enough disk spaces or nodes for disks or nodes eviction, Longhorn should log the error message in the `Event Log`. And once the disk spaces or nodes resources are good enough, the eviction should continue. Or if the user selects `Eviction Requested` to `false`, Longhorn should stop eviction and clear the `evictionRequested` fields for nodes, disks and volumes crd objects. E.g. When there are 3 nodes in the cluster, and the volume replica count is 3, the eviction should get stuck when the `Replica Node Level Soft Anti-Affinity` is `false`.
|
2. If there is no enough disk spaces or nodes for disks or nodes eviction, Longhorn should log the error message in the `Event Log`. And once the disk spaces or nodes resources are good enough, the eviction should continue. Or if the user selects `Eviction Requested` to `false`, Longhorn should stop eviction and clear the `evictionRequested` fields for nodes, disks and volumes crd objects. E.g. When there are 3 nodes in the cluster, and the volume replica count is 3, the eviction should get stuck when the `Replica Node Level Soft Anti-Affinity` is `false`.
|
||||||
|
|
||||||
#### Integration Test Plan
|
#### Integration Test Plan
|
||||||
@ -73,10 +73,10 @@ For `Replica Node Level Soft Anti-Affinity` is enabled, create 2 replicas on the
|
|||||||
|
|
||||||
For `Replica Node Level Soft Anti-Affinity` is disabled, create 1 replica on a disk, and evict this disk or node, the replica should goto the other disk of node.
|
For `Replica Node Level Soft Anti-Affinity` is disabled, create 1 replica on a disk, and evict this disk or node, the replica should goto the other disk of node.
|
||||||
|
|
||||||
For node eviction, Longhorn will process the eviction based on the disks for the node, this is like disk eviction. After eviction success, the replica number on the evicted node should be 0.
|
For node eviction, Longhorn will process the evition based on the disks for the node, this is like disk eviction. After eviction success, the replica number on the evicted node should be 0.
|
||||||
|
|
||||||
#### Error Indication
|
#### Error Indication
|
||||||
During the eviction, user can click the `Replicas Number` on the `Node` page, and set which replicas are left from eviction, and click the `Replica Name` will redirect user to the `Volume` page to set if there is any error for this volume. If there is any error during the rebuild, Longhorn should display the error message from UI. The error could be `failed to schedule a replica` due to disk space or based on schedule policy, can not find a valid disk to put the replica.
|
During the eviction, user can click the `Replicas Number` on the `Node` page, and set which replicas are left from eviction, and click the `Replica Name` will redirect user to the `Volume` page to set if there is any error for this volume. If there is any error during the rebuild, Longhorn should display the error message from UI. The error could be `failed to schedule a replica` due to disk space or based on schedule policy, can not find a valid disk to put the relica.
|
||||||
|
|
||||||
### Upgrade strategy
|
### Upgrade strategy
|
||||||
No special upgrade strategy is necessary. Once the user upgrades to the new version of `Longhorn`, these new capabilities will be accessible from the `longhorn-ui` without any special work.
|
No special upgrade strategy is necessary. Once the user upgrades to the new version of `Longhorn`, these new capabilities will be accessible from the `longhorn-ui` without any special work.
|
||||||
|
|||||||
@ -61,12 +61,12 @@ Same as the Design
|
|||||||
### Test plan
|
### Test plan
|
||||||
1. Setup a cluster of 3 nodes
|
1. Setup a cluster of 3 nodes
|
||||||
1. Install Longhorn and set `Default Replica Count = 2` (because we will turn off one node)
|
1. Install Longhorn and set `Default Replica Count = 2` (because we will turn off one node)
|
||||||
1. Create a StatefulSet with 2 pods using the command:
|
1. Create a SetfullSet with 2 pods using the command:
|
||||||
```
|
```
|
||||||
kubectl create -f https://raw.githubusercontent.com/longhorn/longhorn/master/examples/statefulset.yaml
|
kubectl create -f https://raw.githubusercontent.com/longhorn/longhorn/master/examples/statefulset.yaml
|
||||||
```
|
```
|
||||||
1. Create a volume + pv + pvc named `vol1` and create a deployment of default ubuntu named `shell` with the usage of pvc `vol1` mounted under `/mnt/vol1`
|
1. Create a volume + pv + pvc named `vol1` and create a deployment of default ubuntu named `shell` with the usage of pvc `vol1` mounted under `/mnt/vol1`
|
||||||
1. Find the node which contains one pod of the StatefulSet/Deployment. Power off the node
|
1. Find the node which contains one pod of the StatefullSet/Deployment. Power off the node
|
||||||
|
|
||||||
#### StatefulSet
|
#### StatefulSet
|
||||||
##### if `NodeDownPodDeletionPolicy ` is set to `do-nothing ` | `delete-deployment-pod`
|
##### if `NodeDownPodDeletionPolicy ` is set to `do-nothing ` | `delete-deployment-pod`
|
||||||
|
|||||||
@ -119,7 +119,7 @@ UI modification:
|
|||||||
* On the right volume info panel, add a <div> to display `selectedVolume.dataLocality`
|
* On the right volume info panel, add a <div> to display `selectedVolume.dataLocality`
|
||||||
* On the right volume panel, in the Health row, add an icon for data locality status.
|
* On the right volume panel, in the Health row, add an icon for data locality status.
|
||||||
Specifically, if `dataLocality=best-effort` but there is not a local replica then display a warning icon.
|
Specifically, if `dataLocality=best-effort` but there is not a local replica then display a warning icon.
|
||||||
Similar to the replica node redundancy warning [here](https://github.com/longhorn/longhorn-ui/blob/0a52c1f0bef172d8ececdf4e1e953bfe78c86f29/src/routes/volume/detail/VolumeInfo.js#L47)
|
Similar to the replica node redundancy wanring [here](https://github.com/longhorn/longhorn-ui/blob/0a52c1f0bef172d8ececdf4e1e953bfe78c86f29/src/routes/volume/detail/VolumeInfo.js#L47)
|
||||||
* In the volume's actions dropdown, add a new action to update `dataLocality`
|
* In the volume's actions dropdown, add a new action to update `dataLocality`
|
||||||
1. In Rancher UI, add a parameter `dataLocality` when create storage class using Longhorn provisioner.
|
1. In Rancher UI, add a parameter `dataLocality` when create storage class using Longhorn provisioner.
|
||||||
|
|
||||||
|
|||||||
@ -15,7 +15,7 @@ https://github.com/longhorn/longhorn/issues/508
|
|||||||
1. By default 'DisableRevisionCounter' is 'false', but Longhorn provides an optional for user to disable it.
|
1. By default 'DisableRevisionCounter' is 'false', but Longhorn provides an optional for user to disable it.
|
||||||
2. Once user set 'DisableRevisionCounter' to 'true' globally or individually, this will improve Longhorn data path performance.
|
2. Once user set 'DisableRevisionCounter' to 'true' globally or individually, this will improve Longhorn data path performance.
|
||||||
3. And for 'DisableRevisionCounter' is 'true', Longhorn will keep the ability to find the most suitable replica to recover the volume when the engine is faulted(all the replicas are in 'ERR' state).
|
3. And for 'DisableRevisionCounter' is 'true', Longhorn will keep the ability to find the most suitable replica to recover the volume when the engine is faulted(all the replicas are in 'ERR' state).
|
||||||
4. Also during Longhorn Engine starting, with head file information it's unlikely to find out out of synced replicas. So will skip the check.
|
4. Also during Longhorn Engine starting, with head file information it's unlikly to find out out of synced replicas. So will skip the check.
|
||||||
|
|
||||||
## Proposal
|
## Proposal
|
||||||
|
|
||||||
@ -41,7 +41,7 @@ Or from StorageClass yaml file, user can set 'parameters' 'revisionCounterDisabl
|
|||||||
|
|
||||||
User can also set 'DisableRevisionCounter' for each individual volumes created by Longhorn UI this individual setting will over write the global setting.
|
User can also set 'DisableRevisionCounter' for each individual volumes created by Longhorn UI this individual setting will over write the global setting.
|
||||||
|
|
||||||
Once the volume has 'DisableRevisionCounter' to 'true', there won't be revision counter file. And the 'Automatic salvage' is 'true', when the engine is faulted, the engine will pick the most suitable replica as 'Source of Truth' to recover the volume.
|
Once the volume has 'DisableRevisionCounter' to 'true', there won't be revision counter file. And the 'Automatic salvage' is 'true', when the engine is fauled, the engine will pick the most suitable replica as 'Source of Truth' to recover the volume.
|
||||||
|
|
||||||
### API changes
|
### API changes
|
||||||
|
|
||||||
@ -63,12 +63,12 @@ And for the API compatibility issues, always check the 'EngineImage.Statue.cliAP
|
|||||||
|
|
||||||
1. Add 'Volume.Spec.RevisionCounterDisabled', 'Replica.Spec.RevisionCounterDisabled' and 'Engine.Spec.RevisionCounterDisabled' to volume, replica and engine objects.
|
1. Add 'Volume.Spec.RevisionCounterDisabled', 'Replica.Spec.RevisionCounterDisabled' and 'Engine.Spec.RevisionCounterDisabled' to volume, replica and engine objects.
|
||||||
2. Once 'RevisionCounterDisabled' is 'true', volume controller will set 'Volume.Spec.RevisionCounterDisabled' to true, 'Replica.Spec.RevisionCounterDisabled' and 'Engine.Spec.RevisionCounterDisabled' will set to true. And during 'ReplicaProcessCreate' and 'EngineProcessCreate' , this will be passed to engine replica process and engine controller process to start a replica and controller without revision counter.
|
2. Once 'RevisionCounterDisabled' is 'true', volume controller will set 'Volume.Spec.RevisionCounterDisabled' to true, 'Replica.Spec.RevisionCounterDisabled' and 'Engine.Spec.RevisionCounterDisabled' will set to true. And during 'ReplicaProcessCreate' and 'EngineProcessCreate' , this will be passed to engine replica process and engine controller process to start a replica and controller without revision counter.
|
||||||
3. During 'ReplicaProcessCreate' and 'EngineProcessCreate', if 'Replica.Spec.RevisionCounterDisabled' or 'Engine.Spec.RevisionCounterDisabled' is true, it will pass extra parameter to engine replica to start replica without revision counter or to engine controller to start controller without revision counter support, otherwise keep it the same as current and engine replica will use the default value 'false' for this extra parameter. This is the same as the engine controller to set the 'salvageRequested' flag.
|
3. During 'ReplicaProcessCreate' and 'EngineProcessCreate', if 'Replica.Spec.RevisionCounterDisabled' or 'Engine.Spec.RevisionCounterDisabled' is true, it will pass extra parameter to engine replica to start replica without revision counter or to engine controller to start controller without revision counter support, otherwise keep it the same as current and engine replica will use the default value 'false' for this extra paramter. This is the same as the engine controller to set the 'salvageRequested' flag.
|
||||||
4. Add 'RevisionCounterDisabled' in 'ReplicaInfo', when engine controller start, it will get all replica information.
|
4. Add 'RevisionCounterDisabled' in 'ReplicaInfo', when engine controller start, it will get all replica information.
|
||||||
4. For engine controller starting cases:
|
4. For engine controlloer starting cases:
|
||||||
- If revision counter is not disabled, stay with the current logic.
|
- If revision counter is not disabled, stay with the current logic.
|
||||||
- If revision counter is disabled, engine will not check the synchronization of the replicas.
|
- If revision counter is disabled, engine will not check the synchronization of the replicas.
|
||||||
- If unexpected case (engine controller has revision counter disabled but any of the replica doesn't, or engine controller has revision counter enabled, but any of the replica doesn't), engine controller will log this as error and mark unmatched replicas to 'ERR'.
|
- If unexpected case (engine controller has revision counter diabled but any of the replica doesn't, or engine controller has revision counter enabled, but any of the replica doesn't), engine controller will log this as error and mark unmatched replicas to 'ERR'.
|
||||||
|
|
||||||
#### Add New Logic for Salvage
|
#### Add New Logic for Salvage
|
||||||
|
|
||||||
@ -121,4 +121,4 @@ It can be set via 'StorageClass', and every PV created by this 'StorageClass' wi
|
|||||||
|
|
||||||
### Upgrade strategy
|
### Upgrade strategy
|
||||||
|
|
||||||
Deploy Longhorn image with v1.0.2 and upgrade Longhorn Manager, salvage function should still work. And then update Longhorn Engine, the revision counter disabled feature should be available.
|
Deploy Longhorn image with v1.0.2 and upgrade Longhorn Manager, salvage function should still work. And then update Longhorn Engine, the revision counter disabled feature should be availabe.
|
||||||
|
|||||||
@ -47,7 +47,7 @@ No API change is required.
|
|||||||
3. replica eviction happens (volume.Status.Robustness is Healthy)
|
3. replica eviction happens (volume.Status.Robustness is Healthy)
|
||||||
4. there is no potential reusable replica
|
4. there is no potential reusable replica
|
||||||
5. there is a potential reusable replica but the replica replenishment wait interval is passed.
|
5. there is a potential reusable replica but the replica replenishment wait interval is passed.
|
||||||
3. Reuse the failed replica by cleaning up `ReplicaSpec.HealthyAt` and `ReplicaSpec.FailedAt`. And `Replica.Spec.RebuildRetryCount` will be increased by 1.
|
3. Reuse the failed replica by cleaning up `ReplicaSpec.HealthyAt` and `ReplicaSpec.FailedAt`. And `Replica.Spec.RebuildRetryCount` will be increasd by 1.
|
||||||
4. Clean up the related record in `Replica.Spec.RebuildRetryCount` when the rebuilding replica becomes mode `RW`.
|
4. Clean up the related record in `Replica.Spec.RebuildRetryCount` when the rebuilding replica becomes mode `RW`.
|
||||||
5. Guarantee the reused failed replica will be stopped before re-launching it.
|
5. Guarantee the reused failed replica will be stopped before re-launching it.
|
||||||
|
|
||||||
|
|||||||
@ -72,7 +72,7 @@ For example, there are many times users ask us for supporting and the problems w
|
|||||||
If there is a CPU monitoring dashboard for instance managers, those problems can be quickly detected.
|
If there is a CPU monitoring dashboard for instance managers, those problems can be quickly detected.
|
||||||
|
|
||||||
#### Story 2
|
#### Story 2
|
||||||
User want to be notified about abnormal event such as disk space limit approaching.
|
User want to be notified about abnomal event such as disk space limit approaching.
|
||||||
We can expose metrics provide information about it and user can scrape the metrics and setup alert system.
|
We can expose metrics provide information about it and user can scrape the metrics and setup alert system.
|
||||||
|
|
||||||
### User Experience In Detail
|
### User Experience In Detail
|
||||||
@ -82,7 +82,7 @@ Users can use Prometheus or other monitoring systems to collect those metrics by
|
|||||||
Then, user can display the collected data using tools such as Grafana.
|
Then, user can display the collected data using tools such as Grafana.
|
||||||
User can also setup alert by using tools such as Prometheus Alertmanager.
|
User can also setup alert by using tools such as Prometheus Alertmanager.
|
||||||
|
|
||||||
Below are the descriptions of metrics which Longhorn exposes and how users can use them:
|
Below are the desciptions of metrics which Longhorn exposes and how users can use them:
|
||||||
|
|
||||||
1. longhorn_volume_capacity_bytes
|
1. longhorn_volume_capacity_bytes
|
||||||
|
|
||||||
@ -347,7 +347,7 @@ We add a new end point `/metrics` to exposes all longhorn Prometheus metrics.
|
|||||||
|
|
||||||
### Implementation Overview
|
### Implementation Overview
|
||||||
We follow the [Prometheus best practice](https://prometheus.io/docs/instrumenting/writing_exporters/#deployment), each Longhorn manager reports information about the components it manages.
|
We follow the [Prometheus best practice](https://prometheus.io/docs/instrumenting/writing_exporters/#deployment), each Longhorn manager reports information about the components it manages.
|
||||||
Prometheus can use service discovery mechanism to find all longhorn-manager pods in longhorn-backend service.
|
Prometheus can use service discovery mechanisim to find all longhorn-manager pods in longhorn-backend service.
|
||||||
|
|
||||||
We create a new collector for each type (volumeCollector, backupCollector, nodeCollector, etc..) and have a common baseCollector.
|
We create a new collector for each type (volumeCollector, backupCollector, nodeCollector, etc..) and have a common baseCollector.
|
||||||
This structure is similar to the controller package: we have volumeController, nodeController, etc.. which have a common baseController.
|
This structure is similar to the controller package: we have volumeController, nodeController, etc.. which have a common baseController.
|
||||||
|
|||||||
@ -1,212 +0,0 @@
|
|||||||
# RWX volume support
|
|
||||||
|
|
||||||
## Summary
|
|
||||||
|
|
||||||
We want to natively support RWX volumes, the creation and usage of these rwx volumes should preferably be transparent to the user.
|
|
||||||
This would make it so that there is no manual user interaction necessary, and a rwx volume just looks the same as regular Longhorn volume.
|
|
||||||
This would also allow any Longhorn volume to be used as rwx, without special requirements.
|
|
||||||
|
|
||||||
### Related Issues
|
|
||||||
|
|
||||||
https://github.com/longhorn/longhorn/issues/1470
|
|
||||||
https://github.com/Longhorn/Longhorn/issues/1183
|
|
||||||
|
|
||||||
## Motivation
|
|
||||||
### Goals
|
|
||||||
|
|
||||||
- support creation of RWX volumes via Longhorn
|
|
||||||
- support creation of RWX volumes via RWX pvc's
|
|
||||||
- support mounting NFS shares via the CSI driver
|
|
||||||
- creation of a share-manager that manages and exports volumes via NFS
|
|
||||||
|
|
||||||
### Non-goals
|
|
||||||
|
|
||||||
- clustered NFS (highly available)
|
|
||||||
- distributed filesystem
|
|
||||||
|
|
||||||
## Proposal
|
|
||||||
|
|
||||||
RWX volumes should support all operations that a regular RWO volumes supports (backup & restore, DR volume support, etc)
|
|
||||||
|
|
||||||
### User Stories
|
|
||||||
#### Native RWX support
|
|
||||||
Before this enhancement we create an RWX provisioner example that was using a regular Longhorn volume to export multiple NFS shares.
|
|
||||||
The provisioner then created native kubernetes NFS persistent volumes, there where many limitations with this approach (multiple workload pvs on one Longhorn volume, restore & backup is iffy, etc)
|
|
||||||
|
|
||||||
After this enhancement anytime a user uses an RWX pvc we will provision a Longhorn volume and expose the volume via a share-manager.
|
|
||||||
The CSI driver will then mount this volume that is exported via a NFS server from the share-manager pod.
|
|
||||||
|
|
||||||
|
|
||||||
### User Experience In Detail
|
|
||||||
|
|
||||||
Users can automatically provision and use an RWX volume by having their workload use an RWX pvc.
|
|
||||||
Users can see the status of their RWX volumes in the Longhorn UI, same as for RWO volumes.
|
|
||||||
Users can use the created RWX volume on different nodes at the same time.
|
|
||||||
|
|
||||||
|
|
||||||
### API changes
|
|
||||||
- add `AccessMode` field to the `Volume.Spec`
|
|
||||||
- add `ShareEndpoint, ShareState` fields to the `Volume.Status`
|
|
||||||
- add a new ShareManager crd, details below
|
|
||||||
|
|
||||||
```go
|
|
||||||
type ShareManagerState string
|
|
||||||
|
|
||||||
const (
|
|
||||||
ShareManagerStateUnknown = ShareManagerState("unknown")
|
|
||||||
ShareManagerStateStarting = ShareManagerState("starting")
|
|
||||||
ShareManagerStateRunning = ShareManagerState("running")
|
|
||||||
ShareManagerStateStopped = ShareManagerState("stopped")
|
|
||||||
ShareManagerStateError = ShareManagerState("error")
|
|
||||||
)
|
|
||||||
|
|
||||||
type ShareManagerSpec struct {
|
|
||||||
Image string `json:"image"`
|
|
||||||
}
|
|
||||||
|
|
||||||
type ShareManagerStatus struct {
|
|
||||||
OwnerID string `json:"ownerID"`
|
|
||||||
State ShareManagerState `json:"state"`
|
|
||||||
Endpoint string `json:"endpoint"`
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
### Implementation Overview
|
|
||||||
|
|
||||||
#### Key Components
|
|
||||||
- Volume controller is responsible for creation of share manager crd and synchronising share status and endpoint of the volume with the share manager resource.
|
|
||||||
- Share manager controller will be responsible for managing share manager pods and ensuring volume attachment to the share manager pod.
|
|
||||||
- Share manager pod is responsible for health checking and managing the NFS server volume export.
|
|
||||||
- CSI driver is responsible for mounting the NFS export to the workload pod
|
|
||||||
|
|
||||||
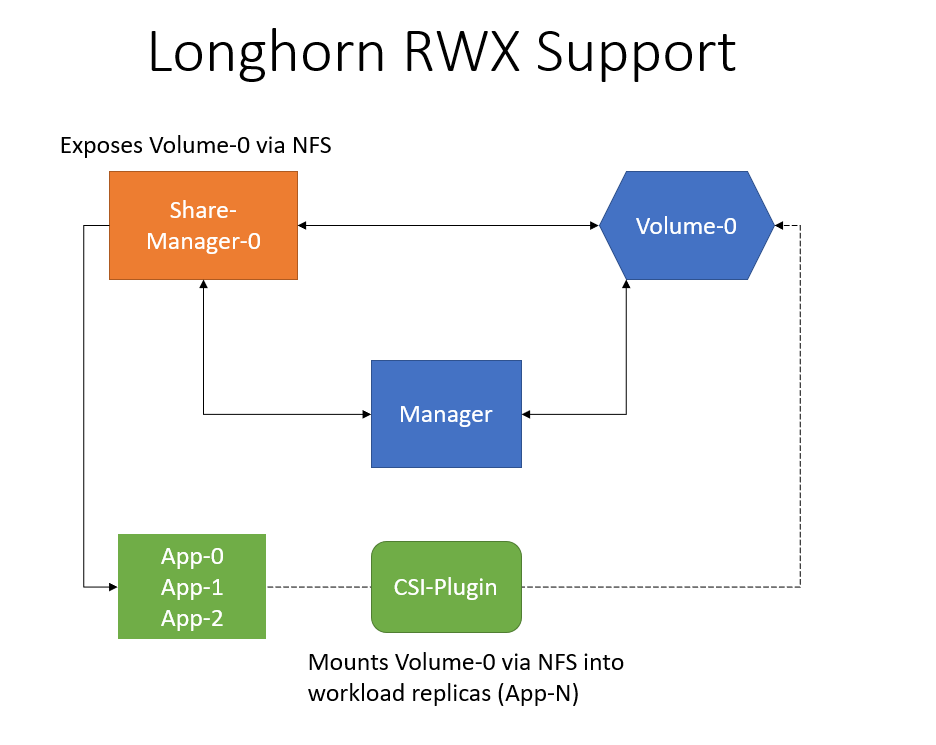
|
|
||||||
|
|
||||||
#### From volume creation to usage
|
|
||||||
When a new RWX volume with name `test-volume` is created, the volume controller will create a matching share-manager resource with name `test-volume`.
|
|
||||||
The share-manager-controller will pickup this new share-manager resource and create share-manager pod with name `share-manager-test-volume` in the longhorn-system namespace,
|
|
||||||
as well as a service named `test-volume` that always points to the share-manager-pod `share-manager-test-volume`.
|
|
||||||
The controller will set the `State=Starting` while the share-manager-pod is Pending and not `Ready` yet.
|
|
||||||
|
|
||||||
The share-manager-pod is running our share-manager image which allows for exporting a block device via ganesha (NFS server).
|
|
||||||
After starting the share-manager, the application waits for the attachment of the volume `test-volume`,
|
|
||||||
this is done by an availability check of the block device in the bind-mounted `/host/dev/longhorn/test-volume` folder.
|
|
||||||
|
|
||||||
The actual volume attachment is handled by the share-manager-controller setting volume.spec.nodeID to the `node` of the share-manager-pod.
|
|
||||||
Once the volume is attached the share-manager will mount the volume, create export config and start ganesha (NFS server).
|
|
||||||
Afterwards the share-manager will do periodic health check against the attached volume and on failure of a health check the pod will terminate.
|
|
||||||
The share-manager pod will become `ready` as soon as ganesha is up and running this is accomplished via a check against `/var/run/ganesha.pid`.
|
|
||||||
|
|
||||||
The share-manager-controller can now update the share-manager `State=Running` and `Endpoint=nfs://service-cluster-ip/test-volume"`.
|
|
||||||
The volume-controller will update the volumes `ShareState` and `ShareEndpoint` based on the values of the share-manager `State` and `Endpoint`.
|
|
||||||
Once the volumes `ShareState` is `Running` the csi-driver can now successfully attach & mount the volume into the workload pods.
|
|
||||||
|
|
||||||
#### Recovering from share-manager node/volume/pod failures
|
|
||||||
On node failure Kubernetes will mark the share-manager-pod `share-manager-test-volume` as terminating.
|
|
||||||
The share-manager-controller will mark the share-manager `State=Error` if the share-manager pod is in any state other than `Running` or `Pending`, unless
|
|
||||||
the share-manager is no longer required for this volume (no workloads consuming this volume).
|
|
||||||
|
|
||||||
When the share-manager `State` is `Error` the volume-controller will continuously set the volumes `RemountRequestedAt=Now` so that we will cleanup the workload pods
|
|
||||||
till the share-manager is back in order. This cleanup is to force the workload pods to initiate a new connection against the NFS server.
|
|
||||||
In the future we hope to reuse the NFS connection which will make this step no longer necessary.
|
|
||||||
|
|
||||||
The share-manager-controller will start a new share-manager pod on a different node and set `State=Starting`.
|
|
||||||
Once the pod is `Ready` the controller will set `State=Running` and the workload pods are now able to reconnect/remount again.
|
|
||||||
See above for the complete flow from `Starting -> Ready -> Running -> volume share available`
|
|
||||||
|
|
||||||
### Test plan
|
|
||||||
|
|
||||||
- [Manual tests for RWX feature](https://github.com/longhorn/longhorn-tests/pull/496)
|
|
||||||
- [E2E tests for RWX feature](https://github.com/longhorn/longhorn-tests/pull/512)
|
|
||||||
|
|
||||||
### Upgrade strategy
|
|
||||||
- User needs to add a new share-manager-image to airgapped environments
|
|
||||||
- Created a [migration job](https://longhorn.io/docs/1.1.0/advanced-resources/rwx-workloads/#migration-from-previous-external-provisioner) to allow users to migrate data from previous NFS provisioner or other RWO volumes
|
|
||||||
|
|
||||||
## Information & References
|
|
||||||
|
|
||||||
### NFS ganesha details
|
|
||||||
- [overview grace period and recovery](https://www.programmersought.com/article/19554210230/)
|
|
||||||
- [code grace period and recovery](https://www.programmersought.com/article/53201520803/)
|
|
||||||
- [code & architecture overview](https://www.programmersought.com/article/12291336147/)
|
|
||||||
- [kernel server vs ganesha](https://events.static.linuxfound.org/sites/events/files/slides/Collab14_nfsGanesha.pdf)
|
|
||||||
|
|
||||||
### NFS ganesha DBUS
|
|
||||||
- [DBUS-Interface](https://github.com/nfs-ganesha/nfs-ganesha/wiki/Dbusinterface#orgganeshanfsdadmin)
|
|
||||||
- [DBUS-Exports](https://github.com/nfs-ganesha/nfs-ganesha/wiki/DBusExports)
|
|
||||||
|
|
||||||
The dbus interface can be used to add & remove exports.
|
|
||||||
As well as make the server go into the grace period.
|
|
||||||
|
|
||||||
### NFS grace period
|
|
||||||
- [NFS_lock_recovery_notes](https://linux-nfs.org/wiki/index.php/NFS_lock_recovery_notes)
|
|
||||||
- [lower grace period](https://www.suse.com/support/kb/doc/?id=000019374)
|
|
||||||
|
|
||||||
### Ceph ganesha
|
|
||||||
- [rook crd for ganesha](https://github.com/rook/rook/blob/master/design/ceph/ceph-nfs-ganesha.md)
|
|
||||||
- [ganesha driver class library](https://docs.openstack.org/manila/rocky/contributor/ganesha.html)
|
|
||||||
|
|
||||||
### NFS ganesha Active Passive Setups
|
|
||||||
- [pacemaker & drbd, suse](https://documentation.suse.com/sle-ha/12-SP4/#redirectmsg)
|
|
||||||
- [pacemaker & corosync, redhat](https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/high_availability_add-on_administration/ch-nfsserver-haaa)
|
|
||||||
|
|
||||||
### NFS ganesha recovery backends
|
|
||||||
|
|
||||||
Rados requires ceph, some more difference between kv/ng
|
|
||||||
- https://bugzilla.redhat.com/show_bug.cgi?id=1557465
|
|
||||||
- https://lists.nfs-ganesha.org/archives/list/devel@lists.nfs-ganesha.org/thread/DPULRQKCGB2QQUCUMOVDOBHCPJL22QMX/
|
|
||||||
|
|
||||||
**rados_kv**: This is the original rados recovery backend that uses a key-
|
|
||||||
value store. It has support for "takeover" operations: merging one
|
|
||||||
recovery database into another such that another cluster node could take
|
|
||||||
over addresses that were hosted on another node. Note that this recovery
|
|
||||||
backend may not survive crashes that occur _during_ a grace period. If
|
|
||||||
it crashes and then crashes again during the grace period, the server is
|
|
||||||
likely to fail to allow any clients to recover (the db will be trashed).
|
|
||||||
|
|
||||||
**rados_ng**: a more resilient rados_kv backend. This one does not support
|
|
||||||
takeover operations, but it should properly survive crashes that occur
|
|
||||||
during the grace period.
|
|
||||||
|
|
||||||
**rados_cluster**: the new (experimental) clustered recovery backend. This
|
|
||||||
one also does not support address takeover, but should be resilient
|
|
||||||
enough to handle crashes that occur during the grace period.
|
|
||||||
|
|
||||||
FWIW, the semantics for fs vs. fs_ng are similar. fs doesn't survive
|
|
||||||
crashes that occur during the grace period either.
|
|
||||||
|
|
||||||
Unless you're trying to use the dbus "grace" command to initiate address
|
|
||||||
takeover in an active/active cluster, you probably want rados_ng for
|
|
||||||
now.
|
|
||||||
|
|
||||||
### CSI lifecycle:
|
|
||||||
```
|
|
||||||
CreateVolume +------------+ DeleteVolume
|
|
||||||
+------------->| CREATED +--------------+
|
|
||||||
| +---+----^---+ |
|
|
||||||
| Controller | | Controller v
|
|
||||||
+++ Publish | | Unpublish +++
|
|
||||||
|X| Volume | | Volume | |
|
|
||||||
+-+ +---v----+---+ +-+
|
|
||||||
| NODE_READY |
|
|
||||||
+---+----^---+
|
|
||||||
Node | | Node
|
|
||||||
Stage | | Unstage
|
|
||||||
Volume | | Volume
|
|
||||||
+---v----+---+
|
|
||||||
| VOL_READY |
|
|
||||||
+---+----^---+
|
|
||||||
Node | | Node
|
|
||||||
Publish | | Unpublish
|
|
||||||
Volume | | Volume
|
|
||||||
+---v----+---+
|
|
||||||
| PUBLISHED |
|
|
||||||
+------------+
|
|
||||||
```
|
|
||||||
Figure 6: The lifecycle of a dynamically provisioned volume, from
|
|
||||||
creation to destruction, when the Node Plugin advertises the
|
|
||||||
STAGE_UNSTAGE_VOLUME capability.
|
|
||||||
|
|
||||||
### Previous Engine migration feature
|
|
||||||
https://github.com/longhorn/longhorn-manager/commit/2636a5dc6d79aa12116e7e5685ccd831747639df
|
|
||||||
https://github.com/longhorn/longhorn-tests/commit/3a55d6bfe633165fb6eb9553235b7d0a2e651cec
|
|
||||||
@ -1,173 +0,0 @@
|
|||||||
# Upgrade Volume's Engine Image Automatically
|
|
||||||
|
|
||||||
## Summary
|
|
||||||
|
|
||||||
Currently, users need to upgrade the engine image manually in the UI after upgrading Longhorn.
|
|
||||||
We should provide an option. When it is enabled, automatically upgrade engine images for volumes when it is applicable.
|
|
||||||
|
|
||||||
### Related Issues
|
|
||||||
|
|
||||||
https://github.com/longhorn/longhorn/issues/2152
|
|
||||||
|
|
||||||
## Motivation
|
|
||||||
|
|
||||||
### Goals
|
|
||||||
|
|
||||||
Reduce the amount of manual work users have to do when upgrading Longhorn by automatically upgrade engine images
|
|
||||||
for volumes when they are ok to upgrade. E.g. when we can do engine live upgrade or when volume is in detaching state.
|
|
||||||
|
|
||||||
## Proposal
|
|
||||||
|
|
||||||
Add a new boolean setting, `Concurrent Automatic Engine Upgrade Per Node Limit`, so users can control how Longhorn upgrade engines.
|
|
||||||
The value of this setting specifies the maximum number of engines per node that are allowed to upgrade to the default engine image at the same time.
|
|
||||||
If the value is 0, Longhorn will not automatically upgrade volumes' engines to default version.
|
|
||||||
|
|
||||||
After user upgrading Longhorn to a new version, there will be a new default engine image and possibly a new default instance manager image.
|
|
||||||
|
|
||||||
The proposal has 2 parts:
|
|
||||||
1. In which component we will do the upgrade.
|
|
||||||
2. Identify when is it ok to upgrade engine for volume to the new default engine image.
|
|
||||||
|
|
||||||
For part 1, we will do the upgrade inside `engine image controller`.
|
|
||||||
The controller will constantly watch and upgrade the engine images for volumes when it is ok to upgrade.
|
|
||||||
|
|
||||||
For part 2, we upgrade engine image for a volume when the following conditions are met:
|
|
||||||
1. The new default engine image is ready
|
|
||||||
1. Volume is not upgrading engine image
|
|
||||||
1. The volume condition is one of the following:
|
|
||||||
1. Volume is in detached state.
|
|
||||||
1. Volume is in attached state (live upgrade).
|
|
||||||
And volume is healthy.
|
|
||||||
And The current volume's engine image is compatible with the new default engine image.
|
|
||||||
And If volume is not a DR volume.
|
|
||||||
And Volume is not expanding.
|
|
||||||
|
|
||||||
### User Stories
|
|
||||||
|
|
||||||
Before this enhancement, users have to manually upgrade engine images for volume after upgrading Longhorn system to a newer version.
|
|
||||||
If there are thousands of volumes in the system, this is a significant manual work.
|
|
||||||
|
|
||||||
After this enhancement users either have to do nothing (in case live upgrade is possible)
|
|
||||||
or they only have to scale down/up the workload (in case there is a new default IM image)
|
|
||||||
|
|
||||||
### User Experience In Detail
|
|
||||||
|
|
||||||
1. User upgrade Longhorn to a newer version.
|
|
||||||
The new Longhorn version is compatible with the volume's current engine image.
|
|
||||||
Longhorn automatically do live engine image upgrade for volumes
|
|
||||||
|
|
||||||
2. User upgrade Longhorn to a newer version.
|
|
||||||
The new Longhorn version is not compatible with the volume's current engine image.
|
|
||||||
Users only have to scale the workload down and up.
|
|
||||||
This experience is similar to restart Google Chrome to use a new version.
|
|
||||||
|
|
||||||
3. Note that users need to disable this feature if they want to update the engine image to a specific version for the volumes.
|
|
||||||
If `Concurrent Automatic Engine Upgrade Per Node Limit` setting is bigger than 0, Longhorn will not allow user to manually upgrade engine to a version other than the default version.
|
|
||||||
|
|
||||||
### API changes
|
|
||||||
|
|
||||||
No API change is needed.
|
|
||||||
|
|
||||||
## Design
|
|
||||||
|
|
||||||
### Implementation Overview
|
|
||||||
|
|
||||||
1. Inside `engine image controller` sync function, get the value of the setting `Concurrent Automatic Engine Upgrade Per Node Limit` and assign it to concurrentAutomaticEngineUpgradePerNodeLimit variable.
|
|
||||||
If concurrentAutomaticEngineUpgradePerNodeLimit <= 0, we skip upgrading.
|
|
||||||
1. Find the new default engine image. Check if the new default engine image is ready. If it is not we skip the upgrade.
|
|
||||||
|
|
||||||
1. List all volumes in Longhorn system.
|
|
||||||
Select a set of volume candidate for upgrading.
|
|
||||||
We select candidates that has the condition is one of the following case:
|
|
||||||
1. Volume is in detached state.
|
|
||||||
1. Volume is in attached state (live upgrade).
|
|
||||||
And volume is healthy.
|
|
||||||
And Volume is not upgrading engine image.
|
|
||||||
And The current volume's engine image is compatible with the new default engine image.
|
|
||||||
And the volume is not a DR volume.
|
|
||||||
And volume is not expanding.
|
|
||||||
|
|
||||||
1. Make sure not to upgrade too many volumes on the same node at the same time.
|
|
||||||
Filter the upgrading candidate set so that total number of upgrading volumes and candidates per node is not over `concurrentAutomaticEngineUpgradePerNodeLimit`.
|
|
||||||
1. For each volume candidate, set `v.Spec.EngineImage = new default engine image` to update the engine for the volume.
|
|
||||||
1. If the engine upgrade failed to complete (e.g. the v.Spec.EngineImage != v.Status.CurrentImage),
|
|
||||||
we just consider it is the same as volume is in upgrading process and skip it.
|
|
||||||
Volume controller will handle the reconciliation when it is possible.
|
|
||||||
|
|
||||||
### Test plan
|
|
||||||
|
|
||||||
|
|
||||||
Integration test plan.
|
|
||||||
|
|
||||||
Preparation:
|
|
||||||
1. set up a backup store
|
|
||||||
2. Deploy a compatible new engine image
|
|
||||||
|
|
||||||
Case 1: Concurrent engine upgrade
|
|
||||||
1. Create 10 volumes each of 1Gb.
|
|
||||||
2. Attach 5 volumes vol-0 to vol-4. Write data to it
|
|
||||||
3. Upgrade all volumes to the new engine image
|
|
||||||
4. Wait until the upgrades are completed (volumes' engine image changed,
|
|
||||||
replicas' mode change to RW for attached volumes, reference count of the
|
|
||||||
new engine image changed, all engine and replicas' engine image changed)
|
|
||||||
5. Set concurrent-automatic-engine-upgrade-per-node-limit setting to 3
|
|
||||||
6. In a retry loop, verify that the number of volumes who
|
|
||||||
is upgrading engine is always smaller or equal to 3
|
|
||||||
7. Wait until the upgrades are completed (volumes' engine image changed,
|
|
||||||
replica mode change to RW for attached volumes, reference count of the
|
|
||||||
new engine image changed, all engine and replicas' engine image changed,
|
|
||||||
etc ...)
|
|
||||||
8. verify the volumes' data
|
|
||||||
|
|
||||||
Case 2: Dr volume
|
|
||||||
1. Create a backup for vol-0. Create a DR volume from the backup
|
|
||||||
2. Try to upgrade the DR volume engine's image to the new engine image
|
|
||||||
3. Verify that the Longhorn API returns error. Upgrade fails.
|
|
||||||
4. Set concurrent-automatic-engine-upgrade-per-node-limit setting to 0
|
|
||||||
5. Try to upgrade the DR volume engine's image to the new engine image
|
|
||||||
6. Wait until the upgrade are completed (volumes' engine image changed,
|
|
||||||
replicas' mode change to RW, reference count of the new engine image
|
|
||||||
changed, engine and replicas' engine image changed)
|
|
||||||
7. Wait for the DR volume to finish restoring
|
|
||||||
8. Set concurrent-automatic-engine-upgrade-per-node-limit setting to 3
|
|
||||||
9. In a 2-min retry loop, verify that Longhorn doesn't automatically
|
|
||||||
upgrade engine image for DR volume.
|
|
||||||
|
|
||||||
Case 3: Expanding volume
|
|
||||||
1. set concurrent-automatic-engine-upgrade-per-node-limit setting to 0
|
|
||||||
2. Upgrade vol-0 to the new engine image
|
|
||||||
3. Wait until the upgrade are completed (volumes' engine image changed,
|
|
||||||
replicas' mode change to RW, reference count of the new engine image
|
|
||||||
changed, engine and replicas' engine image changed)
|
|
||||||
4. Detach vol-0
|
|
||||||
5. Expand the vol-0 from 1Gb to 5GB
|
|
||||||
6. Wait for the vol-0 to start expanding
|
|
||||||
7. Set concurrent-automatic-engine-upgrade-per-node-limit setting to 3
|
|
||||||
8. While vol-0 is expanding, verify that its engine is not upgraded to
|
|
||||||
the default engine image
|
|
||||||
9. Wait for the expansion to finish and vol-0 is detached
|
|
||||||
10. Verify that Longhorn upgrades vol-0's engine to the default version
|
|
||||||
|
|
||||||
Case 4: Degraded volume
|
|
||||||
1. set concurrent-automatic-engine-upgrade-per-node-limit setting to 0
|
|
||||||
2. Upgrade vol-1 (an healthy attached volume) to the new engine image
|
|
||||||
3. Wait until the upgrade are completed (volumes' engine image changed,
|
|
||||||
replicas' mode change to RW, reference count of the new engine image
|
|
||||||
changed, engine and replicas' engine image changed)
|
|
||||||
4. Increase number of replica count to 4 to make the volume degraded
|
|
||||||
5. Set concurrent-automatic-engine-upgrade-per-node-limit setting to 3
|
|
||||||
6. In a 2-min retry loop, verify that Longhorn doesn't automatically
|
|
||||||
upgrade engine image for vol-1.
|
|
||||||
|
|
||||||
Cleaning up:
|
|
||||||
1. Clean up volumes
|
|
||||||
2. Reset automatically-upgrade-engine-to-default-version setting in
|
|
||||||
the client fixture
|
|
||||||
|
|
||||||
### Upgrade strategy
|
|
||||||
|
|
||||||
No upgrade strategy is needed.
|
|
||||||
|
|
||||||
|
|
||||||
### Additional Context
|
|
||||||
None
|
|
||||||
@ -1,98 +0,0 @@
|
|||||||
# Enhanced CPU Reservation
|
|
||||||
|
|
||||||
## Summary
|
|
||||||
To make sure Longhorn system stable enough, we can apply the node specific CPU resource reservation mechanism to avoid the engine/replica engine crash due to the CPU resource exhaustion.
|
|
||||||
|
|
||||||
### Related Issues
|
|
||||||
https://github.com/longhorn/longhorn/issues/2207
|
|
||||||
|
|
||||||
## Motivation
|
|
||||||
### Goals
|
|
||||||
1. Reserve CPU resource separately for engine manager pods and replica manager pods.
|
|
||||||
2. The reserved CPU count is node specific:
|
|
||||||
1. The more allocable CPU resource a node has, the more CPUs be will reserved for the instance managers in general.
|
|
||||||
2. Allow reserving CPU resource for a specific node. This setting will override the global setting.
|
|
||||||
|
|
||||||
### Non-goals
|
|
||||||
1. Guarantee that the CPU resource is always enough, or the CPU resource reservation is always reasonable based on the volume numbers of a node.
|
|
||||||
2. Notify/Warn users CPU resource exhaustion on a node: https://github.com/longhorn/longhorn/issues/1930
|
|
||||||
|
|
||||||
## Proposal
|
|
||||||
1. Add new fields `node.Spec.EngineManagerCPURequest` and `node.Spec.ReplicaManagerCPURequest`. This allows reserving a different amount of CPU resource for a specific node.
|
|
||||||
2. Add two settings `Guaranteed Engine Manager CPU` and `Guaranteed Replica Manager CPU`:
|
|
||||||
1. It indicates how many percentages of CPU on a node will be reserved for one engine/replica manager pod.
|
|
||||||
2. The old settings `Guaranteed Engine CPU` will be deprecated:
|
|
||||||
- This setting will be unset and readonly in the new version.
|
|
||||||
- For the old Longhorn system upgrade, Longhorn will automatically set the node fields based on the old setting then clean up the old setting, so that users don't need to do anything manually as well as not affect existing instance manager pods.
|
|
||||||
|
|
||||||
### User Stories
|
|
||||||
Before the enhancement, users rely on the setting `Guaranteed Engine CPU` to reserve the same amount of CPU resource for all engine managers and all replica managers on all nodes. There is no way to reserve more CPUs for the instance managers on node having more allocable CPUs.
|
|
||||||
|
|
||||||
After the enhancement, users can:
|
|
||||||
1. Modify the global settings `Guaranteed Engine Manager CPU` and `Guaranteed Replica Manager CPU` to reserve how many percentage of CPUs for engine manager pods and replica manager pods, respectively.
|
|
||||||
2. Set a different CPU value for the engine/replica manager pods on some particular nodes by `Node Edit`.
|
|
||||||
|
|
||||||
### API Changes
|
|
||||||
Add a new field `EngineManagerCPURequest` and `ReplicaManagerCPURequest` for node objects.
|
|
||||||
|
|
||||||
## Design
|
|
||||||
### Implementation Overview
|
|
||||||
#### longhorn-manager:
|
|
||||||
1. Add 2 new settings `Guaranteed Engine Manager CPU` and `Guaranteed Replica Manager CPU`.
|
|
||||||
- These 2 setting values are integers ranging from 0 to 40.
|
|
||||||
- The sum of the 2 setting values should be smaller than 40 (%) as well.
|
|
||||||
2. In Node Controller, The requested CPU resource when creating an instance manager pod:
|
|
||||||
1. Ignore the deprecated setting `Guaranteed Engine CPU`.
|
|
||||||
2. If the newly introduced node field `node.Spec.EngineManagerCPURequest`/`node.Spec.ReplicaManagerCPURequest` is not empty, the engine/replica manager pod requested CPU is determined by the field value. Notice that the field value is a milli value.
|
|
||||||
3. Else using the formula based on setting `Guaranteed Engine Manager CPU`/`Guaranteed Replica Manager CPU`:
|
|
||||||
`The Reserved CPUs = The value of field "kubenode.status.allocatable.cpu" * The setting values * 0.01`.
|
|
||||||
3. In Setting Controller
|
|
||||||
- The current requested CPU of an instance manager pod should keep same as `node.Spec.EngineManagerCPURequest`/`node.Spec.ReplicaManagerCPURequest`,
|
|
||||||
or the value calculated by the above formula. Otherwise, the pod will be killed then Node Controller will recreate it later.
|
|
||||||
4. In upgrade
|
|
||||||
- Longhorn should update `node.Spec.EngineManagerCPURequest` and `node.Spec.ReplicaManagerCPURequest` based on setting `Guaranteed Engine CPU` then clean up `Guaranteed Engine CPU`.
|
|
||||||
|
|
||||||
The fields 0 means Longhorn will use the setting values directly. The setting value 0 means removing the CPU requests for instance manager pods.
|
|
||||||
|
|
||||||
#### longhorn-ui:
|
|
||||||
- Add 2 new arguments `Guaranteed Engine Manager CPU(Milli)` and `Guaranteed Replica Manager CPU(Milli)` in the node update page.
|
|
||||||
- Hide the deprecated setting `Guaranteed Engine CPU` which is type `Deprecated`. Type `Deprecated` is a newly introduced setting type.
|
|
||||||
|
|
||||||
### Test Plan
|
|
||||||
#### Integration tests
|
|
||||||
- Update the existing test case `test_setting_guaranteed_engine_cpu`:
|
|
||||||
- Validate the settings `Guaranteed Engine Manager CPU` controls the reserved CPUs of engine manager pods on each node.
|
|
||||||
- Validate the settings `Guaranteed Replica Manager CPU` controls the reserved CPUs of replica manager pods on each node.
|
|
||||||
- Validate that fields `node.Spec.EngineManagerCPURequest`/`node.Spec.ReplicaManagerCPURequest` can override the settings `Guaranteed Engine Manager CPU`/`Guaranteed Replica Manager CPU`.
|
|
||||||
|
|
||||||
#### Manual tests
|
|
||||||
##### The system upgrade with the deprecated setting.
|
|
||||||
1. Deploy a cluster that each node has different CPUs.
|
|
||||||
2. Launch Longhorn v1.1.0.
|
|
||||||
3. Deploy some workloads using Longhorn volumes.
|
|
||||||
4. Upgrade to the latest Longhorn version. Validate:
|
|
||||||
1. all workloads work fine and no instance manager pod crash during the upgrade.
|
|
||||||
2. The fields `node.Spec.EngineManagerCPURequest` and `node.Spec.ReplicaManagerCPURequest` of each node are the same as the setting `Guaranteed Engine CPU` value in the old version * 1000.
|
|
||||||
3. The old setting `Guaranteed Engine CPU` is deprecated with an empty value.
|
|
||||||
5. Modify new settings `Guaranteed Engine Manager CPU` and `Guaranteed Replica Manager CPU`. Validate all workloads work fine and no instance manager pod restart.
|
|
||||||
6. Scale down all workloads and wait for the volume detachment.
|
|
||||||
7. Set `node.Spec.EngineManagerCPURequest` and `node.Spec.ReplicaManagerCPURequest` to 0 for some node. Verify the new settings will be applied to those node and the related instance manager pods will be recreated with the CPU requests matching the new settings.
|
|
||||||
8. Scale up all workloads and verify the data as well as the volume r/w.
|
|
||||||
9. Do cleanup.
|
|
||||||
|
|
||||||
##### Test system upgrade with new instance manager
|
|
||||||
1. Prepare 3 sets of longhorn-manager and longhorn-instance-manager images.
|
|
||||||
2. Deploy Longhorn with the 1st set of images.
|
|
||||||
3. Set `Guaranteed Engine Manager CPU` and `Guaranteed Replica Manager CPU` to 15 and 24, respectively.
|
|
||||||
Then wait for the instance manager recreation.
|
|
||||||
4. Create and attach a volume to a node (node1).
|
|
||||||
5. Upgrade the Longhorn system with the 2nd set of images.
|
|
||||||
Verify the CPU requests in the pods of both instance managers match the settings.
|
|
||||||
6. Create and attach one more volume to node1.
|
|
||||||
7. Upgrade the Longhorn system with the 3rd set of images.
|
|
||||||
8. Verify the pods of the 3rd instance manager cannot be launched on node1 since there is no available CPU for the allocation.
|
|
||||||
9. Detach the volume in the 1st instance manager pod.
|
|
||||||
Verify the related instance manager pods will be cleaned up and the new instance manager pod can be launched on node1.
|
|
||||||
|
|
||||||
### Upgrade strategy
|
|
||||||
N/A
|
|
||||||
@ -1,235 +0,0 @@
|
|||||||
# Volume live migration
|
|
||||||
|
|
||||||
## Summary
|
|
||||||
|
|
||||||
To enable Harvester to utilize Kubevirts live migration support, we need to allow for volume live migration,
|
|
||||||
so that a Kubevirt triggered migration will lead to a volume migration from the old node to the new node.
|
|
||||||
|
|
||||||
### Related Issues
|
|
||||||
- https://github.com/longhorn/longhorn/issues/2127
|
|
||||||
- https://github.com/rancher/harvester/issues/384
|
|
||||||
- https://github.com/longhorn/longhorn/issues/87
|
|
||||||
|
|
||||||
## Motivation
|
|
||||||
|
|
||||||
### Goals
|
|
||||||
- Support Harvester VM live migration
|
|
||||||
|
|
||||||
### Non-goals
|
|
||||||
- Using multiple engines for faster volume failover for other scenarios than live migration
|
|
||||||
|
|
||||||
## Proposal
|
|
||||||
We want to add volume migration support so that we can use the VM live migration support of Kubevirt via Harvester.
|
|
||||||
By limiting this feature to that specific use case we can use the csi drivers attach / detach flow to implement migration interactions.
|
|
||||||
To do this, we need to be able to start a second engine for a volume on a different node that uses matching replicas of the first engine.
|
|
||||||
We only support this for a volume while it is used with `volumeMode=BLOCK`, since we don't support concurrent writes and having kubernetes mount a filesystem even in read only
|
|
||||||
mode can potentially lead to a modification of the filesystem (metadata, access time, journal replay, etc).
|
|
||||||
|
|
||||||
|
|
||||||
### User Stories
|
|
||||||
Previously the only way to support live migration in Harvester was using a Longhorn RWX volume that meant dealing with NFS and it's problems,
|
|
||||||
instead we want to add support for live migration for a traditional Longhorn volume this was previously implemented for the old RancherVM.
|
|
||||||
After this enhancement Longhorn will support a special `migratable` flag that allows for a Longhorn volume to be live migrated from one node to another.
|
|
||||||
The assumption here is that the initial consumer will never write again to the block device once the new consumer takes over.
|
|
||||||
|
|
||||||
|
|
||||||
### User Experience In Detail
|
|
||||||
|
|
||||||
#### Creating a migratable storage class
|
|
||||||
To test one needs to create a storage class with `migratable: "true"` set as a parameter.
|
|
||||||
Afterwards an RWX PVC is necessary since migratable volumes need to be able to be attached to multiple nodes.
|
|
||||||
```yaml
|
|
||||||
kind: StorageClass
|
|
||||||
apiVersion: storage.k8s.io/v1
|
|
||||||
metadata:
|
|
||||||
name: longhorn-migratable
|
|
||||||
provisioner: driver.longhorn.io
|
|
||||||
allowVolumeExpansion: true
|
|
||||||
parameters:
|
|
||||||
numberOfReplicas: "3"
|
|
||||||
staleReplicaTimeout: "2880" # 48 hours in minutes
|
|
||||||
fromBackup: ""
|
|
||||||
migratable: "true"
|
|
||||||
```
|
|
||||||
|
|
||||||
#### Testing Kubevirt VM live migration
|
|
||||||
We use CirOS as our test image for the live migration.
|
|
||||||
The login account is `cirros` and the password is `gocubsgo`.
|
|
||||||
To test with Harvester one can use the below example yamls as a quick start.
|
|
||||||
|
|
||||||
Deploy the below yaml so that Harvester will download the CirrOS image into the local Minio store.
|
|
||||||
NOTE: The CirrOS servers don't support the range request which Kubevirt importer uses, which is why we let harvester download the image first.
|
|
||||||
```yaml
|
|
||||||
apiVersion: harvester.cattle.io/v1alpha1
|
|
||||||
kind: VirtualMachineImage
|
|
||||||
metadata:
|
|
||||||
name: image-jxpnq
|
|
||||||
namespace: default
|
|
||||||
spec:
|
|
||||||
displayName: cirros-0.4.0-x86_64-disk.img
|
|
||||||
url: https://download.cirros-cloud.net/0.4.0/cirros-0.4.0-x86_64-disk.img
|
|
||||||
```
|
|
||||||
|
|
||||||
Afterwards deploy the `cirros-rwx-blk.yaml` to create a live migratable virtual machine.
|
|
||||||
```yaml
|
|
||||||
apiVersion: kubevirt.io/v1alpha3
|
|
||||||
kind: VirtualMachine
|
|
||||||
metadata:
|
|
||||||
labels:
|
|
||||||
harvester.cattle.io/creator: harvester
|
|
||||||
name: cirros-rwx-blk
|
|
||||||
spec:
|
|
||||||
dataVolumeTemplates:
|
|
||||||
- apiVersion: cdi.kubevirt.io/v1alpha1
|
|
||||||
kind: DataVolume
|
|
||||||
metadata:
|
|
||||||
annotations:
|
|
||||||
cdi.kubevirt.io/storage.import.requiresScratch: "true"
|
|
||||||
name: cirros-rwx-blk
|
|
||||||
spec:
|
|
||||||
pvc:
|
|
||||||
accessModes:
|
|
||||||
- ReadWriteMany
|
|
||||||
resources:
|
|
||||||
requests:
|
|
||||||
storage: 8Gi
|
|
||||||
storageClassName: longhorn-migratable
|
|
||||||
volumeMode: Block
|
|
||||||
source:
|
|
||||||
http:
|
|
||||||
certConfigMap: importer-ca-none
|
|
||||||
url: http://minio.harvester-system:9000/vm-images/image-jxpnq # locally downloaded cirros image
|
|
||||||
running: true
|
|
||||||
template:
|
|
||||||
metadata:
|
|
||||||
annotations:
|
|
||||||
harvester.cattle.io/diskNames: '["cirros-rwx-blk"]'
|
|
||||||
harvester.cattle.io/imageId: default/image-jxpnq
|
|
||||||
labels:
|
|
||||||
harvester.cattle.io/creator: harvester
|
|
||||||
harvester.cattle.io/vmName: cirros-rwx-blk
|
|
||||||
spec:
|
|
||||||
domain:
|
|
||||||
cpu:
|
|
||||||
cores: 1
|
|
||||||
sockets: 1
|
|
||||||
threads: 1
|
|
||||||
devices:
|
|
||||||
disks:
|
|
||||||
- disk:
|
|
||||||
bus: virtio
|
|
||||||
name: disk-0
|
|
||||||
inputs: []
|
|
||||||
interfaces:
|
|
||||||
- masquerade: {}
|
|
||||||
model: virtio
|
|
||||||
name: default
|
|
||||||
machine:
|
|
||||||
type: q35
|
|
||||||
resources:
|
|
||||||
requests:
|
|
||||||
memory: 128M
|
|
||||||
hostname: cirros-rwx-blk
|
|
||||||
networks:
|
|
||||||
- name: default
|
|
||||||
pod: {}
|
|
||||||
volumes:
|
|
||||||
- dataVolume:
|
|
||||||
name: cirros-rwx-blk
|
|
||||||
name: disk-0
|
|
||||||
```
|
|
||||||
|
|
||||||
Once the `cirros-rwx` virtual machine is up and running deploy the `cirros-rwx-migration.yaml` to initiate a virtual machine live migration.
|
|
||||||
```yaml
|
|
||||||
apiVersion: kubevirt.io/v1alpha3
|
|
||||||
kind: VirtualMachineInstanceMigration
|
|
||||||
metadata:
|
|
||||||
name: cirros-rwx-blk
|
|
||||||
spec:
|
|
||||||
vmiName: cirros-rwx-blk
|
|
||||||
```
|
|
||||||
|
|
||||||
### API changes
|
|
||||||
- volume detach call now expects a `detachInput { hostId: "" }` if `hostId==""` it will be treated as detach from all nodes same behavior as before.
|
|
||||||
- csi driver now calls volume attach/detach for all volume types: RWO, RWX (NFS), RWX (Migratable).
|
|
||||||
- the api volume-manager now determines, whether attach/detach is necessary and valid instead of the csi driver.
|
|
||||||
|
|
||||||
#### Attach changes
|
|
||||||
1. If a volume is already attached (to the requested node) we will return the current volume.
|
|
||||||
2. If a volume is mode RWO,
|
|
||||||
it will be attached to the requested node,
|
|
||||||
unless it's attached already to a different node.
|
|
||||||
3. If a volume is mode RWX (NFS),
|
|
||||||
it will only be attached when requested in maintenance mode.
|
|
||||||
Since in other cases the volume is controlled by the share-manager.
|
|
||||||
4. If a volume is mode RWX (Migratable),
|
|
||||||
will initially be attached to the requested node unless already attached,
|
|
||||||
at which point a migration will be initiated to the new node.
|
|
||||||
|
|
||||||
|
|
||||||
#### Detach changes
|
|
||||||
1. If a volume is already detached (from all, from the requested node) we will return the current volume.
|
|
||||||
2. If a volume is mode RWO,
|
|
||||||
It will be detached from the requested node.
|
|
||||||
3. If a volume is mode RWX (NFS),
|
|
||||||
it will only be detached if it's currently attached in maintenance mode.
|
|
||||||
Since in other cases the volume is controlled by the share-manager.
|
|
||||||
4. If a volume is mode RWX (Migratable)
|
|
||||||
It will be detached from the requested node.
|
|
||||||
if a migration is in progress then depending on the requested node to detach different migration actions will happen.
|
|
||||||
A migration confirmation will be triggered if the detach request is for the first node.
|
|
||||||
A migration rollback will be triggered if the detach request is for the second node.
|
|
||||||
|
|
||||||
## Design
|
|
||||||
|
|
||||||
### Implementation Overview
|
|
||||||
|
|
||||||
#### Volume migration flow
|
|
||||||
The live migration intention is triggered and evaluated via the attach/detach calls.
|
|
||||||
The expectation is that Kubernetes will bring up a new pod that requests attachment of the already attached volume.
|
|
||||||
This will initiate the migration start, after this there are two things that can happen.
|
|
||||||
Either Kubernetes will terminate the new pod which is equivalent to a migration rollback, or
|
|
||||||
the old pod will be terminated which is equivalent to a migration complete operation.
|
|
||||||
|
|
||||||
1. Users launch a new VM with a new migratable Longhorn volume ->
|
|
||||||
A migratable volume is created then attached to node1.
|
|
||||||
Similar to regular attachment, Longhorn will set `v.spec.nodeID` to `node1` here.
|
|
||||||
2. Users launch the 2nd VM (pod) with the same Longhorn volume ->
|
|
||||||
1. Kubernetes requests that the volume (already attached) be attached to node2.
|
|
||||||
Then Longhorn receives the attach call and set `v.spec.migrationNodeID` to `node2` with `v.spec.nodeID = node1`.
|
|
||||||
2. Longhorn volume-controller brings up the new engine on node2, with inactive matching replicas (same as live engine upgrade)
|
|
||||||
3. Longhorn CSI driver polls for the existence of the second engine on node2 before acknowledging attachment success.
|
|
||||||
3. Once the migration is started (running engines on both nodes),
|
|
||||||
the following detach decides whether migration is completed successfully,
|
|
||||||
or a migration rollback is desired:
|
|
||||||
1. If succeeded: Kubevirt will remove the original pod on `node1`,
|
|
||||||
this will lead to requesting detachment from node1, which will lead to longhorn setting
|
|
||||||
`v.spec.nodeID` to `node2` and unsetting `v.spec.migrationNodeID`
|
|
||||||
2. If failed: Kubevirt will terminate the new pod on `node2`,
|
|
||||||
this will lead to requesting detachment from node2, which will lead to longhorn keeping
|
|
||||||
`v.spec.nodeID` to `node1` and unsetting `v.spec.migrationNodeID`
|
|
||||||
4. Longhorn volume controller then cleans up the second engine and switches the active replicas to be the current engine ones.
|
|
||||||
|
|
||||||
In summary:
|
|
||||||
```
|
|
||||||
n1 | vm1 has the volume attached (v.spec.nodeID = n1)
|
|
||||||
n2 | vm2 requests attachment [migrationStart] -> (v.spec.migrationNodeID = n2)
|
|
||||||
volume-controller brings up new engine on n2, with inactive matching replicas (same as live engine upgrade)
|
|
||||||
csi driver polls for existence of second engine on n2 before acknowledging attach
|
|
||||||
|
|
||||||
The following detach decides whether a migration is completed successfully, or a migration rollback is desired.
|
|
||||||
n1 | vm1 requests detach of n1 [migrationComplete] -> (v.spec.nodeID = n2, v.spec.migrationNodeID = "")
|
|
||||||
n2 | vm2 requests detach of n2 [migrationRollback] -> (v.spec.NodeID = n1, v.spec.migrationNodeID = "")
|
|
||||||
The volume controller then cleans up the second engine and switches the active replicas to be the current engine ones.
|
|
||||||
```
|
|
||||||
|
|
||||||
### Test plan
|
|
||||||
|
|
||||||
#### E2E tests
|
|
||||||
- E2E test for migration successful
|
|
||||||
- E2E test for migration rollback
|
|
||||||
|
|
||||||
### Upgrade strategy
|
|
||||||
Requires using a storage class with `migratable: "true"` parameter for the harvester volumes
|
|
||||||
as well as an RWX PVC to allow live migration in Kubernetes/Kubevirt.
|
|
||||||
|
|
||||||
@ -1,396 +0,0 @@
|
|||||||
# Automatic Replica Rebalance
|
|
||||||
|
|
||||||
Have a setting for global and volume-specific settings to enable/disable automatic distribution of the off-balanced replicas when a node is newly available to the cluster.
|
|
||||||
|
|
||||||
## Summary
|
|
||||||
|
|
||||||
When nodes are offline with setting `Replica Zone Level Soft Anti-Affinity` enabled, or `Replica Node Level Soft Anti-Affinity` enabled, the replicas could be duplicated and retained on the same zone/node if the remain cluster zone/node number is less than the replica number.
|
|
||||||
|
|
||||||
Currently, the user needs to be aware when nodes are offline and a new node is added back to the cluster to manually delete the replicas to rebalance onto the newly available node.
|
|
||||||
|
|
||||||
This enhancement proposes is to add a new Longhorn global setting `Replica Auto Balance` to enable detection and deletion of the unbalanced replica to achieve automatic rebalancing. And this enhancement also proposes to add a new setting in volume spec `replicaAutoBalance` to enable/disable automatic replica rebalancing for individual volume.
|
|
||||||
|
|
||||||
### Related Issues
|
|
||||||
|
|
||||||
- https://github.com/longhorn/longhorn/issues/587
|
|
||||||
- https://github.com/longhorn/longhorn/issues/570
|
|
||||||
|
|
||||||
## Motivation
|
|
||||||
|
|
||||||
### Goals
|
|
||||||
|
|
||||||
- Support global replica automatic balancing.
|
|
||||||
- Support individual volume replica automatic balancing.
|
|
||||||
|
|
||||||
### Non-goals [optional]
|
|
||||||
[Clean up old Data after node failure](https://github.com/longhorn/longhorn/issues/685#issuecomment-817121946).
|
|
||||||
|
|
||||||
## Proposal
|
|
||||||
|
|
||||||
Add a new global setting `Replica Auto Balance` to enable replica automatic balancing when a node is newly available to the cluster.
|
|
||||||
|
|
||||||
Add a new setting in volume spec `replicaAutoBalance` to enable/disable automatic replica rebalancing for individual volume.
|
|
||||||
|
|
||||||
### User Stories
|
|
||||||
|
|
||||||
Before this enhancement, the user needs to check and manually delete replicas to have deleted replicas reschedule to newly available nodes. If the user does not take action, this could lead to no redundancy volumes.
|
|
||||||
|
|
||||||
After this enhancement, the user does not need to worry about manually balancing replicas when there are newly available nodes.
|
|
||||||
|
|
||||||
#### Story 1 - node temporary offline
|
|
||||||
As a system administrator,
|
|
||||||
|
|
||||||
When a cluster node is offline and comes back online after some time, I want Longhorn to automatically detect and reschedule replicas evenly to all nodes.
|
|
||||||
|
|
||||||
So I do not have to worry and standby 24/7 to check and manually rebalance replicas when there are newly available nodes.
|
|
||||||
|
|
||||||
#### Story 2 - add new node
|
|
||||||
|
|
||||||
As a system administrator,
|
|
||||||
|
|
||||||
When a cluster node is offline and a new node is added, I want Longhorn to automatically detect and reschedule replicas evenly to all nodes
|
|
||||||
|
|
||||||
So I do not have to worry and standby 24/7 to check and manually rebalance replicas when there are newly available nodes.
|
|
||||||
|
|
||||||
#### Story 3 - zone temporary offline
|
|
||||||
|
|
||||||
As a system administrator,
|
|
||||||
|
|
||||||
When a cluster zone is offline and comes back online after some time, I want Longhorn to automatically detect and reschedule replicas evenly across zones.
|
|
||||||
|
|
||||||
So I do not have to worry and standby 24/7 to check and manually rebalance replicas when there are newly available nodes.
|
|
||||||
|
|
||||||
#### Story 4 - replica automatic rebalance for individual volume
|
|
||||||
|
|
||||||
As a system administrator,
|
|
||||||
|
|
||||||
When a cluster node is offline and a new node is added, I want Longhorn to automatically detect and reschedule replicas evenly to some volumes only.
|
|
||||||
|
|
||||||
So I do not have to worry and standby 24/7 to check and manually rebalance replicas when there are newly available nodes.
|
|
||||||
|
|
||||||
#### Story 5 - replica automatic rebalance for minimal redundancy
|
|
||||||
|
|
||||||
As a system administrator,
|
|
||||||
|
|
||||||
When multiple cluster node are offline and a new node is added, I want have an option to have Longhorn to automatically detect and reschedule only 1 replica to the new node to achieve minimal redundancy.
|
|
||||||
|
|
||||||
So I do not have to worry about over resource consumption during rebalancing and I do not have to worry and standby 24/7 to check and manually rebalance replicas when there are newly available nodes.
|
|
||||||
|
|
||||||
#### Story 6 - replica automatic rebalance for even redundancy
|
|
||||||
|
|
||||||
As a system administrator,
|
|
||||||
|
|
||||||
When multiple cluster node are offline and a new node is added, I want have an option to have Longhorn to automatically detect and reschedule replica to the new node to achieve even replica number redundancy.
|
|
||||||
|
|
||||||
So I do not end up with uneven number of replicas across cluster nodes and I do not have to worry and standby 24/7 to check and manually rebalance replicas when there are newly available nodes.
|
|
||||||
|
|
||||||
### User Experience In Detail
|
|
||||||
|
|
||||||
#### Story 1 - Replica Node Level Unbalanced
|
|
||||||
|
|
||||||
With an example of 3 nodes in cluster and default of 3 replicas volume:
|
|
||||||
1. When the user enables `replica-soft-anti-affinity` and deploys PVC and Pod on node-1. The replica is distributed evenly to all 3 nodes at this point.
|
|
||||||
2. In case of node-2 is offline, the user will see replica was on node-2 gets re-scheduled to node-1 or node-3. And also a warning icon and note will appear on UI `Limited node redundancy: at least one healthy replica is running at the same node as another`.
|
|
||||||
|
|
||||||
**Before enhancement**
|
|
||||||
3. Bring node-2 online, no change will be done automatically by Longhorn. The user will still see the same warning on UI.
|
|
||||||
4. To rebalance replicas, the user needs to find and delete the duplicated replica to trigger the schedule onto node-2.
|
|
||||||
|
|
||||||
**After enhancement**
|
|
||||||
3. Longhorn automatically detects and deletes the duplicated replica so the replica will be scheduled onto node-2. User will see the duplicated replica get rescheduled back to node-2 and UI will see volume `Healthy` with the note `Limited node redundancy: at least one healthy replica is running at the same node as another` removed.
|
|
||||||
|
|
||||||
#### Story 2 - Replica Zone Level Unbalanced
|
|
||||||
|
|
||||||
With an example of cluster set for 2 zones and default of 2 replicas volume:
|
|
||||||
1. When the user enables `replica-soft-anti-affinity` and `replica-zone-soft-anti-affinity` and deploys PVC and deployment. The replica is distributed evenly to all 2 zones at this point.
|
|
||||||
2. In case of zone-2 is offline, the user will see replica was on zone-2 gets re-scheduled to zone-1.
|
|
||||||
|
|
||||||
**Before enhancement**
|
|
||||||
3. Bring zone-2 online, no change will be done automatically by Longhorn. The user will still see replicas all running in zone-1.
|
|
||||||
4. To rebalance replicas, the user needs to find and delete the duplicated replica to trigger the schedule to zone-2.
|
|
||||||
|
|
||||||
**After enhancement**
|
|
||||||
3. Longhorn automatically detects and deletes the duplicated replica so the replica will be scheduled to zone-2. The user will see the duplicated replica get rescheduled back to zone-2.
|
|
||||||
|
|
||||||
### API changes
|
|
||||||
- The new global setting `Replica Auto Balance` will use the same /v1/settings API.
|
|
||||||
- When creating a new volume, the body of the request sent to /v1/volumes has a new field `replicaAutoBalance` set to `ignored`, `disabled`, `least-effort`, or `best-effort`.
|
|
||||||
- Implement a new API for users to update `replicaAutoBalance` setting for individual volume. The new API could be /v1/volumes/<VOLUME_NAME>?action=updateReplicaAutoBalance. This API expects the request's body to have the form {replicaAutoBalance:<options>}.
|
|
||||||
|
|
||||||
## Design
|
|
||||||
|
|
||||||
### Implementation Overview
|
|
||||||
|
|
||||||
#### longhorn-manager
|
|
||||||
- Add new global setting `Replica Auto Balance`.
|
|
||||||
- The setting is `string`.
|
|
||||||
- Available values are: `disabled`, `least-effort`, `best-effort`.
|
|
||||||
- `disabled`: no replica auto balance will be done.
|
|
||||||
- `least-effort`: replica will be balanced to achieve minimal redundancy. For example, after adding node-2, a volume with 4 off-balanced replicas will only rebalance 1 replicas.
|
|
||||||
```
|
|
||||||
node-1
|
|
||||||
+-- replica-a
|
|
||||||
+-- replica-b
|
|
||||||
+-- replica-c
|
|
||||||
node-2
|
|
||||||
+-- replica-d
|
|
||||||
```
|
|
||||||
- `best-effort`: replica will be balanced to achieve similar number of replicas redundancy. For example, after adding node-2, a volume with 4 off-balanced replicas will rebalance 2 replicas.
|
|
||||||
```
|
|
||||||
node-1
|
|
||||||
+-- replica-a
|
|
||||||
+-- replica-b
|
|
||||||
node-2
|
|
||||||
+-- replica-c
|
|
||||||
+-- replica-d
|
|
||||||
```
|
|
||||||
- The default value is `disabled`.
|
|
||||||
|
|
||||||
- Add new volume spec `replicaAutoBalance`.
|
|
||||||
- Available values are: `ignored`, `disabled`, `least-effort`, `best-effort`.
|
|
||||||
- `ignored`: This will adopt to the value from global setting.
|
|
||||||
- `disabled`: Same as global setting value `disabled`.
|
|
||||||
- `least-effort`: Same as global setting value `least-effort`.
|
|
||||||
- `best-effort`: Same as global setting value `best-effort`.
|
|
||||||
- The default value is `ignored`.
|
|
||||||
|
|
||||||
- In Volume Controller `syncVolume` -> `ReconcileEngineReplicaState` -> `replenishReplicas`, calculate and add number of replicas to be rebalanced to `replenishCount`.
|
|
||||||
> The logic ignores all `soft-anti-affinity` settings. This will always try to achieve zone balance then node balance. And creating for replicas will leave for ReplicaScheduler to determine for the candidates.
|
|
||||||
1. Skip volume replica rebalance when volume spec `replicaAutoBalance` is `disabled`.
|
|
||||||
2. Skip if volume `Robustness` is not `healthy`.
|
|
||||||
3. For `least-effort`, try to get the replica rebalance count.
|
|
||||||
1. For `zone` duplicates, get the replenish number.
|
|
||||||
1. List all the occupied node zones with volume replicas running.
|
|
||||||
- The zone is balanced when this is equal to volume spec `NumberOfReplicas`.
|
|
||||||
2. List all available and schedulable nodes in non-occupied zones.
|
|
||||||
- The zone is balanced when no available nodes are found.
|
|
||||||
3. Get the number of replicas off-balanced:
|
|
||||||
- number of replicas in volume spec - number of occupied node zones.
|
|
||||||
4. Return the number to replenish.
|
|
||||||
- number of non-occupied zones if less than off-balanced, or
|
|
||||||
- number off-balanced.
|
|
||||||
2. For `node` duplicates, try to balance `zone` first. Get the replica replenish number.
|
|
||||||
1. List all occupied node IDs with volume replicas running.
|
|
||||||
- The node is balanced when this is equal to volume spec `NumberOfReplicas`.
|
|
||||||
2. List all available and schedulable nodes.
|
|
||||||
- The nodes is balanced when number of occupied nodes equal to the number of nodes. This is to determine if balanced when the number of nodes is less then the volume spec `NumberOfReplicas`.
|
|
||||||
3. Get the number of replicas off-balanced:
|
|
||||||
- number of replicas in volume spec - number of occupied node IDs.
|
|
||||||
4. Return the number to replenish.
|
|
||||||
- number of non-occupied nodes if less than off-balanced, or
|
|
||||||
- number off-balanced.
|
|
||||||
4. For `best-effort`, try `least-effort` first to achieve minimal redundancy, then,
|
|
||||||
1. Try to get zone duplicates mapped by zoneID, continue to find duplicates on nodes if no duplicated found here.
|
|
||||||
2. Try to get node duplicates mapped by nodeID.
|
|
||||||
3. Return number to replenish when maximum replica names in duplicates mapping is 2 greater than the minimum replica names in duplicates mapping.
|
|
||||||
5. Add the number to rebalance to `replenishCount` in `replenishReplicas`.
|
|
||||||
|
|
||||||
- Cleanup extra replicas for auto-balance in `cleanupExtraHealthyReplicas`.
|
|
||||||
1. Get replica names.
|
|
||||||
- For `best-effort`, use the replica names from duplicates in the most duplicated zones/nodes.
|
|
||||||
- For `least-effort`, use the replicas names from `getPreferredReplicaCandidatesForDeletion`.
|
|
||||||
3. Delete one replicas from the replica names.
|
|
||||||
|
|
||||||
|
|
||||||
### Test plan
|
|
||||||
|
|
||||||
#### Integration tests - test_replica_auto_balance_node_least_effort
|
|
||||||
|
|
||||||
Scenario: replica auto-balance nodes with `least_effort`.
|
|
||||||
|
|
||||||
Given set `replica-soft-anti-affinity` to `true`.
|
|
||||||
And set `replica-auto-balance` to `least_effort`.
|
|
||||||
And create a volume with 6 replicas.
|
|
||||||
And attach the volume to node-1.
|
|
||||||
And wait for the volume to be healthy.
|
|
||||||
And write some data to the volume.
|
|
||||||
And disable scheduling for node-2.
|
|
||||||
disable scheduling for node-3.
|
|
||||||
And And count replicas running on each nodes.
|
|
||||||
And 6 replicas running on node-1.
|
|
||||||
0 replicas running on node-2.
|
|
||||||
0 replicas running on node-3.
|
|
||||||
|
|
||||||
When enable scheduling for node-2.
|
|
||||||
Then count replicas running on each nodes.
|
|
||||||
And node-1 replica count != node-2 replica count.
|
|
||||||
node-2 replica count != 0.
|
|
||||||
node-3 replica count == 0.
|
|
||||||
And sleep 10 seconds, to ensure no addition scheduling is happening.
|
|
||||||
And count replicas running on each nodes.
|
|
||||||
And number of replicas running should be the same.
|
|
||||||
|
|
||||||
When enable scheduling for node-3.
|
|
||||||
And count replicas running on each nodes.
|
|
||||||
And node-1 replica count != node-3 replica count.
|
|
||||||
node-2 replica count != 0.
|
|
||||||
node-3 replica count != 0.
|
|
||||||
And sleep 10 seconds, to ensure no addition scheduling is happening.
|
|
||||||
And count replicas running on each nodes.
|
|
||||||
And number of replicas running should be the same.
|
|
||||||
|
|
||||||
When check the volume data.
|
|
||||||
And volume data should be the same as written.
|
|
||||||
|
|
||||||
#### Integration tests - test_replica_auto_balance_node_best_effort
|
|
||||||
|
|
||||||
Scenario: replica auto-balance nodes with `best_effort`.
|
|
||||||
|
|
||||||
Given set `replica-soft-anti-affinity` to `true`.
|
|
||||||
And set `replica-auto-balance` to `best_effort`.
|
|
||||||
And create a volume with 6 replicas.
|
|
||||||
And attach the volume to node-1.
|
|
||||||
And wait for the volume to be healthy.
|
|
||||||
And write some data to the volume.
|
|
||||||
And disable scheduling for node-2.
|
|
||||||
disable scheduling for node-3.
|
|
||||||
And And count replicas running on each node.
|
|
||||||
And 6 replicas running on node-1.
|
|
||||||
0 replicas running on node-2.
|
|
||||||
0 replicas running on node-3.
|
|
||||||
|
|
||||||
When enable scheduling for node-2.
|
|
||||||
And count replicas running on each node.
|
|
||||||
Then 3 replicas running on node-1.
|
|
||||||
3 replicas running on node-2.
|
|
||||||
0 replicas running on node-3.
|
|
||||||
And sleep 10 seconds, to ensure no addition scheduling is happening.
|
|
||||||
And count replicas running on each node.
|
|
||||||
And 3 replicas running on node-1.
|
|
||||||
3 replicas running on node-2.
|
|
||||||
0 replicas running on node-3.
|
|
||||||
|
|
||||||
When enable scheduling for node-3.
|
|
||||||
And count replicas running on each node.
|
|
||||||
Then 2 replicas running on node-1.
|
|
||||||
2 replicas running on node-2.
|
|
||||||
2 replicas running on node-3.
|
|
||||||
And sleep 10 seconds, to ensure no addition scheduling is happening.
|
|
||||||
And count replicas running on each node.
|
|
||||||
And 2 replicas running on node-1.
|
|
||||||
2 replicas running on node-2.
|
|
||||||
2 replicas running on node-3.
|
|
||||||
|
|
||||||
When check the volume data.
|
|
||||||
And volume data should be the same as written.
|
|
||||||
|
|
||||||
#### Integration tests - test_replica_auto_balance_disabled_volume_spec_enabled
|
|
||||||
|
|
||||||
Scenario: replica should auto-balance individual volume when global setting `replica-auto-balance` is `disabled` and volume spec `replicaAutoBalance` is `least_effort`.
|
|
||||||
|
|
||||||
Given set `replica-soft-anti-affinity` to `true`.
|
|
||||||
And set `replica-auto-balance` to `least_effort`.
|
|
||||||
And disable scheduling for node-2.
|
|
||||||
disable scheduling for node-3.
|
|
||||||
And create volume-1 with 3 replicas.
|
|
||||||
create volume-2 with 3 replicas.
|
|
||||||
And set volume-2 spec `replicaAutoBalance` to `least-effort`.
|
|
||||||
And attach volume-1 to node-1.
|
|
||||||
attach volume-2 to node-1.
|
|
||||||
And wait for volume-1 to be healthy.
|
|
||||||
wait for volume-2 to be healthy.
|
|
||||||
And volume-1 replicas should be running on node-1.
|
|
||||||
volume-2 replicas should be running on node-1.
|
|
||||||
And write some data to volume-1.
|
|
||||||
write some data to volume-2.
|
|
||||||
|
|
||||||
When enable scheduling for node-2.
|
|
||||||
enable scheduling for node-3.
|
|
||||||
And count replicas running on each nodes for volume-1.
|
|
||||||
count replicas running on each nodes for volume-2.
|
|
||||||
|
|
||||||
Then volume-1 replicas should be running on node-1.
|
|
||||||
And volume-1 should have 3 replicas running.
|
|
||||||
And volume-2 replicas should be running on node-1, node-2, node-3.
|
|
||||||
And volume-2 should have 3 replicas running.
|
|
||||||
And volume-1 data should be the same as written.
|
|
||||||
And volume-2 data should be the same as written.
|
|
||||||
|
|
||||||
#### Integration tests - test_replica_auto_balance_zone_least_effort
|
|
||||||
|
|
||||||
Scenario: replica auto-balance zones with least-effort.
|
|
||||||
|
|
||||||
Given set `replica-soft-anti-affinity` to `true`.
|
|
||||||
And set `replica-zone-soft-anti-affinity` to `true`.
|
|
||||||
And set volume spec `replicaAutoBalance` to `least-effort`.
|
|
||||||
And set node-1 to zone-1.
|
|
||||||
set node-2 to zone-2.
|
|
||||||
set node-3 to zone-3.
|
|
||||||
And disable scheduling for node-2.
|
|
||||||
disable scheduling for node-3.
|
|
||||||
And create a volume with 6 replicas.
|
|
||||||
And attach the volume to node-1.
|
|
||||||
And 6 replicas running in zone-1.
|
|
||||||
0 replicas running in zone-2.
|
|
||||||
0 replicas running in zone-3.
|
|
||||||
|
|
||||||
When enable scheduling for node-2.
|
|
||||||
And count replicas running on each node.
|
|
||||||
And zone-1 replica count != zone-2 replica count.
|
|
||||||
zone-2 replica count != 0.
|
|
||||||
zone-3 replica count == 0.
|
|
||||||
|
|
||||||
When enable scheduling for node-3.
|
|
||||||
And count replicas running on each node.
|
|
||||||
And zone-1 replica count != zone-3 replica count.
|
|
||||||
zone-2 replica count != 0.
|
|
||||||
zone-3 replica count != 0.
|
|
||||||
|
|
||||||
#### Integration tests - test_replica_auto_balance_zone_best_effort
|
|
||||||
|
|
||||||
Scenario: replica auto-balance zones with best-effort.
|
|
||||||
|
|
||||||
Given set `replica-soft-anti-affinity` to `true`.
|
|
||||||
And set `replica-zone-soft-anti-affinity` to `true`.
|
|
||||||
And set volume spec `replicaAutoBalance` to `best-effort`.
|
|
||||||
And set node-1 to zone-1.
|
|
||||||
set node-2 to zone-2.
|
|
||||||
set node-3 to zone-3.
|
|
||||||
And disable scheduling for node-2.
|
|
||||||
disable scheduling for node-3.
|
|
||||||
And create a volume with 6 replicas.
|
|
||||||
And attach the volume to node-1.
|
|
||||||
And 6 replicas running in zone-1.
|
|
||||||
0 replicas running in zone-2.
|
|
||||||
0 replicas running in zone-3.
|
|
||||||
|
|
||||||
When enable scheduling for node-2.
|
|
||||||
And count replicas running on each node.
|
|
||||||
And 3 replicas running in zone-1.
|
|
||||||
3 replicas running in zone-2.
|
|
||||||
0 replicas running in zone-3.
|
|
||||||
|
|
||||||
When enable scheduling for node-3.
|
|
||||||
And count replicas running on each node.
|
|
||||||
And 2 replicas running in zone-1.
|
|
||||||
2 replicas running in zone-2.
|
|
||||||
2 replicas running in zone-3.
|
|
||||||
|
|
||||||
#### Integration tests - test_replica_auto_balance_node_duplicates_in_multiple_zones
|
|
||||||
|
|
||||||
Scenario: replica auto-balance to nodes with duplicated replicas in the zone.
|
|
||||||
|
|
||||||
Given set `replica-soft-anti-affinity` to `true`.
|
|
||||||
And set `replica-zone-soft-anti-affinity` to `true`.
|
|
||||||
And set volume spec `replicaAutoBalance` to `least-effort`.
|
|
||||||
And set node-1 to zone-1.
|
|
||||||
set node-2 to zone-2.
|
|
||||||
And disable scheduling for node-3.
|
|
||||||
And create a volume with 3 replicas.
|
|
||||||
And attach the volume to node-1.
|
|
||||||
And zone-1 and zone-2 should contain 3 replica in total.
|
|
||||||
|
|
||||||
When set node-3 to the zone with duplicated replicas.
|
|
||||||
And enable scheduling for node-3.
|
|
||||||
Then count replicas running on each node.
|
|
||||||
And 1 replica running on node-1
|
|
||||||
1 replica running on node-2
|
|
||||||
1 replica running on node-3.
|
|
||||||
And count replicas running in each zone.
|
|
||||||
And total of 3 replicas running in zone-1 and zone-2.
|
|
||||||
|
|
||||||
### Upgrade strategy
|
|
||||||
There is no upgrade needed.
|
|
||||||
|
|
||||||
## Note [optional]
|
|
||||||
`None`
|
|
||||||
@ -1,476 +0,0 @@
|
|||||||
# Async Pull/Push Backups From/To The Remote Backup Target
|
|
||||||
|
|
||||||
## Summary
|
|
||||||
|
|
||||||
Currently, Longhorn uses a blocking way for communication with the remote backup target, so there will be some potential voluntary or involuntary factors (ex: network latency) impacting the functions relying on remote backup target like listing backups or even causing further [cascading problems](###related-issues) after the backup target operation.
|
|
||||||
|
|
||||||
This enhancement is to propose an asynchronous way to pull backup volumes and backups from the remote backup target (S3/NFS) then persistently saved via cluster custom resources.
|
|
||||||
|
|
||||||
This can resolve the problems above mentioned by asynchronously querying the list of backup volumes and backups from the remote backup target for final consistent available results. It's also scalable for the costly resources created by the original blocking query operations.
|
|
||||||
|
|
||||||
### Related Issues
|
|
||||||
|
|
||||||
- https://github.com/longhorn/longhorn/issues/1761
|
|
||||||
- https://github.com/longhorn/longhorn/issues/1955
|
|
||||||
- https://github.com/longhorn/longhorn/issues/2536
|
|
||||||
- https://github.com/longhorn/longhorn/issues/2543
|
|
||||||
|
|
||||||
## Motivation
|
|
||||||
|
|
||||||
### Goals
|
|
||||||
|
|
||||||
Decrease the query latency when listing backup volumes _or_ backups in the circumstances like lots of backup volumes, lots of backups, or the network latency between the Longhorn cluster and the remote backup target.
|
|
||||||
|
|
||||||
### Non-goals
|
|
||||||
|
|
||||||
- Automatically adjust the backup target poll interval.
|
|
||||||
- Supports multiple backup targets.
|
|
||||||
- Supports API pagination for listing backup volumes and backups.
|
|
||||||
|
|
||||||
## Proposal
|
|
||||||
|
|
||||||
1. Change the [longhorn/backupstore](https://github.com/longhorn/backupstore) _list_ command behavior, and add _inspect-volume_ and _head_ command.
|
|
||||||
- The `backup list` command includes listing all backup volumes and the backups and read these config.
|
|
||||||
We'll change the `backup list` behavior to perform list only, but not read the config.
|
|
||||||
- Add a new `backup inspect-volume` command to support read backup volume config.
|
|
||||||
- Add a new `backup head` command to support get config metadata.
|
|
||||||
2. Create a BackupTarget CRD _backuptargets.longhorn.io_ to save the backup target URL, credential secret, and poll interval.
|
|
||||||
3. Create a BackupVolume CRD _backupvolumes.longhorn.io_ to save to backup volume config.
|
|
||||||
4. Create a Backup CRD _backups.longhorn.io_ to save the backup config.
|
|
||||||
5. At the existed `setting_controller`, which is responsible creating/updating the default BackupTarget CR with settings `backup-target`, `backup-target-credential-secret`, and `backupstore-poll-interval`.
|
|
||||||
6. Create a new controller `backup_target_controller`, which is responsible for creating/deleting the BackupVolume CR.
|
|
||||||
7. Create a new controller `backup_volume_controller`, which is responsible:
|
|
||||||
1. deleting Backup CR and deleting backup volume from remote backup target if delete BackupVolume CR event comes in.
|
|
||||||
2. updating BackupVolume CR status.
|
|
||||||
3. creating/deleting Backup CR.
|
|
||||||
8. Create a new controller `backup_controller`, which is responsible:
|
|
||||||
1. deleting backup from remote backup target if delete Backup CR event comes in.
|
|
||||||
2. calling longhorn engine/replica to perform snapshot backup to the remote backup target.
|
|
||||||
3. updating the Backup CR status, and deleting backup from the remote backup target.
|
|
||||||
9. The HTTP endpoints CRUD methods related to backup volume and backup will interact with BackupVolume CR and Backup CR instead interact with the remote backup target.
|
|
||||||
|
|
||||||
### User Stories
|
|
||||||
|
|
||||||
Before this enhancement, when the user's environment under the circumstances that the remote backup target has lots of backup volumes _or_ backups, and the latency between the longhorn manager to the remote backup target is high.
|
|
||||||
Then when the user clicks the `Backup` on the GUI, the user might hit list backup volumes _or_ list backups timeout issue (the default timeout is 1 minute).
|
|
||||||
|
|
||||||
We choose to not create a new setting for the user to increase the list timeout value is because the browser has its timeout value also.
|
|
||||||
Let's say the list backups needs 5 minutes to finish. Even we allow the user to increase the longhorn manager list timeout value, we can't change the browser default timeout value. Furthermore, some browser doesn't allow the user to change default timeout value like Google Chrome.
|
|
||||||
|
|
||||||
After this enhancement, when the user's environment under the circumstances that the remote backup target has lots of backup volumes _or_ backups, and the latency between the longhorn manager to the remote backup target is high.
|
|
||||||
Then when the user clicks the `Backup` on the GUI, the user can eventually list backup volumes _or_ list backups without a timeout issue.
|
|
||||||
|
|
||||||
#### Story 1
|
|
||||||
|
|
||||||
The user environment is under the circumstances that the remote backup target has lots of backup volumes and the latency between the longhorn manager to the remote backup target is high. Then, the user can list all backup volumes on the GUI.
|
|
||||||
|
|
||||||
#### Story 2
|
|
||||||
|
|
||||||
The user environment is under the circumstances that the remote backup target has lots of backups and the latency between the longhorn manager to the remote backup target is high. Then, the user can list all backups on the GUI.
|
|
||||||
|
|
||||||
#### Story 3
|
|
||||||
|
|
||||||
The user creates a backup on the Longhorn GUI. Now the backup will create a Backup CR, then the backup_controller reconciles it to call Longhorn engine/replica to perform a backup to the remote backup target.
|
|
||||||
|
|
||||||
### User Experience In Detail
|
|
||||||
|
|
||||||
None.
|
|
||||||
|
|
||||||
### API changes
|
|
||||||
|
|
||||||
1. For [longhorn/backupstore](https://github.com/longhorn/backupstore)
|
|
||||||
|
|
||||||
The current [longhorn/backupstore](https://github.com/longhorn/backupstore) list and inspect command behavior are:
|
|
||||||
- `backup ls --volume-only`: List all backup volumes and read it's config (`volume.cfg`). For example:
|
|
||||||
```json
|
|
||||||
$ backup ls s3://backupbucket@minio/ --volume-only
|
|
||||||
{
|
|
||||||
"pvc-004d8edb-3a8c-4596-a659-3d00122d3f07": {
|
|
||||||
"Name": "pvc-004d8edb-3a8c-4596-a659-3d00122d3f07",
|
|
||||||
"Size": "2147483648",
|
|
||||||
"Labels": {},
|
|
||||||
"Created": "2021-05-12T00:52:01Z",
|
|
||||||
"LastBackupName": "backup-c5f548b7e86b4b56",
|
|
||||||
"LastBackupAt": "2021-05-17T05:31:01Z",
|
|
||||||
"DataStored": "121634816",
|
|
||||||
"Messages": {}
|
|
||||||
},
|
|
||||||
"pvc-7a8ded68-862d-4abb-a08c-8cf9664dab10": {
|
|
||||||
"Name": "pvc-7a8ded68-862d-4abb-a08c-8cf9664dab10",
|
|
||||||
"Size": "10737418240",
|
|
||||||
"Labels": {},
|
|
||||||
"Created": "2021-05-10T02:43:02Z",
|
|
||||||
"LastBackupName": "backup-432f4d6afa31481f",
|
|
||||||
"LastBackupAt": "2021-05-10T06:04:02Z",
|
|
||||||
"DataStored": "140509184",
|
|
||||||
"Messages": {}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
- `backup ls --volume <volume-name>`: List all backups and read it's config (`backup_backup_<backup-hash>.cfg`). For example:
|
|
||||||
```json
|
|
||||||
$ backup ls s3://backupbucket@minio/ --volume pvc-004d8edb-3a8c-4596-a659-3d00122d3f07
|
|
||||||
{
|
|
||||||
"pvc-004d8edb-3a8c-4596-a659-3d00122d3f07": {
|
|
||||||
"Name": "pvc-004d8edb-3a8c-4596-a659-3d00122d3f07",
|
|
||||||
"Size": "2147483648",
|
|
||||||
"Labels": {},
|
|
||||||
"Created": "2021-05-12T00:52:01Z",
|
|
||||||
"LastBackupName": "backup-c5f548b7e86b4b56",
|
|
||||||
"LastBackupAt": "2021-05-17T05:31:01Z",
|
|
||||||
"DataStored": "121634816",
|
|
||||||
"Messages": {},
|
|
||||||
"Backups": {
|
|
||||||
"s3://backupbucket@minio/?backup=backup-02224cb26b794e73\u0026volume=pvc-004d8edb-3a8c-4596-a659-3d00122d3f07": {
|
|
||||||
"Name": "backup-02224cb26b794e73",
|
|
||||||
"URL": "s3://backupbucket@minio/?backup=backup-02224cb26b794e73\u0026volume=pvc-004d8edb-3a8c-4596-a659-3d00122d3f07",
|
|
||||||
"SnapshotName": "backup-23c4fd9a",
|
|
||||||
"SnapshotCreated": "2021-05-17T05:23:01Z",
|
|
||||||
"Created": "2021-05-17T05:23:04Z",
|
|
||||||
"Size": "115343360",
|
|
||||||
"Labels": {},
|
|
||||||
"IsIncremental": true,
|
|
||||||
"Messages": null
|
|
||||||
},
|
|
||||||
...
|
|
||||||
"s3://backupbucket@minio/?backup=backup-fa78d89827664840\u0026volume=pvc-004d8edb-3a8c-4596-a659-3d00122d3f07": {
|
|
||||||
"Name": "backup-fa78d89827664840",
|
|
||||||
"URL": "s3://backupbucket@minio/?backup=backup-fa78d89827664840\u0026volume=pvc-004d8edb-3a8c-4596-a659-3d00122d3f07",
|
|
||||||
"SnapshotName": "backup-ac364071",
|
|
||||||
"SnapshotCreated": "2021-05-17T04:42:01Z",
|
|
||||||
"Created": "2021-05-17T04:42:03Z",
|
|
||||||
"Size": "115343360",
|
|
||||||
"Labels": {},
|
|
||||||
"IsIncremental": true,
|
|
||||||
"Messages": null
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
- `backup inspect <backup>`: Read a single backup config (`backup_backup_<backup-hash>.cfg`). For example:
|
|
||||||
```json
|
|
||||||
$ backup inspect s3://backupbucket@minio/?backup=backup-fa78d89827664840\u0026volume=pvc-004d8edb-3a8c-4596-a659-3d00122d3f07
|
|
||||||
{
|
|
||||||
"Name": "backup-fa78d89827664840",
|
|
||||||
"URL": "s3://backupbucket@minio/?backup=backup-fa78d89827664840\u0026volume=pvc-004d8edb-3a8c-4596-a659-3d00122d3f07",
|
|
||||||
"SnapshotName": "backup-ac364071",
|
|
||||||
"SnapshotCreated": "2021-05-17T04:42:01Z",
|
|
||||||
"Created": "2021-05-17T04:42:03Z",
|
|
||||||
"Size": "115343360",
|
|
||||||
"Labels": {},
|
|
||||||
"IsIncremental": true,
|
|
||||||
"VolumeName": "pvc-004d8edb-3a8c-4596-a659-3d00122d3f07",
|
|
||||||
"VolumeSize": "2147483648",
|
|
||||||
"VolumeCreated": "2021-05-12T00:52:01Z",
|
|
||||||
"Messages": null
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
After this enhancement, the [longhorn/backupstore](https://github.com/longhorn/backupstore) list and inspect command behavior are:
|
|
||||||
- `backup ls --volume-only`: List all backup volume names. For example:
|
|
||||||
```json
|
|
||||||
$ backup ls s3://backupbucket@minio/ --volume-only
|
|
||||||
{
|
|
||||||
"pvc-004d8edb-3a8c-4596-a659-3d00122d3f07": {},
|
|
||||||
"pvc-7a8ded68-862d-4abb-a08c-8cf9664dab10": {}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
- `backup ls --volume <volume-name>`: List all backup names. For example:
|
|
||||||
```json
|
|
||||||
$ backup ls s3://backupbucket@minio/ --volume pvc-004d8edb-3a8c-4596-a659-3d00122d3f07
|
|
||||||
{
|
|
||||||
"pvc-004d8edb-3a8c-4596-a659-3d00122d3f07": {
|
|
||||||
"Backups": {
|
|
||||||
"backup-02224cb26b794e73": {},
|
|
||||||
...
|
|
||||||
"backup-fa78d89827664840": {}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
- `backup inspect-volume <volume>`: Read a single backup volume config (`volume.cfg`). For example:
|
|
||||||
```json
|
|
||||||
$ backup inspect-volume s3://backupbucket@minio/?volume=pvc-004d8edb-3a8c-4596-a659-3d00122d3f07
|
|
||||||
{
|
|
||||||
"Name": "pvc-004d8edb-3a8c-4596-a659-3d00122d3f07",
|
|
||||||
"Size": "2147483648",
|
|
||||||
"Labels": {},
|
|
||||||
"Created": "2021-05-12T00:52:01Z",
|
|
||||||
"LastBackupName": "backup-c5f548b7e86b4b56",
|
|
||||||
"LastBackupAt": "2021-05-17T05:31:01Z",
|
|
||||||
"DataStored": "121634816",
|
|
||||||
"Messages": {}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
- `backup inspect <backup>`: Read a single backup config (`backup_backup_<backup-hash>.cfg`). For example:
|
|
||||||
```json
|
|
||||||
$ backup inspect s3://backupbucket@minio/?backup=backup-fa78d89827664840\u0026volume=pvc-004d8edb-3a8c-4596-a659-3d00122d3f07
|
|
||||||
{
|
|
||||||
"Name": "backup-fa78d89827664840",
|
|
||||||
"URL": "s3://backupbucket@minio/?backup=backup-fa78d89827664840\u0026volume=pvc-004d8edb-3a8c-4596-a659-3d00122d3f07",
|
|
||||||
"SnapshotName": "backup-ac364071",
|
|
||||||
"SnapshotCreated": "2021-05-17T04:42:01Z",
|
|
||||||
"Created": "2021-05-17T04:42:03Z",
|
|
||||||
"Size": "115343360",
|
|
||||||
"Labels": {},
|
|
||||||
"IsIncremental": true,
|
|
||||||
"VolumeName": "pvc-004d8edb-3a8c-4596-a659-3d00122d3f07",
|
|
||||||
"VolumeSize": "2147483648",
|
|
||||||
"VolumeCreated": "2021-05-12T00:52:01Z",
|
|
||||||
"Messages": null
|
|
||||||
}
|
|
||||||
```
|
|
||||||
- `backup head <config>`: Get the config metadata. For example:
|
|
||||||
```json
|
|
||||||
{
|
|
||||||
"ModificationTime": "2021-05-17T04:42:03Z",
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Generally speaking, we want to separate the **list**, **read**, and **head** commands.
|
|
||||||
|
|
||||||
2. The Longhorn manager HTTP endpoints.
|
|
||||||
|
|
||||||
| HTTP Endpoint | Before | After |
|
|
||||||
| ------------------------------------------------------------ | ----------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------- |
|
|
||||||
| **GET** `/v1/backupvolumes` | read all backup volumes from the remote backup target | read all the BackupVolume CRs |
|
|
||||||
| **GET** `/v1/backupvolumes/{volName}` | read a backup volume from the remote backup target | read a BackupVolume CR with the given volume name |
|
|
||||||
| **DELETE** `/v1/backupvolumes/{volName}` | delete a backup volume from the remote backup target | delete the BackupVolume CR with the given volume name, `backup_volume_controller` reconciles to delete a backup volume from the remote backup target |
|
|
||||||
| **POST** `/v1/volumes/{volName}?action=snapshotBackup` | create a backup to the remote backup target | create a new Backup, `backup_controller` reconciles to create a backup to the remote backup target |
|
|
||||||
| **GET** `/v1/backupvolumes/{volName}?action=backupList` | read a list of backups from the remote backup target | read a list of Backup CRs with the label filter `volume=<backup-volume-name>` |
|
|
||||||
| **GET** `/v1/backupvolumes/{volName}?action=backupGet` | read a backup from the remote backup target | read a Backup CR with the given backup name |
|
|
||||||
| **DELETE** `/v1/backupvolumes/{volName}?action=backupDelete` | delete a backup from the remote backup target | delete the Backup CR, `backup_controller` reconciles to delete a backup from reomte backup target |
|
|
||||||
|
|
||||||
## Design
|
|
||||||
|
|
||||||
### Implementation Overview
|
|
||||||
|
|
||||||
1. Create a new BackupTarget CRD `backuptargets.longhorn.io`.
|
|
||||||
|
|
||||||
```yaml
|
|
||||||
metadata:
|
|
||||||
name: the backup target name (`default`), since currently we only support one backup target.
|
|
||||||
spec:
|
|
||||||
backupTargetURL: the backup target URL. (string)
|
|
||||||
credentialSecret: the backup target credential secret. (string)
|
|
||||||
pollInterval: the backup target poll interval. (metav1.Duration)
|
|
||||||
syncRequestAt: the time to request run sync the remote backup target. (*metav1.Time)
|
|
||||||
status:
|
|
||||||
ownerID: the node ID which is responsible for running operations of the backup target controller. (string)
|
|
||||||
available: records if the remote backup target is available or not. (bool)
|
|
||||||
lastSyncedAt: records the last time the backup target was running the reconcile process. (*metav1.Time)
|
|
||||||
```
|
|
||||||
|
|
||||||
2. Create a new BackupVolume CRD `backupvolumes.longhorn.io`.
|
|
||||||
|
|
||||||
```yaml
|
|
||||||
metadata:
|
|
||||||
name: the backup volume name.
|
|
||||||
spec:
|
|
||||||
syncRequestAt: the time to request run sync the remote backup volume. (*metav1.Time)
|
|
||||||
fileCleanupRequired: indicate to delete the remote backup volume config or not. (bool)
|
|
||||||
status:
|
|
||||||
ownerID: the node ID which is responsible for running operations of the backup volume controller. (string)
|
|
||||||
lastModificationTime: the backup volume config last modification time. (Time)
|
|
||||||
size: the backup volume size. (string)
|
|
||||||
labels: the backup volume labels. (map[string]string)
|
|
||||||
createAt: the backup volume creation time. (string)
|
|
||||||
lastBackupName: the latest volume backup name. (string)
|
|
||||||
lastBackupAt: the latest volume backup time. (string)
|
|
||||||
dataStored: the backup volume block count. (string)
|
|
||||||
messages: the error messages when call longhorn engine on list or inspect backup volumes. (map[string]string)
|
|
||||||
lastSyncedAt: records the last time the backup volume was synced into the cluster. (*metav1.Time)
|
|
||||||
```
|
|
||||||
|
|
||||||
3. Create a new Backup CRD `backups.longhorn.io`.
|
|
||||||
|
|
||||||
```yaml
|
|
||||||
metadata:
|
|
||||||
name: the backup name.
|
|
||||||
labels:
|
|
||||||
longhornvolume=<backup-volume-name>`: this label indicates which backup volume the backup belongs to.
|
|
||||||
spec:
|
|
||||||
fileCleanupRequired: indicate to delete the remote backup config or not (and the related block files if needed). (bool)
|
|
||||||
snapshotName: the snapshot name. (string)
|
|
||||||
labels: the labels of snapshot backup. (map[string]string)
|
|
||||||
backingImage: the backing image. (string)
|
|
||||||
backingImageURL: the backing image URL. (string)
|
|
||||||
status:
|
|
||||||
ownerID: the node ID which is responsible for running operations of the backup controller. (string)
|
|
||||||
backupCreationIsStart: to indicate the snapshot backup creation is start or not. (bool)
|
|
||||||
url: the snapshot backup URL. (string)
|
|
||||||
snapshotName: the snapshot name. (string)
|
|
||||||
snapshotCreateAt: the snapshot creation time. (string)
|
|
||||||
backupCreateAt: the snapshot backup creation time. (string)
|
|
||||||
size: the snapshot size. (string)
|
|
||||||
labels: the labels of snapshot backup. (map[string]string)
|
|
||||||
messages: the error messages when calling longhorn engine on listing or inspecting backups. (map[string]string)
|
|
||||||
lastSyncedAt: records the last time the backup was synced into the cluster. (*metav1.Time)
|
|
||||||
```
|
|
||||||
|
|
||||||
4. At the existed `setting_controller`.
|
|
||||||
|
|
||||||
Watches the changes of Setting CR `settings.longorn.io` field `backup-target`, `backup-target-credential-secret`, and `backupstore-poll-interval`. The setting controller is responsible for creating/updating the default BackupTarget CR. The setting controller creates a timer goroutine according to `backupstore-poll-interval`. Once the timer up, updates the BackupTarget CR `spec.syncRequestAt = time.Now()`. If the `backupstore-poll-interval = 0`, do not updates the BackupTarget CR `spec.syncRequestAt`.
|
|
||||||
|
|
||||||
5. Create a new `backup_target_controller`.
|
|
||||||
|
|
||||||
Watches the change of BackupTarget CR. The backup target controller is responsible for creating/updating/deleting BackupVolume CR metadata+spec. The reconcile loop steps are:
|
|
||||||
1. Check if the current node ID == BackupTarget CR spec.responsibleNodeID. If no, skip the reconcile process.
|
|
||||||
2. Check if the `status.lastSyncedAt < spec.syncRequestAt`. If no, skip the reconcile process.
|
|
||||||
3. Call the longhorn engine to list all the backup volumes `backup ls --volume-only` from the remote backup target `backupStoreBackupVolumes`. If the remote backup target is unavailable:
|
|
||||||
1. Updates the BackupTarget CR `status.available=false` and `status.lastSyncedAt=time.Now()`.
|
|
||||||
2. Skip the current reconcile process.
|
|
||||||
4. List in cluster BackupVolume CRs `clusterBackupVolumes`.
|
|
||||||
5. Find the difference backup volumes `backupVolumesToPull = backupStoreBackupVolumes - clusterBackupVolumes` and create BackupVolume CR `metadata.name`.
|
|
||||||
6. Find the difference backup volumes `backupVolumesToDelete = clusterBackupVolumes - backupStoreBackupVolumes` and delete BackupVolume CR.
|
|
||||||
7. List in cluster BackupVolume CRs `clusterBackupVolumes` again and updates the BackupVolume CR `spec.syncRequestAt = time.Now()`.
|
|
||||||
8. Updates the BackupTarget CR status:
|
|
||||||
1. `status.available=true`.
|
|
||||||
2. `status.lastSyncedAt = time.Now()`.
|
|
||||||
|
|
||||||
6. For the Longhorn manager HTTP endpoints:
|
|
||||||
|
|
||||||
- **DELETE** `/v1/backupvolumes/{volName}`:
|
|
||||||
1. Update the BackupVolume CR `spec.fileCleanupRequired=true` with the given volume name.
|
|
||||||
2. Delete a BackupVolume CR with the given volume name.
|
|
||||||
|
|
||||||
7. Create a new controller `backup_volume_controller`.
|
|
||||||
|
|
||||||
Watches the change of BackupVolume CR. The backup volume controller is responsible for deleting Backup CR and deleting backup volume from remote backup target if delete BackupVolume CR event comes in, and updating BackupVolume CR status field, and creating/deleting Backup CR. The reconcile loop steps are:
|
|
||||||
1. Check if the current node ID == BackupTarget CR spec.responsibleNodeID. If no, skip the reconcile process.
|
|
||||||
2. If the delete BackupVolume CR event comes in:
|
|
||||||
1. updates Backup CRs `spec.fileCleanupRequired=true` if BackupVolume CR `spec.fileCleanupRequired=true`.
|
|
||||||
2. deletes Backup CR with the given volume name.
|
|
||||||
3. deletes the backup volume from the remote backup target `backup rm --volume <volume-name> <url>` if `spec.fileCleanupRequired=true`.
|
|
||||||
4. remove the finalizer.
|
|
||||||
3. Check if the `status.lastSyncedAt < spec.syncRequestAt`. If no, skip the reconcile process.
|
|
||||||
4. Call the longhorn engine to list all the backups `backup ls --volume <volume-name>` from the remote backup target `backupStoreBackups`.
|
|
||||||
5. List in cluster Backup CRs `clusterBackups`.
|
|
||||||
6. Find the difference backups `backupsToPull = backupStoreBackups - clusterBackups` and create Backup CR `metadata.name` + `metadata.labels["longhornvolume"]=<backup-volume-name>`.
|
|
||||||
7. Find the difference backups `backupsToDelete = clusterBackups - backupStoreBackups` and delete Backup CR.
|
|
||||||
8. Call the longhorn engine to get the backup volume config's last modification time `backup head <volume-config>` and compares to `status.lastModificationTime`. If the config last modification time not changed, updates the `status.lastSyncedAt` and return.
|
|
||||||
9. Call the longhorn engine to read the backup volumes' config `backup inspect-volume <volume-name>`.
|
|
||||||
10. Updates the BackupVolume CR status:
|
|
||||||
1. according to the backup volumes' config.
|
|
||||||
2. `status.lastModificationTime` and `status.lastSyncedAt`.
|
|
||||||
11. Updates the Volume CR `status.lastBackup` and `status.lastBackupAt`.
|
|
||||||
|
|
||||||
8. For the Longhorn manager HTTP endpoints:
|
|
||||||
|
|
||||||
- **POST** `/v1/volumes/{volName}?action=snapshotBackup`:
|
|
||||||
1. Generate the backup name <backup-name>.
|
|
||||||
2. Create a new Backup CR with
|
|
||||||
```yaml
|
|
||||||
metadata:
|
|
||||||
name: <backup-name>
|
|
||||||
labels:
|
|
||||||
longhornvolume: <backup-volume-name>
|
|
||||||
spec:
|
|
||||||
snapshotName: <snapshot-name>
|
|
||||||
labels: <snapshot-backup-labels>
|
|
||||||
backingImage: <backing-image>
|
|
||||||
backingImageURL: <backing-image-URL>
|
|
||||||
```
|
|
||||||
- **DELETE** `/v1/backupvolumes/{volName}?action=backupDelete`:
|
|
||||||
1. Update the Backup CR `spec.fileCleanupRequired=true` with the given volume name.
|
|
||||||
2. Delete a Backup CR with the given backup name.
|
|
||||||
|
|
||||||
9. Create a new controller `backup_controller`.
|
|
||||||
|
|
||||||
Watches the change of Backup CR. The backup controller is responsible for updating the Backup CR status field and creating/deleting backup to/from the remote backup target. The reconcile loop steps are:
|
|
||||||
1. Check if the current node ID == BackupTarget CR spec.responsibleNodeID. If no, skip the reconcile process.
|
|
||||||
2. If the delete Backup CR event comes in:
|
|
||||||
1. delete the backup from the remote backup target `backup rm <url>` if Backup CR `spec.fileCleanupRequired=true`.
|
|
||||||
2. update the BackupVolume CR `spec.syncRequestAt=time.Now()`.
|
|
||||||
3. remove the finalizer.
|
|
||||||
3. Check if the Backup CR `spec.snapshotName != ""` and `status.backupCreationIsStart == false`. If yes:
|
|
||||||
1. call longhorn engine/replica for backup creation.
|
|
||||||
2. updates Backup CR `status.backupCreationIsStart = true`.
|
|
||||||
3. fork a go routine to monitor the backup creation progress. After backup creation finished (progress = 100):
|
|
||||||
1. update the BackupVolume CR `spec.syncRequestAt = time.Now()` if BackupVolume CR exist.
|
|
||||||
2. create the BackupVolume CR `metadata.name` if BackupVolume CR not exist.
|
|
||||||
4. If Backup CR `status.lastSyncedAt != nil`, the backup config had be synced, skip the reconcile process.
|
|
||||||
5. Call the longhorn engine to read the backup config `backup inspect <backup-url>`.
|
|
||||||
6. Updates the Backup CR status field according to the backup config.
|
|
||||||
7. Updates the Backup CR `status.lastSyncedAt`.
|
|
||||||
|
|
||||||
10. For the Longhorn manager HTTP endpoints:
|
|
||||||
|
|
||||||
- **GET** `/v1/backupvolumes`: read all the BackupVolume CRs.
|
|
||||||
- **GET** `/v1/backupvolumes/{volName}`: read a BackupVolume CR with the given volume name.
|
|
||||||
- **GET** `/v1/backupvolumes/{volName}?action=backupList`: read a list of Backup CRs with the label filter `volume=<backup-volume-name>`.
|
|
||||||
- **GET** `/v1/backupvolumes/{volName}?action=backupGet`: read a Backup CR with the given backup name.
|
|
||||||
|
|
||||||
### Test plan
|
|
||||||
|
|
||||||
With over 1k backup volumes and over 1k backups under pretty high network latency (700-800ms per operation)
|
|
||||||
from longhorn manager to the remote backup target:
|
|
||||||
|
|
||||||
- Test basic backup and restore operations.
|
|
||||||
1. The user configures the remote backup target URL/credential and poll interval to 5 mins.
|
|
||||||
2. The user creates two backups on vol-A and vol-B.
|
|
||||||
3. The user can see the backup volume for vol-A and vol-B in Backup GUI.
|
|
||||||
4. The user can see the two backups under vol-A and vol-B in Backup GUI.
|
|
||||||
5. When the user deletes one of the backups of vol-A on the Longhorn GUI, the deleted one will be deleted after the remote backup target backup be deleted.
|
|
||||||
6. When the user deletes backup volume vol-A on the Longhorn GUI, the backup volume will be deleted after the remote backup target backup volume is deleted, and the backup of vol-A will be deleted also.
|
|
||||||
7. The user can see the backup volume for vol-B in Backup GUI.
|
|
||||||
8. The user can see two backups under vol-B in Backup GUI.
|
|
||||||
9. The user changes the remote backup target to another backup target URL/credential, the user can't see the backup volume and backup of vol-B in Backup GUI.
|
|
||||||
10. The user configures the `backstore-poll-interval` to 1 minute.
|
|
||||||
11. The user changes the remote backup target to the original backup target URL/credential, after 1 minute later, the user can see the backup volume and backup of vol-B.
|
|
||||||
12. Create volume from the vol-B backup.
|
|
||||||
|
|
||||||
- Test DR volume operations.
|
|
||||||
1. Create two clusters (cluster-A and cluster-B) both points to the same remote backup target.
|
|
||||||
2. At cluster A, create a volume and run a recurring backup to the remote backup target.
|
|
||||||
3. At cluster B, after `backupstore-poll-interval` seconds, the user can list backup volumes or list volume backups on the Longhorn GUI.
|
|
||||||
4. At cluster B, create a DR volume from the backup volume.
|
|
||||||
5. At cluster B, check the DR volume `status.LastBackup` and `status.LastBackupAt` is updated periodically.
|
|
||||||
6. At cluster A, delete the backup volume on the GUI.
|
|
||||||
7. At cluster B, after `backupstore-poll-interval` seconds, the deleted backup volume does not exist on the Longhorn GUI.
|
|
||||||
8. At cluster B, the DR volume `status.LastBackup` and `status.LastBackupAt` won't be updated anymore.
|
|
||||||
|
|
||||||
- Test Backup Target URL clean up.
|
|
||||||
1. The user configures the remote backup target URL/credential and poll interval to 5 mins.
|
|
||||||
2. The user creates one backup on vol-A.
|
|
||||||
3. Change the backup target setting setting to empty.
|
|
||||||
4. Within 5 mins the poll interval triggered:
|
|
||||||
1. The default BackupTarget CR `status.available=false`.
|
|
||||||
2. The default BackupTarget CR `status.lastSyncedAt` be updated.
|
|
||||||
3. All the BackupVolume CRs be deleted.
|
|
||||||
4. All the Backup CRs be deleted.
|
|
||||||
5. The vol-A CR `status.lastBackup` and `status.lastBackupAt` be cleaned up.
|
|
||||||
5. The GUI displays the backup target not available.
|
|
||||||
|
|
||||||
- Test switch Backup Target URL.
|
|
||||||
1. The user configures the remote backup target URL/credential to S3 and poll interval to 5 mins.
|
|
||||||
2. The user creates one backup on vol-A to S3.
|
|
||||||
3. The user changes the remote backup URL/credential to NFS and poll interval to 5 mins.
|
|
||||||
4. The user creates one backup on vol-A to NFS.
|
|
||||||
5. The user changes the remote backup target URL/credential to S3.
|
|
||||||
6. Within 5 mins the poll interval triggered:
|
|
||||||
1. The default BackupTarget CR `status.available=true`.
|
|
||||||
2. The default BackupTarget CR `status.lastSyncedAt` be updated.
|
|
||||||
3. The BackupVolume CRs be synced as the data in S3.
|
|
||||||
4. The Backup CRs be synced as the data in S3.
|
|
||||||
5. The vol-A CR `status.lastBackup` and `status.lastBackupAt` be synced as the data in S3.
|
|
||||||
|
|
||||||
- Test Backup Target credential secret changed.
|
|
||||||
1. The user configures the remote backup target URL/credential and poll interval to 5 mins.
|
|
||||||
2. The user creates one backup on vol-A.
|
|
||||||
3. Change the backup target credential secret setting to empty.
|
|
||||||
4. Within 5 mins the poll interval triggered:
|
|
||||||
1. The default BackupTarget CR `status.available=false`.
|
|
||||||
2. The default BackupTarget CR `status.lastSyncedAt` be updated.
|
|
||||||
5. The GUI displays the backup target not available.
|
|
||||||
|
|
||||||
### Upgrade strategy
|
|
||||||
|
|
||||||
None.
|
|
||||||
|
|
||||||
## Note
|
|
||||||
|
|
||||||
With this enhancement, the user might want to trigger run synchronization immediately. We could either:
|
|
||||||
- have a button on the `Backup` to update the BackupTarget CR `spec.syncRequestAt = time.Now()` _or_ have a button on the `Backup` -> `Backup Volume` page to have a button to update the BackupVolume CR `spec.syncRequestAt = time.Now()`.
|
|
||||||
- updates the `spec.syncRequestAt = time.Now()` when the user clicks the `Backup` _or_ updates the `spec.syncRequestAt = time.Now()` when the user clicks `Backup` -> `Backup Volume`.
|
|
||||||
File diff suppressed because it is too large
Load Diff
@ -1,441 +0,0 @@
|
|||||||
# Backing Image v2
|
|
||||||
|
|
||||||
## Summary
|
|
||||||
Longhorn can set a backing image of a Longhorn volume, which is designed for VM usage.
|
|
||||||
|
|
||||||
### Related Issues
|
|
||||||
https://github.com/longhorn/longhorn/issues/2006
|
|
||||||
https://github.com/longhorn/longhorn/issues/2295
|
|
||||||
https://github.com/longhorn/longhorn/issues/2530
|
|
||||||
https://github.com/longhorn/longhorn/issues/2404
|
|
||||||
|
|
||||||
## Motivation
|
|
||||||
### Goals
|
|
||||||
1. A qcow2 or raw image file can be used as the backing image of a volume.
|
|
||||||
2. The backing image works fine with backup or restore.
|
|
||||||
3. Multiple replicas in the same disk can share one backing image.
|
|
||||||
4. The source of a backing image file can be remote downloading, upload, Longhorn volume, etc.
|
|
||||||
5. Once the first backing image file is ready, Longhorn can deliver it to other nodes.
|
|
||||||
6. Checksum verification for backing image.
|
|
||||||
7. HA backing image.
|
|
||||||
|
|
||||||
### Non-goals:
|
|
||||||
This feature is not responsible for fixing issue mentioned in [issue #1948](https://github.com/longhorn/longhorn/issues/1948#issuecomment-791641308).
|
|
||||||
|
|
||||||
## Proposal
|
|
||||||
1. Each backing image is stored as a object of a new CRD named `BackingImage`.
|
|
||||||
- The spec/status records if a disk requires/contains the related backing image file.
|
|
||||||
- To meet backing image HA requirement, some ready disks are randomly picked. Besides, whether a disk requires the backing image file is determined by if there is replicas using it in the disk.
|
|
||||||
- A file in a disk cannot be removed as long as there is a replica using it.
|
|
||||||
2. Longhorn needs to prepare the 1st backing image file based on the source type:
|
|
||||||
- Typically, the 1st file preparation takes a short amount of time comparing with the whole lifecycle of BackingImage. Longhorn can use a temporary pod to handle it. Once the file is ready, Longhorn can stop the pod.
|
|
||||||
- We can use a CRD named `BackingImageDataSource` to abstract the file preparation. The source type and the parameters will be in the spec.
|
|
||||||
- To allow Longhorn manager query the progress of the file preparation, we should launch a service for this pod. Considering that multiple kinds of source like download or uploading involve HTTP, we can launch a HTTP server for the pod.
|
|
||||||
3. Then there should be a component responsible for monitoring and syncing backing image files with other nodes after the 1st file ready.
|
|
||||||
- Similar to `BackingImageDataSource`, we will use a new CRD named `BackingImageManager` to abstract this component.
|
|
||||||
- The BackingImageManager pod is design to
|
|
||||||
- take over the ownership when the 1st file prepared by the BackingImageDataSource pod is ready.
|
|
||||||
- deliver the file to others if necessary.
|
|
||||||
- monitor all backing image files for a specific disk: Considering the disk migration and failed replica reusage features, there will be an actual backing image file for each disk rather than each node.
|
|
||||||
- BackingImageManager should support reuse existing backing image files. Since we will consider those files are immutable/read-only once ready. If there is an expected checksum for a BackingImage, the pod will compare the checksum before reusing.
|
|
||||||
- Live upgrade is possible: Different from instance managers, BackingImageManagers manage files only. We can directly shut down the old BackingImageManager pods, then let new BackingImageManager pods rely on the reuse mechanism to take over the existing files.
|
|
||||||
- If the disk is not available/gets replaced, the BackingImageManager cannot do anything or simply report all BackingImages failed.
|
|
||||||
- Once there is a modification for an image, managers will notify callers via the gRPC streaming.
|
|
||||||
4. `longhorn-manager` will launch & update controllers for these new CRDs:
|
|
||||||
- BackingImageController is responsible for:
|
|
||||||
1. Generate a UUID for each new BackingImage.
|
|
||||||
2. Sync with the corresponding BackingImageDataSource:
|
|
||||||
3. Handle BackingImageManager life cycle.
|
|
||||||
4. Sync download status/info with BackingImageDataSource status or BackingImageManager status.
|
|
||||||
5. Set timestamp if there is no replica using the backing image file in a disk.
|
|
||||||
- BackingImageDataSourceController is responsible for:
|
|
||||||
1. Sync with the corresponding BackingImage.
|
|
||||||
3. Handle BackingImageManager life cycle.
|
|
||||||
4. Sync download status/info with BackingImageDataSource status or BackingImageManager status.
|
|
||||||
5. Set timestamp if there is no replica using the BackingImage in a disk
|
|
||||||
- BackingImageManagerController is responsible for:
|
|
||||||
1. Create pods to handle backing image files.
|
|
||||||
2. Handle files based on the spec & BackingImageDataSource status:
|
|
||||||
- Delete unused BackingImages.
|
|
||||||
- Fetch the 1st file based on BackingImageDataSource. Otherwise, sync the files from other managers or directly reuse the existing files.
|
|
||||||
5. For `longhorn-engine`:
|
|
||||||
- Most of the backing image related logic is already in there.
|
|
||||||
- The raw image support will be introduced.
|
|
||||||
- Make sure the backing file path will be updated each time when the replica starts.
|
|
||||||
|
|
||||||
- The lifecycle of the components:
|
|
||||||
```
|
|
||||||
|Created by HTTP API. |Set deletion timestamp, will delete BackingImageDataSource first.
|
|
||||||
BackingImage: |========|============================================================================|======================================================|
|
|
||||||
|Create BackingImageManagers |Deleted after cleanup.
|
|
||||||
| base on HA or replica requirements.
|
|
||||||
|
|
||||||
|Created by HTTP API after |Set deletion timestamp when
|
|
||||||
| BackingImage creation. | BackingImage is being deleted.
|
|
||||||
BackingImageDataSource: |===============|=========================================|=============|=================|=========================================|
|
|
||||||
|Start a pod then |File ready. |Stop the pod when |Deleted.
|
|
||||||
| file preparation immediately | BackingImageManager takes over the file.
|
|
||||||
|
|
||||||
|Take over the 1st file from BackingImageDataSource. |Do cleanup if required
|
|
||||||
|Created by BackingImageController | Or sync/receive files from peers. | then get deleted.
|
|
||||||
BackingImageManager: |===========|==============|==================================|===============================================|============|
|
|
||||||
|Start a pod. |Keep file monitoring |Set deletion timestamp since
|
|
||||||
| after pod running. | no BackingImage is in the disk.
|
|
||||||
```
|
|
||||||
- BackingImage CRs and BackingImageDataSource CRs are one-to-one correspondence.
|
|
||||||
One backingImageDataSource CR is always created after the related BackingImage CR, but deleted before the BackingImage CR cleanup.
|
|
||||||
- The lifecycle of one BackingImageManager CR is not controlled by one single BackingImage. For a disk, the related BackingImageManager CR will be created as long as there is one BackingImage required.
|
|
||||||
However, it will be removed only if there is no BackingImage in the disk.
|
|
||||||
|
|
||||||
### User Stories
|
|
||||||
#### Rebuild replica for a large volume after network fluctuation/node reboot
|
|
||||||
Before the enhancement, users need to manually copy the backing image data to the volume in advance.
|
|
||||||
|
|
||||||
After the enhancement, users can directly specify the BackingImage during volume creation/restore with a click. And one backing image file can be shared among all replicas in the same disk.
|
|
||||||
|
|
||||||
### User Experience In Detail
|
|
||||||
1. Users can modify the backing image file cleanup timeout setting so that all non-used files will be cleaned up automatically from disks.
|
|
||||||
2. Create a volume with a backing image
|
|
||||||
2.1. via Longhorn UI
|
|
||||||
1. Users add a backing image, which is similar to add an engine image or set up the backup target in the system.
|
|
||||||
2. Users create/restore a volume with the backing image specified from the backing image list.
|
|
||||||
2.2. via CSI (StorageClass)
|
|
||||||
- By specifying `backingImageName` in a StorageClass, all volumes created by this StorageClass will utilize this backing image.
|
|
||||||
- If the optional fields `backingImageDataSourceType` and `backingImageDataSourceParameters` are set and valid, Longhorn will automatically create a volume as well as the backing image if the backing image does not exists.
|
|
||||||
3. Users attach the volume to a node (via GUI or Kubernetes). Longhorn will automatically prepare the related backing image to the disks the volume replica are using. In brief, users don't need to do anything more for the backing image.
|
|
||||||
4. When users backup a volume with a backing image, the backing image info will be recorded in the backup but the actual backing image data won't be uploaded to the backupstore. Instead, the backing image will be re-downloaded from the original image once it's required.
|
|
||||||
|
|
||||||
### API Changes
|
|
||||||
- A bunch of RESTful APIs is required for the new CRD `BackingImage`: `Create`, `Delete`, `List`, and `BackingImageCleanup`.
|
|
||||||
- Now the volume creation API receives parameter `BackingImage`.
|
|
||||||
|
|
||||||
## Design
|
|
||||||
### Implementation Overview
|
|
||||||
#### longhorn-manager:
|
|
||||||
1. In settings:
|
|
||||||
- Add a setting `Backing Image Cleanup Wait Interval`.
|
|
||||||
- Add a read-only setting `Default Backing Image Manager Image`.
|
|
||||||
2. Add a new CRD `backingimages.longhorn.io`.
|
|
||||||
```goregexp
|
|
||||||
type BackingImageSpec struct {
|
|
||||||
Disks map[string]struct{} `json:"disks"`
|
|
||||||
Checksum string `json:"checksum"`
|
|
||||||
}
|
|
||||||
|
|
||||||
type BackingImageStatus struct {
|
|
||||||
OwnerID string `json:"ownerID"`
|
|
||||||
UUID string `json:"uuid"`
|
|
||||||
Size int64 `json:"size"`
|
|
||||||
Checksum string `json:"checksum"`
|
|
||||||
DiskFileStatusMap map[string]*BackingImageDiskFileStatus `json:"diskFileStatusMap"`
|
|
||||||
DiskLastRefAtMap map[string]string `json:"diskLastRefAtMap"`
|
|
||||||
}
|
|
||||||
|
|
||||||
type BackingImageDiskFileStatus struct {
|
|
||||||
State BackingImageState `json:"state"`
|
|
||||||
Progress int `json:"progress"`
|
|
||||||
Message string `json:"message"`
|
|
||||||
}
|
|
||||||
```
|
|
||||||
```goregexp
|
|
||||||
const (
|
|
||||||
BackingImageStatePending = BackingImageState("pending")
|
|
||||||
BackingImageStateStarting = BackingImageState("starting")
|
|
||||||
BackingImageStateReady = BackingImageState("ready")
|
|
||||||
BackingImageStateInProgress = BackingImageState("in_progress")
|
|
||||||
BackingImageStateFailed = BackingImageState("failed")
|
|
||||||
BackingImageStateUnknown = BackingImageState("unknown")
|
|
||||||
)
|
|
||||||
```
|
|
||||||
- Field `Spec.Disks` records the disks that requires this backing image.
|
|
||||||
- Field `Status.DiskFileStatusMap` reflect the current file status for the disks. If there is anything wrong with the file, the error message can be recorded inside the status.
|
|
||||||
- Field `Status.UUID` should be generated and stored in ETCD before other operations. Considering users may create a new BackingImage with the same name but different parameters after deleting an old one, to avoid the possible leftover of the old BackingImage disturbing the new one, the manager can use a UUID to generate the work directory.
|
|
||||||
3. Add a new CRD `backingimagedatasources.longhorn.io`.
|
|
||||||
```goregexp
|
|
||||||
type BackingImageDataSourceSpec struct {
|
|
||||||
NodeID string `json:"nodeID"`
|
|
||||||
DiskUUID string `json:"diskUUID"`
|
|
||||||
DiskPath string `json:"diskPath"`
|
|
||||||
Checksum string `json:"checksum"`
|
|
||||||
SourceType BackingImageDataSourceType `json:"sourceType"`
|
|
||||||
Parameters map[string]string `json:"parameters"`
|
|
||||||
Started bool `json:"started"`
|
|
||||||
}
|
|
||||||
|
|
||||||
type BackingImageDataSourceStatus struct {
|
|
||||||
OwnerID string `json:"ownerID"`
|
|
||||||
CurrentState BackingImageState `json:"currentState"`
|
|
||||||
Size int64 `json:"size"`
|
|
||||||
Progress int `json:"progress"`
|
|
||||||
Checksum string `json:"checksum"`
|
|
||||||
}
|
|
||||||
|
|
||||||
type BackingImageDataSourceType string
|
|
||||||
|
|
||||||
const (
|
|
||||||
BackingImageDataSourceTypeDownload = BackingImageDataSourceType("download")
|
|
||||||
BackingImageDataSourceTypeUpload = BackingImageDataSourceType("upload")
|
|
||||||
)
|
|
||||||
|
|
||||||
const (
|
|
||||||
DataSourceTypeDownloadParameterURL = "url"
|
|
||||||
)
|
|
||||||
```
|
|
||||||
- Field `Started` indicates if the BackingImageManager already takes over the file. Once this is set, Longhorn can stop the corresponding pod as well as updating the object itself.
|
|
||||||
4. Add a new CRD `backingimagemanagers.longhorn.io`.
|
|
||||||
```goregexp
|
|
||||||
type BackingImageManagerSpec struct {
|
|
||||||
Image string `json:"image"`
|
|
||||||
NodeID string `json:"nodeID"`
|
|
||||||
DiskUUID string `json:"diskUUID"`
|
|
||||||
DiskPath string `json:"diskPath"`
|
|
||||||
BackingImages map[string]string `json:"backingImages"`
|
|
||||||
}
|
|
||||||
|
|
||||||
type BackingImageManagerStatus struct {
|
|
||||||
OwnerID string `json:"ownerID"`
|
|
||||||
CurrentState BackingImageManagerState `json:"currentState"`
|
|
||||||
BackingImageFileMap map[string]BackingImageFileInfo `json:"backingImageFileMap"`
|
|
||||||
IP string `json:"ip"`
|
|
||||||
APIMinVersion int `json:"apiMinVersion"`
|
|
||||||
APIVersion int `json:"apiVersion"`
|
|
||||||
}
|
|
||||||
```
|
|
||||||
```goregexp
|
|
||||||
type BackingImageFileInfo struct {
|
|
||||||
Name string `json:"name"`
|
|
||||||
UUID string `json:"uuid"`
|
|
||||||
Size int64 `json:"size"`
|
|
||||||
State BackingImageState `json:"state"`
|
|
||||||
CurrentChecksum string `json:"currentChecksum"`
|
|
||||||
Message string `json:"message"`
|
|
||||||
SendingReference int `json:"sendingReference"`
|
|
||||||
SenderManagerAddress string `json:"senderManagerAddress"`
|
|
||||||
Progress int `json:"progress"`
|
|
||||||
}
|
|
||||||
```
|
|
||||||
```goregexp
|
|
||||||
const (
|
|
||||||
BackingImageManagerStateError = BackingImageManagerState("error")
|
|
||||||
BackingImageManagerStateRunning = BackingImageManagerState("running")
|
|
||||||
BackingImageManagerStateStopped = BackingImageManagerState("stopped")
|
|
||||||
BackingImageManagerStateStarting = BackingImageManagerState("starting")
|
|
||||||
BackingImageManagerStateUnknown = BackingImageManagerState("unknown")
|
|
||||||
)
|
|
||||||
```
|
|
||||||
- Field `Spec.BackingImages` records which BackingImages should be monitored by the manager. the key is BackingImage name, the value is BackingImage UUID.
|
|
||||||
- Field `Status.BackingImageFileMap` will be updated according to the actual file status reported by the related manager pod.
|
|
||||||
- Struct `BackingImageFileInfo` is used to load the info from BackingImageManager pods.
|
|
||||||
5. Add a new controller `BackingImageDataSourceController`.
|
|
||||||
1. Important notices:
|
|
||||||
1. Once a BackingImageManager takes over the file ownership, the controller doesn't need to update the related BackingImageDataSource CR except for cleanup.
|
|
||||||
3. The state is designed to reflect the file state rather than the pod phase. Of course, the file state will be considered as failed if the pod somehow doesn't work correctly. e.g., the pod suddenly becomes failed or being removed.
|
|
||||||
2. Workflow:
|
|
||||||
1. Check and update the ownership.
|
|
||||||
2. Do cleanup if the deletion timestamp is set. Cleanup means stopping monitoring and kill the pod.
|
|
||||||
3. Sync with the BackingImage:
|
|
||||||
1. For in-progress BackingImageDataSource, Make sure the disk used by this BackingImageDataSource is recorded in the BackingImage spec as well.
|
|
||||||
2. [TODO] Guarantee the HA by adding more disks to the BackingImage spec once BackingImageDataSource is started.
|
|
||||||
4. Skip updating "started" BackingImageDataSource.
|
|
||||||
5. Handle pod:
|
|
||||||
1. Check the pod status.
|
|
||||||
2. Update the state based on the previous state and the current pod phase:
|
|
||||||
1. If the pod is ready for service, do nothing.
|
|
||||||
2. If the pod is not ready, but the file processing already start. It means there is something wrong with the flow. This BackingImageDataSource will be considered as `error`.
|
|
||||||
3. If the pod is failed, the BackingImageDataSource should be `error` as well.
|
|
||||||
4. When the pod reaches an unexpected phase or becomes failed, need to record the error message or error log in the pod.
|
|
||||||
3. Start or stop monitoring based on pod phase.
|
|
||||||
4. Delete the errored pod.
|
|
||||||
5. Create or recreate the pod, then update the backoff entry. Whether the pod can be recreated is determined by the backoff window and the source type. For the source types like upload, recreating pod doesn't make sense. Users need to directly do cleanup then recreate a new backing image instead.
|
|
||||||
6. For the monitor goroutine, it's similar to that in InstanceManagerController.
|
|
||||||
- It will `Get` the file info via HTTP every 3 seconds.
|
|
||||||
- If there are 10 continuous HTTP failures, the monitor goroutine will stop itself. Then the controller will restart it.
|
|
||||||
- If the backing image is ready, clean up the entry in the backoff.
|
|
||||||
6. Add a new controller `BackingImageManagerController`.
|
|
||||||
1. Important notices:
|
|
||||||
1. Need to consider 2 kinds of managers: default manager, old manager(this includes all incompatible managers).
|
|
||||||
2. All old managers will be removed immediately once there is the default image is updated. And old managers shouldn't operate any backing image files.
|
|
||||||
- When an old manager is removed, the files inside in won't be gone. These files will be taken by the new one. By disabling old managers operating the files, the conflicts with the default manager won't happen.
|
|
||||||
- The controller can directly delete old BackingImageManagers without affecting existing BackingImages. This simplifies the cleanup flow.
|
|
||||||
- Ideally there should be a cleanup mechanism that is responsible for removing all failed backing image files as well as the images no longer required by the new BackingImageManagers. But due to lacking of time, it will be implemented in the future.
|
|
||||||
3. In most cases, the controller and the BackingImageManager will avoid deleting backing images files.:
|
|
||||||
- For example, if the pod is crashed or one image file becomes failed, the controller will directly restart the pod or re-download the image, rather than cleaning up the files only.
|
|
||||||
- The controller will delete image files for only 2 cases: A BackingImage is no longer valid; A default BackingImageManager is deleted.
|
|
||||||
- By following this strategy, we may risk at leaving some unused backing image files in some corner cases.
|
|
||||||
However, the gain is that, there is lower probability of crashing a replica caused by the backing image file deletion. Besides, the existing files can be reused after recovery.
|
|
||||||
And after introducing the cleanup mechanism, we should worry about the leftover anymore.
|
|
||||||
4. With passive file cleanup strategy, default managers can directly pick up all existing files via `Fetch` requests when the old manager pods are killed. This is the essential of live upgrade.
|
|
||||||
5. The pod not running doesn't mean all files handled by the pod become invalid. All files can be reused/re-monitored after the pod restarting.
|
|
||||||
2. Workflow:
|
|
||||||
1. If the deletion timestamp is set, the controller will clean up files for running default BackingImageManagers only. Then it will blindly delete the related pods.
|
|
||||||
2. When the disk is not ready, the current manager will be marked as `unknown`. Then all not-failed file records are considered as `unknown` as well.
|
|
||||||
- Actually there are multiple subcases here: node down, node reboot, node disconnection, disk detachment, longhorn manager pod missing etc. It's complicated to distinguish all subcases to do something special. Hence, I choose simply marking the state to `unknown`.
|
|
||||||
3. Create BackingImageManager pods for.
|
|
||||||
- If the old status is `running` but the pod is not ready now, there must be something wrong with the manager pod. Hence the controller need to update the state to `error`.
|
|
||||||
- When the pod is ready, considering the case that the pod creation may succeed but the CR status update will fail due to conflicts, the controller won't check the previous state. Instead, it will directly update state to `running`.
|
|
||||||
- Start a monitor goroutine for each running pods.
|
|
||||||
- If the manager is state `error`, the controller will do cleanup then recreate the pod.
|
|
||||||
4. Handle files based on the spec:
|
|
||||||
- Delete invalid files:
|
|
||||||
- The BackingImages is no longer in `BackingImageManager.Spec.BackingImages`.
|
|
||||||
- The BackingImage UUID doesn't match.
|
|
||||||
- Make files ready for the disk:
|
|
||||||
1. When BackingImageDataSource is not "started", it means BackingImageManager hasn't taken over the 1st file. Once BackingImageDataSource reports file ready, BackingImageManager can get the 1st file via API `Fetch`.
|
|
||||||
2. Then if BackingImageDataSource is "started" but there is no ready record for a BackingImage among all managers, it means the pod someshow restarted (may due to upgrade). In this case, BackingImageManager can try to reuse the files via API `Fetch` as well.
|
|
||||||
3. Otherwise, the current manager will try to sync the file with other managers:
|
|
||||||
- If the 1st file is not ready, do nothing.
|
|
||||||
- Each manager can send a ready file to 3 other managers simultaneously at max. When there is no available sender, do nothing.
|
|
||||||
4. Before reusing or syncing files, the controller need to check the backoff entry for the corresponding BackingImageManager. And after the API call, the backoff entry will be updated.
|
|
||||||
5. For the monitor goroutine, it's similar to that in InstanceManagerController.
|
|
||||||
- It will `List` all backing image files once it receives the notification from the streaming.
|
|
||||||
- If there are 10 continuous errors returned by the streaming receive function, the monitor goroutine will stop itself. Then the controller will restart it.
|
|
||||||
- Besides, if a backing image is ready, the monitor should clean up the entry from the backoff of the BackingImageManager.
|
|
||||||
7. Add a new controller `BackingImageController`.
|
|
||||||
1. Important notices:
|
|
||||||
1. One main responsibility of this controller is creating, deleting, and update BackingImageManagers. It is not responsible for communicating with BackingImageManager pods or BackingImageDataSource pods.
|
|
||||||
2. This controller can reset "started" BackingImageDataSource if all its backing image files are errored in the cluster and the source type is satisfied.
|
|
||||||
3. The immutable UUID should be generated and stored in ETCD before any other update. This UUID can can be used to distinguish a new BackingImage from an old BackingImage using the same name.
|
|
||||||
4. Beside recording the immutable UUID, the BackingImage status is used to record the file info in the managers status and present to users.
|
|
||||||
5. Always try to create default BackingImageManagers if not exist.
|
|
||||||
6. Aggressively delete non-default BackingImageManagers.
|
|
||||||
2. Workflow:
|
|
||||||
1. If the deletion timestamp is set, the controller need to do cleanup for all related BackingImageManagers as well as BackingImageDataSource.
|
|
||||||
2. Generate a UUID for each new BackingImage. Make sure the UUID is stored in ETCD before doing anything others.
|
|
||||||
3. Init fields in the BackingImage status.
|
|
||||||
4. Sync with BackingImageDataSource:
|
|
||||||
1. Mark BackingImageDataSource as started if the default BackingImageManager already takes over the file ownership.
|
|
||||||
2. When all files failed, mark the BackingImageDataSource when the source type is downloaded. Then it can re-download the file and recover this BackingImage.
|
|
||||||
3. Guarantee the disk info in BackingImageDataSources spec is correct if it's not started. (This can be done in Node Controller as well.)
|
|
||||||
5. Handle BackingImageManager life cycle:
|
|
||||||
- Remove records in `Spec.BackingImages` or directly delete the manager CR
|
|
||||||
- Add records to `Spec.BackingImages` for the current BackingImage. Create BackingImageManagers with default image if not exist.
|
|
||||||
6. Sync download status/info with BackingImageManager status:
|
|
||||||
- If BackingImageDataSource is not started, update BackingImage status based on BackingImageDataSource status. Otherwise, sync status with BackingImageManagers.
|
|
||||||
- Set `Status.Size` if it's 0. If somehow the size is not same among all BackingImageManagers, this means there is an unknown bug. Similar logic applied to `Status.CurrentChecksum`.
|
|
||||||
7. Set timestamp in `Status.DiskLastRefAtMap` if there is no replica using the BackingImage in a disk. Later NodeController will do cleanup for `Spec.DiskDownloadMap` based on the timestamp.
|
|
||||||
Notice that this clean up should not break the backing image HA.
|
|
||||||
1. Try to set timestamps for disks in which there is no replica/BackingImageDataSource using this BackingImage first.
|
|
||||||
2. If there is no enough ready files after marking, remove timestamps for some disks that contain ready files.
|
|
||||||
3. If HA requirement is not satisfied when all ready files are retained, remove timestamps for some disks that contain in-progress/pending files.
|
|
||||||
4. If HA requirement is not unsatisfied, remove timestamps for some disks that contain failed files. Later Longhorn can try to do recovery for the disks contains these failed files.
|
|
||||||
6. In Replica Controller:
|
|
||||||
- Request preparing the backing image file in a disk if a BackingImage used by a replica doesn't exist.
|
|
||||||
- Check and wait for BackingImage disk map in the status before sending requests to replica instance managers.
|
|
||||||
7. In Node Controller:
|
|
||||||
- Determine if the disk needs to be cleaned up if checking BackingImage `Status.DiskLastRefAtMap` and the wait interval `BackingImageCleanupWaitInterval`.
|
|
||||||
- Update the spec for BackingImageManagers when there is a disk migration.
|
|
||||||
8. For the HTTP APIs
|
|
||||||
- Volume creation:
|
|
||||||
- Longhorn needs to verify the BackingImage if it's specified.
|
|
||||||
- For restore/DR volumes, the BackingImage name stored in the backup volume will be used automatically if users do not specify the BackingImage name. Verify the checksum before using the BackingImage.
|
|
||||||
- Snapshot backup:
|
|
||||||
- BackingImage name and checksum will be record into BackupVolume now.
|
|
||||||
- BackingImage creation:
|
|
||||||
- Need to create both BackingImage CR and the BackingImageDataSource CR. Besides, a random ready disk will be picked up so that Longhorn can prepare the 1st file for the BackingImage immediately.
|
|
||||||
- BackingImage get/list:
|
|
||||||
- Be careful about the BackingImageDataSource not found error. There are 2 cases that would lead to this error:
|
|
||||||
- BackingImageDataSource has not been created. Add retry would solve this case.
|
|
||||||
- BackingImageDataSource is gone but BackingImage has not been cleaned up. Longhorn can ignore BackingImageDataSource when BackingImage deletion timestamp is set.
|
|
||||||
- BackingImage disk cleanup:
|
|
||||||
- This cannot break the HA besides attaching replicas. The main idea is similar to the cleanup in BackingImage Controller.
|
|
||||||
9. In CSI:
|
|
||||||
- Check the backing image during the volume creation.
|
|
||||||
- The missing BackingImage will be created when both BackingImage name and data source info are provided.
|
|
||||||
|
|
||||||
#### longhorn-engine:
|
|
||||||
- Verify the existing implementation and the related integration tests.
|
|
||||||
- Add raw backing file support.
|
|
||||||
- Update the backing file info for replicas when a replica is created/opened.
|
|
||||||
|
|
||||||
#### backing-image-manager:
|
|
||||||
##### data source service:
|
|
||||||
- A HTTP server will be launched to prepare the 1st BackingImage file based on the source type.
|
|
||||||
- The server will download the file immediately once the type is `download` and the server is up.
|
|
||||||
- A cancelled context will be put the HTTP download request. When the server is stopped/failed while downloading is still in-progress, the context can help stop the download.
|
|
||||||
- The service will wait for 30s at max for download start. If time exceeds, the download is considered as failed.
|
|
||||||
- The download file is in `<Disk path in container>/tmp/<BackingImage name>-<BackingImage UUID>`
|
|
||||||
- Each time when the image downloads a chunk of data, the progress will be updated. For the first time updating the progress, it means the downloading starts and the state will be updated from `starting` to `in-progress`.
|
|
||||||
- The server is ready for handling the uploaded data once the type is `upload` and the server is up.
|
|
||||||
- The query `size` is required for the API `upload`.
|
|
||||||
- The API `upload` receives a multi-part form request. And the body request is the file data streaming.
|
|
||||||
- Similar to the download, the progress will be updated as long as the API receives and stores a chunk of data. For the first time updating the progress, it means the uploading starts and the state will be updated from `starting` to `in-progress`.
|
|
||||||
##### manager service:
|
|
||||||
- A gRPC service will be launched to monitor and sync BackingImages:
|
|
||||||
- API `Fetch`: Register the image then move the file prepared by BackingImageDataSource server to the image work directory. The file is typically in a tmp directory
|
|
||||||
- If the file name is not specified in the request, it means reusing the existing file only.
|
|
||||||
- For a failed BackingImage, the manager will re-register then re-fetch it.
|
|
||||||
- Before fetching the file, the BackingImage will check if there are existing files in the current work directory. It the files exist and the checksum matches, the file will be directly reused and the config file is updated.
|
|
||||||
- Otherwise, the work directory will be cleaned up and recreated. Then the file in the tmp directory will be moved to the work directory.
|
|
||||||
- API `Sync`: Register the image, start a receiving server, and ask another manager to send the file via API `Send`. For a failed BackingImage, the manager will re-register then re-sync it. This should be similar to replica rebuilding.
|
|
||||||
- Similar to `Fetch`, the image will try to reuse existing files.
|
|
||||||
- The manager is responsible for managing all port. The image will use the functions provided by the manager to get then release ports.
|
|
||||||
- API `Send`: Send a backing image file to a receiver. This should be similar to replica rebuilding.
|
|
||||||
- API `Delete`: Unregister the image then delete the image work directory. Make sure syncing or pulling will be cancelled if exists.
|
|
||||||
- API `Get`/`List`: Collect the status of one backing image file/all backing image files.
|
|
||||||
- API `Watch`: establish a streaming connection to report BackingImage file info.
|
|
||||||
- As I mentioned above, we will use BackingImage UUID to generate work directories for each BackingImage. The work directory is like:
|
|
||||||
```
|
|
||||||
<Disk path in container>/backing-images/
|
|
||||||
<Disk path in container>/backing-images/<Syncing BackingImage name>-<Syncing BackingImage UUID>/backing.tmp
|
|
||||||
<Disk path in container>/backing-images/<Ready BackingImage name>-<Ready BackingImage UUID>/backing
|
|
||||||
<Disk path in container>/backing-images/<Ready BackingImage name>-<Ready BackingImage UUID>/backing.cfg
|
|
||||||
```
|
|
||||||
- There is a goroutine periodically check the file existence based on the image file current state.
|
|
||||||
- It will verify the disk UUID in the disk config file. If there is a mismatching, it will stop checking existing files. And the calls, longhorn manager pods, won't send requests since this BackingImageManager is marked as `unknown`.
|
|
||||||
- The manager will provide one channel for all BackingImages. If there is an update in a BackingImage, the image will send a signal to the channel. Then there is another goroutine receive the channel and notify the longhorn manager via the streaming created by API `Watch`.
|
|
||||||
|
|
||||||
#### longhorn-ui:
|
|
||||||
1. Launch a new page to present and operate BackingImages.
|
|
||||||
1. Add button `Create Backing Image` on the top right of the page:
|
|
||||||
- Field `name` is required and should be unique.
|
|
||||||
- Field `sourceType` is required and accept an enum value. This indicates how Longhorn can get the backing image file. Right now there are 2 options: `download`, `upload`. In the future, it can be value `longhorn-volume`.
|
|
||||||
- Field `parameters` is a string map and is determined by `sourceType`. If the source type is `download`, the map should contain key `url`, whose value is the actual download address. If the source type is `upload`, the map is empty.
|
|
||||||
- Field `expectedChecksum` is optional. The user can specify the SHA512 checksum of the backing image. When the backing image fetched by Longhorn doesn't match the non-empty expected value, the backing image won't be `ready`.
|
|
||||||
2. If the source type of the creation API is `upload`, UI should send a `upload` request with the actual file data when the upload server is ready for receiving. The upload server ready is represented by first disk file state becoming `starting`. UI can check the state and wait for up to 30 seconds before sending the request.
|
|
||||||
3. Support batch deletion: Allow selecting multiple BackingImages; Add button `Deletion` on the top left.
|
|
||||||
4. The columns on BackingImage list page should be: Name, Size, Created From (field `sourceType`), Operation.
|
|
||||||
5. Show more info for each BackingImage after clicking the name:
|
|
||||||
- Present `Created From` (field `sourceType`) and the corresponding parameters `Parameters During Creation` (field `parameters`).
|
|
||||||
- If `sourceType` is `download`, present `DOWNLOAD FROM URL` instead.
|
|
||||||
- Show fields `expectedChecksum` and `currentChecksum` as `Expected SHA512 Checksum` and `Current SHA512 Checksum`. If `expectedChecksum` is empty, there is no need to show `Expected SHA512 Checksum`.
|
|
||||||
- Use a table to present the file status for each disk based on fields `diskFileStatusMap`:
|
|
||||||
- `diskFileStatusMap[diskUUID].progress` will be shown only when the state is `in-progress`.
|
|
||||||
- Add a tooltip to present `diskFileStatusMap[diskUUID].message` if it's not empty.
|
|
||||||
6. Add the following operations under button `Operation`:
|
|
||||||
- `Delete`: No field is required. It should be disabled when there is one replica using the BackingImage.
|
|
||||||
- `Clean Up`: A disk file table will be presented. Users can choose the entries of this table as the input `disks` of API `CleanupDiskImages`. This API is dedicated for manually cleaning up the images in some disks in advance.
|
|
||||||
7. When a BackingImage is being deleted (field `deletionTimestamp` is not empty), show an icon behind the name which indicates the deletion state.
|
|
||||||
8. If the state of all disk records are `failed`, use an icon behind the name to indicates the BackingImage unavailable.
|
|
||||||
2. Allow choosing a BackingImage for volume creation.
|
|
||||||
3. Modify Backup page for BackingImage:
|
|
||||||
- Allow choosing/re-specifying a new BackingImage for restore/DR volume creation:
|
|
||||||
- If there is BackingImage info in the backup volume, an option `Use previous backing image` will be shown and checked by default.
|
|
||||||
- If the option is unchecked by users, UI will show the BackingImage list so that users can pick up it.
|
|
||||||
- Add a button `Backing Image Info` in the operation list:
|
|
||||||
- If the backing image name of a BackupVolume is empty, gray out the button.
|
|
||||||
- Otherwise, present the backing image name and the backing image checksum.
|
|
||||||
|
|
||||||
| HTTP Endpoint | Operation |
|
|
||||||
| -------------------------------------------------------------- | ------------------------------------------------------------------------ |
|
|
||||||
| **GET** `/v1/backingimages` | Click button `Backing Image` |
|
|
||||||
| **POST** `/v1/backingimages/` | Click button `Create Backing Image` |
|
|
||||||
| **DELETE** `/v1/backingimages/{name}` | Click button `Delete` |
|
|
||||||
| **GET** `/v1/backingimages/{name}` | Click the `name` of a backing image |
|
|
||||||
| **POST** `/v1/backingimages/{name}?action=backingImageCleanup` | Click button`Clean Up` |
|
|
||||||
| **POST** `/v1/backingimages/{name}?action=upload` | Longhorn UI should call it automatically when the upload server is ready |
|
|
||||||
|
|
||||||
### Test Plan
|
|
||||||
#### Integration tests
|
|
||||||
1. Backing image basic operation
|
|
||||||
2. Backing image auto cleanup
|
|
||||||
3. Backing image with disk migration
|
|
||||||
|
|
||||||
#### Manual tests
|
|
||||||
1. The backing image on a down node
|
|
||||||
2. The backing image works fine with system upgrade & backing image manager upgrade
|
|
||||||
3. The incompatible backing image manager handling
|
|
||||||
4. The error presentation of a failed backing image
|
|
||||||
|
|
||||||
### Upgrade strategy
|
|
||||||
N/A
|
|
||||||
|
|
||||||
@ -1,335 +0,0 @@
|
|||||||
# Support CSI Volume Cloning
|
|
||||||
|
|
||||||
## Summary
|
|
||||||
|
|
||||||
We want to support CSI volume cloning so users can create a new PVC that has identical data as a source PVC.
|
|
||||||
|
|
||||||
|
|
||||||
### Related Issues
|
|
||||||
|
|
||||||
https://github.com/longhorn/longhorn/issues/1815
|
|
||||||
|
|
||||||
## Motivation
|
|
||||||
|
|
||||||
### Goals
|
|
||||||
|
|
||||||
* Support exporting the snapshot data of a volume
|
|
||||||
* Allow user to create a PVC with identical data as the source PVC
|
|
||||||
|
|
||||||
## Proposal
|
|
||||||
|
|
||||||
There are multiple parts in implementing this feature:
|
|
||||||
|
|
||||||
### Sparse-tools
|
|
||||||
Implement a function that fetches data from a readable object then sends it to a remote server via HTTP.
|
|
||||||
|
|
||||||
### Longhorn engine
|
|
||||||
* Implementing `VolumeExport()` gRPC in replica SyncAgentServer.
|
|
||||||
When called, `VolumeExport()` exports volume data at the input snapshot to the receiver on the remote host.
|
|
||||||
* Implementing `SnapshotCloneCmd()` and `SnapshotCloneStatusCmd()` CLIs. Longhorn manager can trigger the volume cloning process by
|
|
||||||
calling `SnapshotCloneCmd()` on the replica of new volume.
|
|
||||||
Longhorn manager can fetch the cloning status by calling `SnapshotCloneStatusCmd()` on the replica of the new volume.
|
|
||||||
|
|
||||||
### Longhorn manager
|
|
||||||
|
|
||||||
* When the volume controller detects that a volume clone is needed, it will attach the target volume.
|
|
||||||
Start 1 replica for the target volume.
|
|
||||||
Auto-attach the source volume if needed.
|
|
||||||
Take a snapshot of the source volume.
|
|
||||||
Copy the snapshot from a replica of the source volume to the new replica by calling `SnapshotCloneCmd()`.
|
|
||||||
After the snapshot was copied over to the replica of the new volume, the volume controller marks volume as completed cloning.
|
|
||||||
|
|
||||||
* Once the cloning is done, the volume controller detaches the source volume if it was auto attached.
|
|
||||||
Detach the target volume to allow the workload to start using it.
|
|
||||||
Later on, when the target volume is attached by workload pod, Longhorn will start rebuilding other replicas.
|
|
||||||
|
|
||||||
### Longhorn CSI plugin
|
|
||||||
* Advertise that Longhorn CSI driver has ability to clone a volume, `csi.ControllerServiceCapability_RPC_CLONE_VOLUME`
|
|
||||||
* When receiving a volume creat request, inspect `req.GetVolumeContentSource()` to see if it is from another volume.
|
|
||||||
If so, create a new Longhorn volume with appropriate `DataSource` set so Longhorn volume controller can start cloning later on.
|
|
||||||
|
|
||||||
|
|
||||||
### User Stories
|
|
||||||
|
|
||||||
Before this feature, to create a new PVC with the same data as another PVC, the users would have to use one of the following methods:
|
|
||||||
1. Create a backup of the source volume. Restore the backup to a new volume.
|
|
||||||
Create PV/PVC for the new volume. This method requires a backup target.
|
|
||||||
Data has to move through an extra layer (the backup target) which might cost money.
|
|
||||||
1. Create a new PVC (that leads to creating a new Longhorn volume).
|
|
||||||
Mount both new PVC and source PVC to the same pod then copy the data over.
|
|
||||||
See more [here](https://github.com/longhorn/longhorn/blob/v1.1.2/examples/data_migration.yaml).
|
|
||||||
This copying method only applied for PVC with `Filesystem` volumeMode. Also, it requires manual steps.
|
|
||||||
|
|
||||||
After this cloning feature, users can clone a volume by specifying `dataSource` in the new PVC pointing to an existing PVC.
|
|
||||||
|
|
||||||
### User Experience In Detail
|
|
||||||
|
|
||||||
Users can create a new PVC that uses `longhorn` storageclass from an existing PVC which also uses `longhorn` storageclass by
|
|
||||||
specifying `dataSource` in new PVC pointing to the existing PVC:
|
|
||||||
|
|
||||||
```yaml
|
|
||||||
apiVersion: v1
|
|
||||||
kind: PersistentVolumeClaim
|
|
||||||
metadata:
|
|
||||||
name: clone-pvc
|
|
||||||
namespace: myns
|
|
||||||
spec:
|
|
||||||
accessModes:
|
|
||||||
- ReadWriteOnce
|
|
||||||
storageClassName: longhorn
|
|
||||||
resources:
|
|
||||||
requests:
|
|
||||||
storage: 5Gi
|
|
||||||
dataSource:
|
|
||||||
kind: PersistentVolumeClaim
|
|
||||||
name: source-pvc
|
|
||||||
```
|
|
||||||
|
|
||||||
### API changes
|
|
||||||
|
|
||||||
`VolumeCreate` API will check/validate data a new field, `DataSource` which is a new field in `v.Spec` that
|
|
||||||
specifies the source of the Longhorn volume.
|
|
||||||
|
|
||||||
## Design
|
|
||||||
|
|
||||||
### Implementation Overview
|
|
||||||
|
|
||||||
### Sparse-tools
|
|
||||||
Implement a generalized function, `SyncContent()`, which syncs the content of a `ReaderWriterAt` object to a file on remote host.
|
|
||||||
The `ReaderWriterAt` is interface that has `ReadAt()`, `WriteAt()` and `GetDataLayout()` method:
|
|
||||||
```go
|
|
||||||
type ReaderWriterAt interface {
|
|
||||||
io.ReaderAt
|
|
||||||
io.WriterAt
|
|
||||||
GetDataLayout (ctx context.Context) (<-chan FileInterval, <-chan error, error)
|
|
||||||
}
|
|
||||||
```
|
|
||||||
Using those methods, the Sparse-tools know where is a data/hole interval to transfer to a file on the remote host.
|
|
||||||
|
|
||||||
### Longhorn engine
|
|
||||||
* Implementing `VolumeExport()` gRPC in replica SyncAgentServer. When called, `VolumeExport()` will:
|
|
||||||
* Create and open a read-only replica from the input snapshot
|
|
||||||
* Pre-load `r.volume.location` (which is the map of data sector to snapshot file) by:
|
|
||||||
* If the volume has backing file layer and users want to export the backing file layer,
|
|
||||||
we initialize all elements of `r.volume.location` to 1 (the index of the backing file layer).
|
|
||||||
Otherwise, initialize all elements of `r.volume.location` to 0 (0 means we don't know the location for this sector yet)
|
|
||||||
* Looping over `r.volume.files` and populates `r.volume.location` (which is the map of data sector to snapshot file) with correct values.
|
|
||||||
* The replica is able to know which region is data/hole region.
|
|
||||||
This logic is implemented inside the replica's method `GetDataLayout()`.
|
|
||||||
The method checks `r.volume.location`.
|
|
||||||
The sector at offset `i` is in data region if `r.volume.location[i] >= 1`.
|
|
||||||
Otherwise, the sector is inside a hole region.
|
|
||||||
* Call and pass the read-only replica into `SyncContent()` function in the Sparse-tools module to copy the snapshot to a file on the remote host.
|
|
||||||
|
|
||||||
* Implementing `SnapshotCloneCmd()` and `SnapshotCloneStatusCmd()` CLIs.
|
|
||||||
* Longhorn manager can trigger the volume cloning process by calling `SnapshotCloneCmd()` on the replica of the new volume.
|
|
||||||
The command finds a healthy replica of the source volume by listing replicas of the source controller and selecting a `RW` replica.
|
|
||||||
The command then calls `CloneSnapshot()` method on replicas of the target volumes. This method in turn does:
|
|
||||||
* Call `SnapshotClone()` on the sync agent of the target replica.
|
|
||||||
This will launch a receiver server on the target replica.
|
|
||||||
Call `VolumeExport()` on the sync agent of the source replica to export the snapshot data to the target replica.
|
|
||||||
Once the snapshot data is copied over, revert the target replica to the newly copied snapshot.
|
|
||||||
* Longhorn manager can fetch cloning status by calling `SnapshotCloneStatusCmd()` on the target replica.
|
|
||||||
|
|
||||||
### Longhorn manager
|
|
||||||
* Add a new field to volume spec, `DataSource`. The `DataSource` is of type `VolumeDataSource`.
|
|
||||||
Currently, there are 2 types of data sources: `volume` type and `snapshot` type.
|
|
||||||
`volume` data source type has the format `vol://<VOLUME-NAME>`.
|
|
||||||
`snapshot` data source type has the format `snap://<VOLUME-NAME>/<SNAPSHOT-NAME>`.
|
|
||||||
In the future, we might want to refactor `fromBackup` field into a new type of data source with format `bk://<VOLUME-NAME>/<BACKUP-NAME>`.
|
|
||||||
|
|
||||||
* Add a new field into volume status, `CloneStatus` of type `VolumeCloneStatus`:
|
|
||||||
```go
|
|
||||||
type VolumeCloneStatus struct {
|
|
||||||
SourceVolume string `json:"sourceVolume"`
|
|
||||||
Snapshot string `json:"snapshot"`
|
|
||||||
State VolumeCloneState `json:"state"`
|
|
||||||
}
|
|
||||||
type VolumeCloneState string
|
|
||||||
const (
|
|
||||||
VolumeCloneStateEmpty = VolumeCloneState("")
|
|
||||||
VolumeCloneStateInitiated = VolumeCloneState("initiated")
|
|
||||||
VolumeCloneStateCompleted = VolumeCloneState("completed")
|
|
||||||
VolumeCloneStateFailed = VolumeCloneState("failed")
|
|
||||||
)
|
|
||||||
```
|
|
||||||
|
|
||||||
* Add a new field into engine spec, `RequestedDataSource` of type `VolumeDataSource`
|
|
||||||
|
|
||||||
* Add a new field into engine status, `CloneStatus`.
|
|
||||||
`CloneStatus` is a map of `SnapshotCloneStatus` inside each replica:
|
|
||||||
```go
|
|
||||||
type SnapshotCloneStatus struct {
|
|
||||||
IsCloning bool `json:"isCloning"`
|
|
||||||
Error string `json:"error"`
|
|
||||||
Progress int `json:"progress"`
|
|
||||||
State string `json:"state"`
|
|
||||||
FromReplicaAddress string `json:"fromReplicaAddress"`
|
|
||||||
SnapshotName string `json:"snapshotName"`
|
|
||||||
}
|
|
||||||
```
|
|
||||||
This will keep track of status of snapshot cloning inside the target replica.
|
|
||||||
* When the volume controller detect that a volume clone is needed
|
|
||||||
(`v.Spec.DataSource` is `volume` or `snapshot` type and `v.Status.CloneStatus.State == VolumeCloneStateEmpty`),
|
|
||||||
it will auto attach the source volume if needed.
|
|
||||||
Take a snapshot of the source volume if needed.
|
|
||||||
Fill the `v.Status.CloneStatus` with correct value for `SourceVolume`, `Snapshot`, and `State`(`initiated`).
|
|
||||||
Auto attach the target volume.
|
|
||||||
Start 1 replica for the target volume.
|
|
||||||
Set `e.Spec.RequestedDataSource` to the correct value, `snap://<SOURCE-VOL-NAME/<SNAPSHOT-NAME>`.
|
|
||||||
|
|
||||||
* Engine controller monitoring loop will start the snapshot clone by calling `SnapshotCloneCmd()`.
|
|
||||||
|
|
||||||
* After the snapshot is copied over to the replica of the new volume, volume controller marks `v.Status.CloneStatus.State = VolumeCloneStateCompleted`
|
|
||||||
and clear the `e.Spec.RequestedDataSource`
|
|
||||||
|
|
||||||
* Once the cloning is done, the volume controller detaches the source volume if it was auto attached.
|
|
||||||
Detach the target volume to allow the workload to start using it.
|
|
||||||
|
|
||||||
* When workload attach volume, Longhorn starts rebuilding other replicas of the volume.
|
|
||||||
|
|
||||||
### Longhorn CSI plugin
|
|
||||||
* Advertise that Longhorn CSI driver has ability to clone a volume, `csi.ControllerServiceCapability_RPC_CLONE_VOLUME`
|
|
||||||
* When receiving a volume creat request, inspect `req.GetVolumeContentSource()` to see if it is from another volume.
|
|
||||||
If so, create a new Longhorn volume with appropriate `DataSource` set so Longhorn volume controller can start cloning later on.
|
|
||||||
|
|
||||||
### Test plan
|
|
||||||
|
|
||||||
Integration test plan.
|
|
||||||
|
|
||||||
#### Clone volume that doesn't have backing image
|
|
||||||
1. Create a PVC:
|
|
||||||
```yaml
|
|
||||||
apiVersion: v1
|
|
||||||
kind: PersistentVolumeClaim
|
|
||||||
metadata:
|
|
||||||
name: source-pvc
|
|
||||||
spec:
|
|
||||||
storageClassName: longhorn
|
|
||||||
accessModes:
|
|
||||||
- ReadWriteOnce
|
|
||||||
resources:
|
|
||||||
requests:
|
|
||||||
storage: 10Gi
|
|
||||||
```
|
|
||||||
1. Specify the `source-pvc` in a pod yaml and start the pod
|
|
||||||
1. Wait for the pod to be running, write some data to the mount path of the volume
|
|
||||||
1. Clone a volume by creating the PVC:
|
|
||||||
```yaml
|
|
||||||
apiVersion: v1
|
|
||||||
kind: PersistentVolumeClaim
|
|
||||||
metadata:
|
|
||||||
name: cloned-pvc
|
|
||||||
spec:
|
|
||||||
storageClassName: longhorn
|
|
||||||
dataSource:
|
|
||||||
name: source-pvc
|
|
||||||
kind: PersistentVolumeClaim
|
|
||||||
accessModes:
|
|
||||||
- ReadWriteOnce
|
|
||||||
resources:
|
|
||||||
requests:
|
|
||||||
storage: 10Gi
|
|
||||||
```
|
|
||||||
1. Specify the `cloned-pvc` in a cloned pod yaml and deploy the cloned pod
|
|
||||||
1. Wait for the `CloneStatus.State` in `cloned-pvc` to be `completed`
|
|
||||||
1. In 3-min retry loop, wait for the cloned pod to be running
|
|
||||||
1. Verify the data in `cloned-pvc` is the same as in `source-pvc`
|
|
||||||
1. In 2-min retry loop, verify the volume of the `clone-pvc` eventually becomes healthy
|
|
||||||
1. Cleanup the cloned pod, `cloned-pvc`. Wait for the cleaning to finish
|
|
||||||
1. Scale down the source pod so the `source-pvc` is detached.
|
|
||||||
1. Wait for the `source-pvc` to be in detached state
|
|
||||||
1. Clone a volume by creating the PVC:
|
|
||||||
```yaml
|
|
||||||
apiVersion: v1
|
|
||||||
kind: PersistentVolumeClaim
|
|
||||||
metadata:
|
|
||||||
name: cloned-pvc
|
|
||||||
spec:
|
|
||||||
storageClassName: longhorn
|
|
||||||
dataSource:
|
|
||||||
name: source-pvc
|
|
||||||
kind: PersistentVolumeClaim
|
|
||||||
accessModes:
|
|
||||||
- ReadWriteOnce
|
|
||||||
resources:
|
|
||||||
requests:
|
|
||||||
storage: 10Gi
|
|
||||||
```
|
|
||||||
1. Specify the `cloned-pvc` in a cloned pod yaml and deploy the cloned pod
|
|
||||||
1. Wait for `source-pvc` to be attached
|
|
||||||
1. Wait for a new snapshot created in `source-pvc` volume created
|
|
||||||
1. Wait for the `CloneStatus.State` in `cloned-pvc` to be `completed`
|
|
||||||
1. Wait for `source-pvc` to be detached
|
|
||||||
1. In 3-min retry loop, wait for the cloned pod to be running
|
|
||||||
1. Verify the data in `cloned-pvc` is the same as in `source-pvc`
|
|
||||||
1. In 2-min retry loop, verify the volume of the `clone-pvc` eventually becomes healthy
|
|
||||||
1. Cleanup the test
|
|
||||||
|
|
||||||
#### Clone volume that has backing image
|
|
||||||
1. Deploy a storage class that has backing image parameter
|
|
||||||
```yaml
|
|
||||||
kind: StorageClass
|
|
||||||
apiVersion: storage.k8s.io/v1
|
|
||||||
metadata:
|
|
||||||
name: longhorn-bi-parrot
|
|
||||||
provisioner: driver.longhorn.io
|
|
||||||
allowVolumeExpansion: true
|
|
||||||
parameters:
|
|
||||||
numberOfReplicas: "3"
|
|
||||||
staleReplicaTimeout: "2880" # 48 hours in minutes
|
|
||||||
backingImage: "bi-parrot"
|
|
||||||
backingImageURL: "https://longhorn-backing-image.s3-us-west-1.amazonaws.com/parrot.qcow2"
|
|
||||||
```
|
|
||||||
Repeat the `Clone volume that doesn't have backing image` test with `source-pvc` and `cloned-pvc` use `longhorn-bi-parrot` instead of `longhorn` storageclass
|
|
||||||
|
|
||||||
#### Interrupt volume clone process
|
|
||||||
|
|
||||||
1. Create a PVC:
|
|
||||||
```yaml
|
|
||||||
apiVersion: v1
|
|
||||||
kind: PersistentVolumeClaim
|
|
||||||
metadata:
|
|
||||||
name: source-pvc
|
|
||||||
spec:
|
|
||||||
storageClassName: longhorn
|
|
||||||
accessModes:
|
|
||||||
- ReadWriteOnce
|
|
||||||
resources:
|
|
||||||
requests:
|
|
||||||
storage: 10Gi
|
|
||||||
```
|
|
||||||
1. Specify the `source-pvc` in a pod yaml and start the pod
|
|
||||||
1. Wait for the pod to be running, write 1GB of data to the mount path of the volume
|
|
||||||
1. Clone a volume by creating the PVC:
|
|
||||||
```yaml
|
|
||||||
apiVersion: v1
|
|
||||||
kind: PersistentVolumeClaim
|
|
||||||
metadata:
|
|
||||||
name: cloned-pvc
|
|
||||||
spec:
|
|
||||||
storageClassName: longhorn
|
|
||||||
dataSource:
|
|
||||||
name: source-pvc
|
|
||||||
kind: PersistentVolumeClaim
|
|
||||||
accessModes:
|
|
||||||
- ReadWriteOnce
|
|
||||||
resources:
|
|
||||||
requests:
|
|
||||||
storage: 10Gi
|
|
||||||
```
|
|
||||||
1. Specify the `cloned-pvc` in a cloned pod yaml and deploy the cloned pod
|
|
||||||
1. Wait for the `CloneStatus.State` in `cloned-pvc` to be `initiated`
|
|
||||||
1. Kill all replicas process of the `source-pvc`
|
|
||||||
1. Wait for the `CloneStatus.State` in `cloned-pvc` to be `failed`
|
|
||||||
1. In 2-min retry loop, verify cloned pod cannot start
|
|
||||||
1. Clean up cloned pod and `clone-pvc`
|
|
||||||
1. Redeploy `cloned-pvc` and clone pod
|
|
||||||
1. In 3-min retry loop, verify cloned pod become running
|
|
||||||
2. `cloned-pvc` has the same data as `source-pvc`
|
|
||||||
1. Cleanup the test
|
|
||||||
|
|
||||||
### Upgrade strategy
|
|
||||||
|
|
||||||
No upgrade strategy needed
|
|
||||||
|
|
||||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user