Add LEP for rwx feature
Longhorn #1470 Signed-off-by: Joshua Moody <joshua.moody@rancher.com>
This commit is contained in:
parent
7c78b28314
commit
f45f0512dc
212
enhancements/20201220-rwx-volume-support.md
Normal file
212
enhancements/20201220-rwx-volume-support.md
Normal file
@ -0,0 +1,212 @@
|
||||
# RWX volume support
|
||||
|
||||
## Summary
|
||||
|
||||
We want to natively support RWX volumes, the creation and usage of these rwx volumes should preferably be transparent to the user.
|
||||
This would make it so that there is no manual user interaction necessary, and a rwx volume just looks the same as regular Longhorn volume.
|
||||
This would also allow any Longhorn volume to be used as rwx, without special requirements.
|
||||
|
||||
### Related Issues
|
||||
|
||||
https://github.com/longhorn/longhorn/issues/1470
|
||||
https://github.com/Longhorn/Longhorn/issues/1183
|
||||
|
||||
## Motivation
|
||||
### Goals
|
||||
|
||||
- support creation of RWX volumes via Longhorn
|
||||
- support creation of RWX volumes via RWX pvc's
|
||||
- support mounting NFS shares via the CSI driver
|
||||
- creation of a share-manager that manages and exports volumes via NFS
|
||||
|
||||
### Non-goals
|
||||
|
||||
- clustered NFS (highly available)
|
||||
- distributed filesystem
|
||||
|
||||
## Proposal
|
||||
|
||||
RWX volumes should support all operations that a regular RWO volumes supports (backup & restore, DR volume support, etc)
|
||||
|
||||
### User Stories
|
||||
#### Native RWX support
|
||||
Before this enhancement we create an RWX provisioner example that was using a regular Longhorn volume to export multiple NFS shares.
|
||||
The provisioner then created native kubernetes NFS persistent volumes, there where many limitations with this approach (multiple workload pvs on one Longhorn volume, restore & backup is iffy, etc)
|
||||
|
||||
After this enhancement anytime a user uses an RWX pvc we will provision a Longhorn volume and expose the volume via a share-manager.
|
||||
The CSI driver will then mount this volume that is exported via a NFS server from the share-manager pod.
|
||||
|
||||
|
||||
### User Experience In Detail
|
||||
|
||||
Users can automatically provision and use an RWX volume by having their workload use an RWX pvc.
|
||||
Users can see the status of their RWX volumes in the Longhorn UI, same as for RWO volumes.
|
||||
Users can use the created RWX volume on different nodes at the same time.
|
||||
|
||||
|
||||
### API changes
|
||||
- add `AccessMode` field to the `Volume.Spec`
|
||||
- add `ShareEndpoint, ShareState` fields to the `Volume.Status`
|
||||
- add a new ShareManager crd, details below
|
||||
|
||||
```go
|
||||
type ShareManagerState string
|
||||
|
||||
const (
|
||||
ShareManagerStateUnknown = ShareManagerState("unknown")
|
||||
ShareManagerStateStarting = ShareManagerState("starting")
|
||||
ShareManagerStateRunning = ShareManagerState("running")
|
||||
ShareManagerStateStopped = ShareManagerState("stopped")
|
||||
ShareManagerStateError = ShareManagerState("error")
|
||||
)
|
||||
|
||||
type ShareManagerSpec struct {
|
||||
Image string `json:"image"`
|
||||
}
|
||||
|
||||
type ShareManagerStatus struct {
|
||||
OwnerID string `json:"ownerID"`
|
||||
State ShareManagerState `json:"state"`
|
||||
Endpoint string `json:"endpoint"`
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
### Implementation Overview
|
||||
|
||||
#### Key Components
|
||||
- Volume controller is responsible for creation of share manager crd and synchronising share status and endpoint of the volume with the share manager resource.
|
||||
- Share manager controller will be responsible for managing share manager pods and ensuring volume attachment to the share manager pod.
|
||||
- Share manager pod is responsible for health checking and managing the NFS server volume export.
|
||||
- CSI driver is responsible for mounting the NFS export to the workload pod
|
||||
|
||||
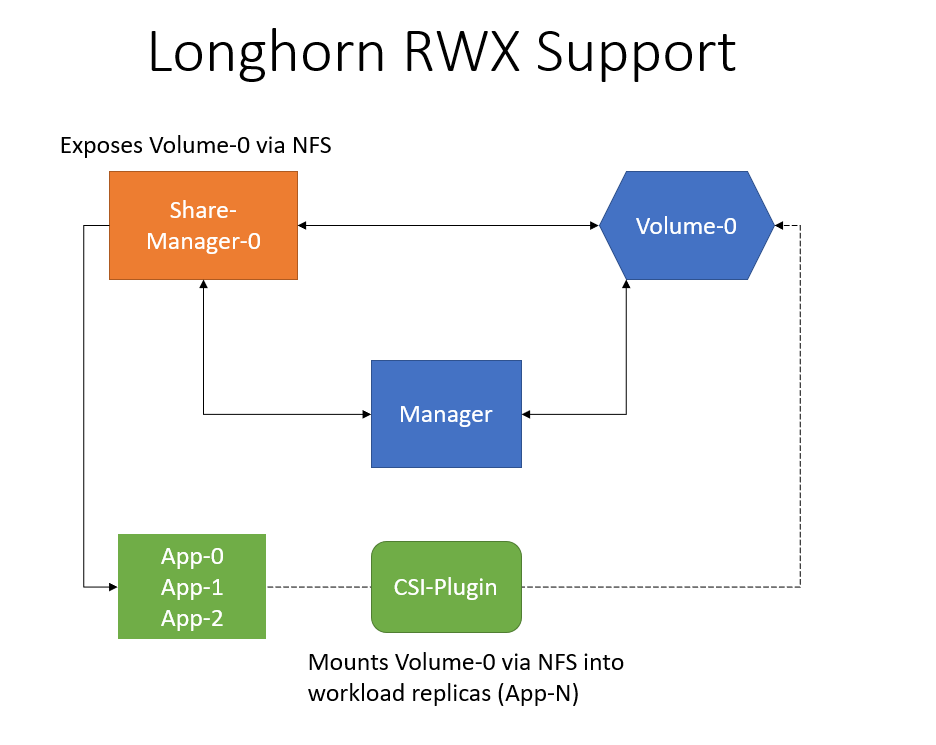
|
||||
|
||||
#### From volume creation to usage
|
||||
When a new RWX volume with name `test-volume` is created, the volume controller will create a matching share-manager resource with name `test-volume`.
|
||||
The share-manager-controller will pickup this new share-manager resource and create share-manager pod with name `share-manager-test-volume` in the longhorn-system namespace,
|
||||
as well as a service named `test-volume` that always points to the share-manager-pod `share-manager-test-volume`.
|
||||
The controller will set the `State=Starting` while the share-manager-pod is Pending and not `Ready` yet.
|
||||
|
||||
The share-manager-pod is running our share-manager image which allows for exporting a block device via ganesha (NFS server).
|
||||
After starting the share-manager, the application waits for the attachment of the volume `test-volume`,
|
||||
this is done by an availability check of the block device in the bind-mounted `/host/dev/longhorn/test-volume` folder.
|
||||
|
||||
The actual volume attachment is handled by the share-manager-controller setting volume.spec.nodeID to the `node` of the share-manager-pod.
|
||||
Once the volume is attached the share-manager will mount the volume, create export config and start ganesha (NFS server).
|
||||
Afterwards the share-manager will do periodic health check against the attached volume and on failure of a health check the pod will terminate.
|
||||
The share-manager pod will become `ready` as soon as ganesha is up and running this is accomplished via a check against `/var/run/ganesha.pid`.
|
||||
|
||||
The share-manager-controller can now update the share-manager `State=Running` and `Endpoint=nfs://service-cluster-ip/test-volume"`.
|
||||
The volume-controller will update the volumes `ShareState` and `ShareEndpoint` based on the values of the share-manager `State` and `Endpoint`.
|
||||
Once the volumes `ShareState` is `Running` the csi-driver can now successfully attach & mount the volume into the workload pods.
|
||||
|
||||
#### Recovering from share-manager node/volume/pod failures
|
||||
On node failure Kubernetes will mark the share-manager-pod `share-manager-test-volume` as terminating.
|
||||
The share-manager-controller will mark the share-manager `State=Error` if the share-manager pod is in any state other than `Running` or `Pending`, unless
|
||||
the share-manager is no longer required for this volume (no workloads consuming this volume).
|
||||
|
||||
When the share-manager `State` is `Error` the volume-controller will continuously set the volumes `RemountRequestedAt=Now` so that we will cleanup the workload pods
|
||||
till the share-manager is back in order. This cleanup is to force the workload pods to initiate a new connection against the NFS server.
|
||||
In the future we hope to reuse the NFS connection which will make this step no longer necessary.
|
||||
|
||||
The share-manager-controller will start a new share-manager pod on a different node and set `State=Starting`.
|
||||
Once the pod is `Ready` the controller will set `State=Running` and the workload pods are now able to reconnect/remount again.
|
||||
See above for the complete flow from `Starting -> Ready -> Running -> volume share available`
|
||||
|
||||
### Test plan
|
||||
|
||||
- [Manual tests for RWX feature](https://github.com/longhorn/longhorn-tests/pull/496)
|
||||
- [E2E tests for RWX feature](https://github.com/longhorn/longhorn-tests/pull/512)
|
||||
|
||||
### Upgrade strategy
|
||||
- User needs to add a new share-manager-image to airgapped environments
|
||||
- Created a [migration job](https://longhorn.io/docs/1.1.0/advanced-resources/rwx-workloads/#migration-from-previous-external-provisioner) to allow users to migrate data from previous NFS provisioner or other RWO volumes
|
||||
|
||||
## Information & References
|
||||
|
||||
### NFS ganesha details
|
||||
- [overview grace period and recovery](https://www.programmersought.com/article/19554210230/)
|
||||
- [code grace period and recovery](https://www.programmersought.com/article/53201520803/)
|
||||
- [code & architecture overview](https://www.programmersought.com/article/12291336147/)
|
||||
- [kernel server vs ganesha](https://events.static.linuxfound.org/sites/events/files/slides/Collab14_nfsGanesha.pdf)
|
||||
|
||||
### NFS ganesha DBUS
|
||||
- [DBUS-Interface](https://github.com/nfs-ganesha/nfs-ganesha/wiki/Dbusinterface#orgganeshanfsdadmin)
|
||||
- [DBUS-Exports](https://github.com/nfs-ganesha/nfs-ganesha/wiki/DBusExports)
|
||||
|
||||
The dbus interface can be used to add & remove exports.
|
||||
As well as make the server go into the grace period.
|
||||
|
||||
### NFS grace period
|
||||
- [NFS_lock_recovery_notes](https://linux-nfs.org/wiki/index.php/NFS_lock_recovery_notes)
|
||||
- [lower grace period](https://www.suse.com/support/kb/doc/?id=000019374)
|
||||
|
||||
### Ceph ganesha
|
||||
- [rook crd for ganesha](https://github.com/rook/rook/blob/master/design/ceph/ceph-nfs-ganesha.md)
|
||||
- [ganesha driver class library](https://docs.openstack.org/manila/rocky/contributor/ganesha.html)
|
||||
|
||||
### NFS ganesha Active Passive Setups
|
||||
- [pacemaker & drbd, suse](https://documentation.suse.com/sle-ha/12-SP4/#redirectmsg)
|
||||
- [pacemaker & corosync, redhat](https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/high_availability_add-on_administration/ch-nfsserver-haaa)
|
||||
|
||||
### NFS ganesha recovery backends
|
||||
|
||||
Rados requires ceph, some more difference between kv/ng
|
||||
- https://bugzilla.redhat.com/show_bug.cgi?id=1557465
|
||||
- https://lists.nfs-ganesha.org/archives/list/devel@lists.nfs-ganesha.org/thread/DPULRQKCGB2QQUCUMOVDOBHCPJL22QMX/
|
||||
|
||||
**rados_kv**: This is the original rados recovery backend that uses a key-
|
||||
value store. It has support for "takeover" operations: merging one
|
||||
recovery database into another such that another cluster node could take
|
||||
over addresses that were hosted on another node. Note that this recovery
|
||||
backend may not survive crashes that occur _during_ a grace period. If
|
||||
it crashes and then crashes again during the grace period, the server is
|
||||
likely to fail to allow any clients to recover (the db will be trashed).
|
||||
|
||||
**rados_ng**: a more resilient rados_kv backend. This one does not support
|
||||
takeover operations, but it should properly survive crashes that occur
|
||||
during the grace period.
|
||||
|
||||
**rados_cluster**: the new (experimental) clustered recovery backend. This
|
||||
one also does not support address takeover, but should be resilient
|
||||
enough to handle crashes that occur during the grace period.
|
||||
|
||||
FWIW, the semantics for fs vs. fs_ng are similar. fs doesn't survive
|
||||
crashes that occur during the grace period either.
|
||||
|
||||
Unless you're trying to use the dbus "grace" command to initiate address
|
||||
takeover in an active/active cluster, you probably want rados_ng for
|
||||
now.
|
||||
|
||||
### CSI lifecycle:
|
||||
```
|
||||
CreateVolume +------------+ DeleteVolume
|
||||
+------------->| CREATED +--------------+
|
||||
| +---+----^---+ |
|
||||
| Controller | | Controller v
|
||||
+++ Publish | | Unpublish +++
|
||||
|X| Volume | | Volume | |
|
||||
+-+ +---v----+---+ +-+
|
||||
| NODE_READY |
|
||||
+---+----^---+
|
||||
Node | | Node
|
||||
Stage | | Unstage
|
||||
Volume | | Volume
|
||||
+---v----+---+
|
||||
| VOL_READY |
|
||||
+---+----^---+
|
||||
Node | | Node
|
||||
Publish | | Unpublish
|
||||
Volume | | Volume
|
||||
+---v----+---+
|
||||
| PUBLISHED |
|
||||
+------------+
|
||||
```
|
||||
Figure 6: The lifecycle of a dynamically provisioned volume, from
|
||||
creation to destruction, when the Node Plugin advertises the
|
||||
STAGE_UNSTAGE_VOLUME capability.
|
||||
|
||||
### Previous Engine migration feature
|
||||
https://github.com/longhorn/longhorn-manager/commit/2636a5dc6d79aa12116e7e5685ccd831747639df
|
||||
https://github.com/longhorn/longhorn-tests/commit/3a55d6bfe633165fb6eb9553235b7d0a2e651cec
|
||||
Loading…
Reference in New Issue
Block a user