# What does this PR do? <!-- Congratulations! You've made it this far! You're not quite done yet though. Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution. Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change. Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost. --> <!-- Remove if not applicable --> Add TensorRT-LLM weight-only GEMV kernel support. We extract GEMV kernel from [TensorRT-LLM](https://github.com/NVIDIA/TensorRT-LLM/tree/main/cpp/tensorrt_llm/kernels/weightOnlyBatchedGemv) to accelerate the decode speed of EETQ when batch_size is smaller or equal to 4. - Features 1. There is almost no loss of quantization accuracy. 2. The speed of decoding is 13% - 27% faster than original EETQ which utilizes GEMM kernel. - Test Below is our test on 3090. Environment: torch=2.0.1, cuda=11.8, nvidia driver: 525.78.01 prompt=1024, max_new_tokens=50  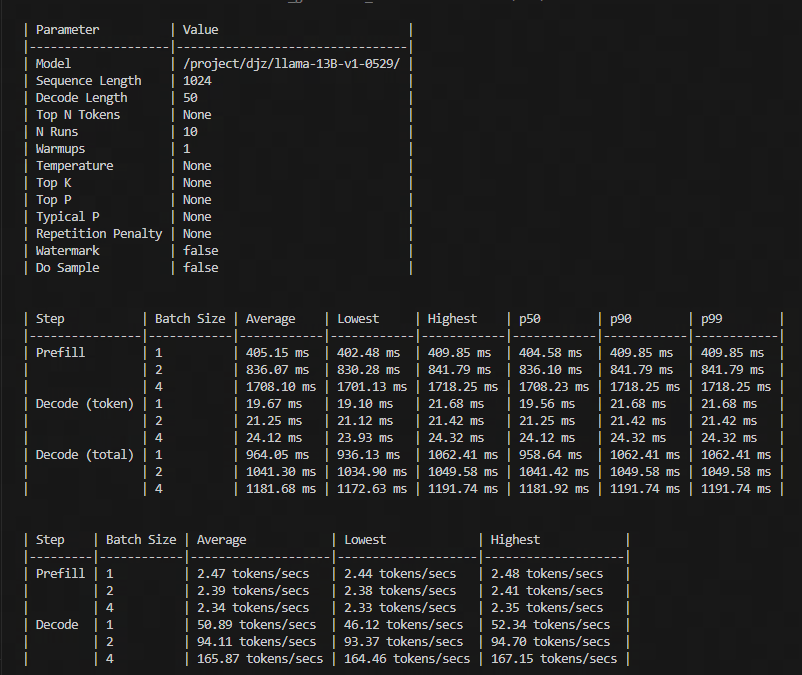 ## Before submitting - [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case). - [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests), Pull Request section? - [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link to it if that's the case. - [ ] Did you make sure to update the documentation with your changes? Here are the [documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and [here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation). - [ ] Did you write any new necessary tests? ## Who can review? Anyone in the community is free to review the PR once the tests have passed. Feel free to tag members/contributors who may be interested in your PR. <!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @ @OlivierDehaene OR @Narsil --> |
||
|---|---|---|
| .github | ||
| assets | ||
| benchmark | ||
| clients/python | ||
| docs | ||
| examples | ||
| integration-tests | ||
| launcher | ||
| load_tests | ||
| proto | ||
| router | ||
| server | ||
| .dockerignore | ||
| .gitignore | ||
| Cargo.lock | ||
| Cargo.toml | ||
| Dockerfile | ||
| Dockerfile_amd | ||
| LICENSE | ||
| Makefile | ||
| README.md | ||
| rust-toolchain.toml | ||
| sagemaker-entrypoint.sh | ||
| update_doc.py | ||
Text Generation Inference on Habana Gaudi
Table of contents
- Running TGI on Gaudi
- Adjusting TGI parameters
- Currently supported configurations
- Environment variables
- Profiler
Running TGI on Gaudi
To use 🤗 text-generation-inference on Habana Gaudi/Gaudi2, follow these steps:
- Pull the official Docker image with:
docker pull ghcr.io/huggingface/tgi-gaudi:1.2.1
Note
Alternatively, you can build the Docker image using the
Dockerfilelocated in this folder with:docker build -t tgi_gaudi .
-
Launch a local server instance:
i. On 1 Gaudi/Gaudi2 card
model=meta-llama/Llama-2-7b-hf volume=$PWD/data # share a volume with the Docker container to avoid downloading weights every run docker run -p 8080:80 -v $volume:/data --runtime=habana -e HABANA_VISIBLE_DEVICES=all -e OMPI_MCA_btl_vader_single_copy_mechanism=none --cap-add=sys_nice --ipc=host ghcr.io/huggingface/tgi-gaudi:1.2.1 --model-id $modelFor gated models such as LLama or StarCoder, you will have to pass
-e HUGGING_FACE_HUB_TOKEN=<token>to thedocker runcommand above with a valid Hugging Face Hub read token.ii. On 8 Gaudi/Gaudi2 cards:
model=meta-llama/Llama-2-70b-hf volume=$PWD/data # share a volume with the Docker container to avoid downloading weights every run docker run -p 8080:80 -v $volume:/data --runtime=habana -e PT_HPU_ENABLE_LAZY_COLLECTIVES=true -e HABANA_VISIBLE_DEVICES=all -e OMPI_MCA_btl_vader_single_copy_mechanism=none --cap-add=sys_nice --ipc=host ghcr.io/huggingface/tgi-gaudi:1.2.1 --model-id $model --sharded true --num-shard 8 -
You can then send a simple request:
curl 127.0.0.1:8080/generate \ -X POST \ -d '{"inputs":"What is Deep Learning?","parameters":{"max_new_tokens":32}}' \ -H 'Content-Type: application/json' -
To run static benchmark test, please refer to TGI's benchmark tool.
To run it on the same machine, you can do the following:
docker exec -it <docker name> bash, pick the docker started from step 2 using docker pstext-generation-benchmark -t <model-id>, pass the model-id from docker run command- after the completion of tests, hit ctrl+c to see the performance data summary.
-
To run continuous batching test, please refer to examples.
Adjusting TGI parameters
Maximum sequence length is controlled by two arguments:
--max-input-lengthis the maximum possible input prompt length. Default value is1024.--max-total-tokensis the maximum possible total length of the sequence (input and output). Default value is2048.
Maximum batch size is controlled by two arguments:
- For prefill operation, please set
--max-prefill-total-tokensasbs * max-input-length, wherebsis your expected maximum prefill batch size. - For decode operation, please set
--max-batch-total-tokensasbs * max-total-tokens, wherebsis your expected maximum decode batch size. - Please note that batch size will be always padded to the nearest multiplication of
BATCH_BUCKET_SIZEandPREFILL_BATCH_BUCKET_SIZE.
To ensure greatest performance results, at the begginging of each server run, warmup is performed. It's designed to cover major recompilations while using HPU Graphs. It creates queries with all possible input shapes, based on provided parameters (described in this section) and runs basic TGI operations on them (prefill, decode, concatenate).
Except those already mentioned, there are other parameters that need to be properly adjusted to improve performance or memory usage:
PAD_SEQUENCE_TO_MULTIPLE_OFdetermines sizes of input legnth buckets. Since warmup creates several graphs for each bucket, it's important to adjust that value proportionally to input sequence length. Otherwise, some out of memory issues can be observed.ENABLE_HPU_GRAPHenables HPU graphs usage, which is crucial for performance results. Recommended value to keep istrue.
For more information and documentation about Text Generation Inference, checkout the README of the original repo.
Currently supported configurations
Not all features of TGI are currently supported as this is still a work in progress. Currently supported and validated configurations (other configurations are not guaranted to work or ensure reasonable performance ):
-
LLaMA 70b:
- Num cards: 8
- Decode batch size: 128
- Dtype: bfloat16
- Max input tokens: 1024
- Max total tokens: 2048
-
LLaMA 7b:
- Num cards: 1
- Decode batch size: 16
- Dtype: bfloat16
- Max input tokens: 1024
- Max total tokens: 2048
Other sequence lengths can be used with proportionally decreased/increased batch size (the higher sequence length, the lower batch size). Support for other models from Optimum Habana will be added successively.
Environment variables
| Name | Value(s) | Default | Description | Usage |
|---|---|---|---|---|
| ENABLE_HPU_GRAPH | True/False | True | Enable hpu graph or not | add -e in docker run command |
| LIMIT_HPU_GRAPH | True/False | False | Skip HPU graph usage for prefill to save memory, set to True for large sequence/decoding lengths(e.g. 300/212) |
add -e in docker run command |
| BATCH_BUCKET_SIZE | integer | 8 | Batch size for decode operation will be rounded to the nearest multiple of this number. This limits the number of cached graphs | add -e in docker run command |
| PREFILL_BATCH_BUCKET_SIZE | integer | 4 | Batch size for prefill operation will be rounded to the nearest multiple of this number. This limits the number of cached graphs | add -e in docker run command |
| PAD_SEQUENCE_TO_MULTIPLE_OF | integer | 128 | For prefill operation, sequences will be padded to a multiple of provided value. | add -e in docker run command |
| SKIP_TOKENIZER_IN_TGI | True/False | False | Skip tokenizer for input/output processing | add -e in docker run command |
| WARMUP_ENABLED | True/False | True | Enable warmup during server initialization to recompile all graphs. This can increase TGI setup time. | add -e in docker run command |
| QUEUE_THRESHOLD_MS | integer | 120 | Controls the threshold beyond which the request are considered overdue and handled with priority. Shorter requests are prioritized otherwise. | add -e in docker run command |
Profiler
To collect performance profiling, please set below environment variables:
| Name | Value(s) | Default | Description | Usage |
|---|---|---|---|---|
| PROF_WAITSTEP | integer | 0 | Control profile wait steps | add -e in docker run command |
| PROF_WARMUPSTEP | integer | 0 | Control profile warmup steps | add -e in docker run command |
| PROF_STEP | integer | 0 | Enable/disable profile, control profile active steps | add -e in docker run command |
| PROF_PATH | string | /tmp/hpu_profile | Define profile folder | add -e in docker run command |
| PROF_RANKS | string | 0 | Comma-separated list of ranks to profile | add -e in docker run command |
| PROF_RECORD_SHAPES | True/False | False | Control record_shapes option in the profiler | add -e in docker run command |
The license to use TGI on Habana Gaudi is the one of TGI: https://github.com/huggingface/text-generation-inference/blob/main/LICENSE
Please reach out to api-enterprise@huggingface.co if you have any question.