mirror of
https://github.com/huggingface/text-generation-inference.git
synced 2025-09-10 20:04:52 +00:00
Added bnb
This commit is contained in:
parent
5347eb4055
commit
937e4269e1
@ -36,3 +36,38 @@ You can learn more about the quantization options by running `text-generation-se
|
||||
|
||||
If you wish to do more with GPTQ models (e.g. train an adapter on top), you can read about transformers GPTQ integration [here](https://huggingface.co/blog/gptq-integration).
|
||||
You can learn more about GPTQ from the [paper](https://arxiv.org/pdf/2210.17323.pdf).
|
||||
|
||||
## Quantization with bitsandbytes
|
||||
|
||||
bitsandbytes is a library used to apply 8-bit and 4-bit quantization to models. It can be used during training for mixed-precision training or before inference to make the model smaller.
|
||||
|
||||
8-bit quantization enables multi-billion parameter scale models to fit in smaller hardware without degrading performance. 8bit quantization works as follows 👇
|
||||
|
||||
1. Extract the larger values (outliers) columnwise from the input hidden states.
|
||||
2. Perform the matrix multiplication of the outliers in FP16 and the non-outliers in int8.
|
||||
3. Scale up the non-outlier results to pull the values back to FP16, and add them to outlier results in FP16.
|
||||
|
||||

|
||||
|
||||
So essentially, we perform the matrix multiplication to save on precision, and then pull the non-outlier results back to FP16 without a lot of difference between non-outlier's initial value and scaled back value. You can see an example below 👇
|
||||
|
||||
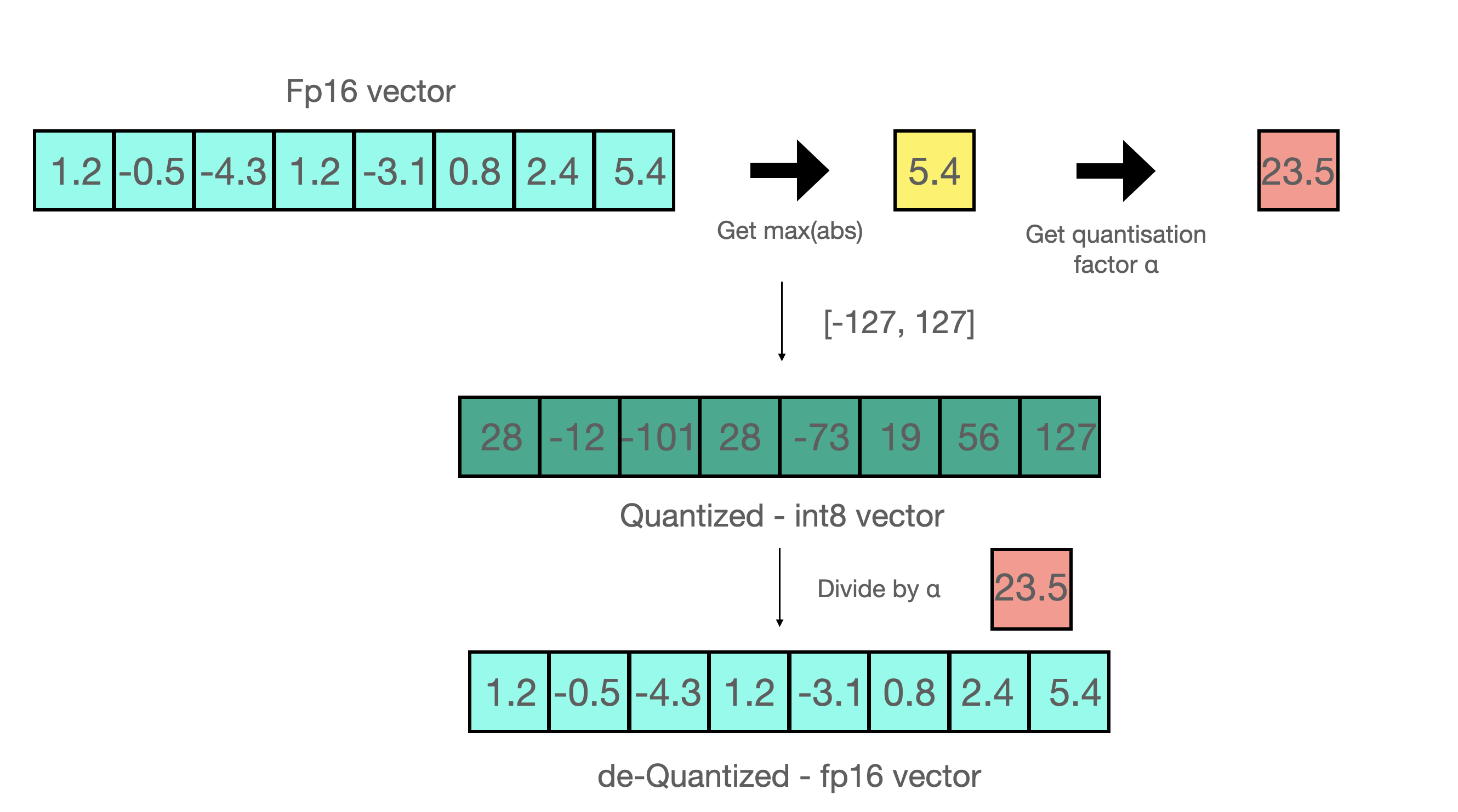
|
||||
|
||||
In TGI, you can use 8-bit quantization by adding `--quantize bitsandbytes` like below 👇
|
||||
|
||||
```bash
|
||||
docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:latest --model-id $model --quantize --bitsandbytes-nf4
|
||||
|
||||
```
|
||||
|
||||
One caveat of bitsandbytes 8-bit quantization is that the inference speed is slower compared to GPTQ.
|
||||
|
||||
4-bit Float (FP4) and 4-bit NormalFloat (NF4) are two data types introduced to use with QLoRA technique, a parameter efficient fine-tuning technique. However, these data types can be used to make a pre-trained model smaller. TGI essentially uses these data types to quantize an already trained model before the inference.
|
||||
|
||||
In TGI, you can use 4-bit quantization by adding `--quantize bitsandbytes-nf4` or `--quantize bitsandbytes-fp4` like below 👇
|
||||
|
||||
```bash
|
||||
docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:latest --model-id $model --quantize --bitsandbytes-nf4
|
||||
```
|
||||
|
||||
You can get more information about 8-bit quantization by reading this [blog post](https://huggingface.co/blog/hf-bitsandbytes-integration), and 4-bit quantization by reading [this blog post](https://huggingface.co/blog/4bit-transformers-bitsandbytes).
|
||||
|
||||
Loading…
Reference in New Issue
Block a user