mirror of
https://github.com/huggingface/text-generation-inference.git
synced 2025-09-10 20:04:52 +00:00
Update flash_attention.md
This commit is contained in:
parent
172d262adf
commit
7037d0259f
@ -1,7 +1,12 @@
|
||||
# Flash Attention
|
||||
|
||||
Scaling the transformer architecture is heavily bottlenecked by the self-attention mechanism, which has quadratic time and memory complexity. Recent developments in accelerator hardware mainly focus on enhancing compute capacities and not memory and transferring data between hardware. This results in attention operation having a memory bottleneck, also called memory-bound. **Flash Attention** is an attention algorithm used to reduce this problem and scale transformer-based models more efficiently, enabling faster training and inference.
|
||||
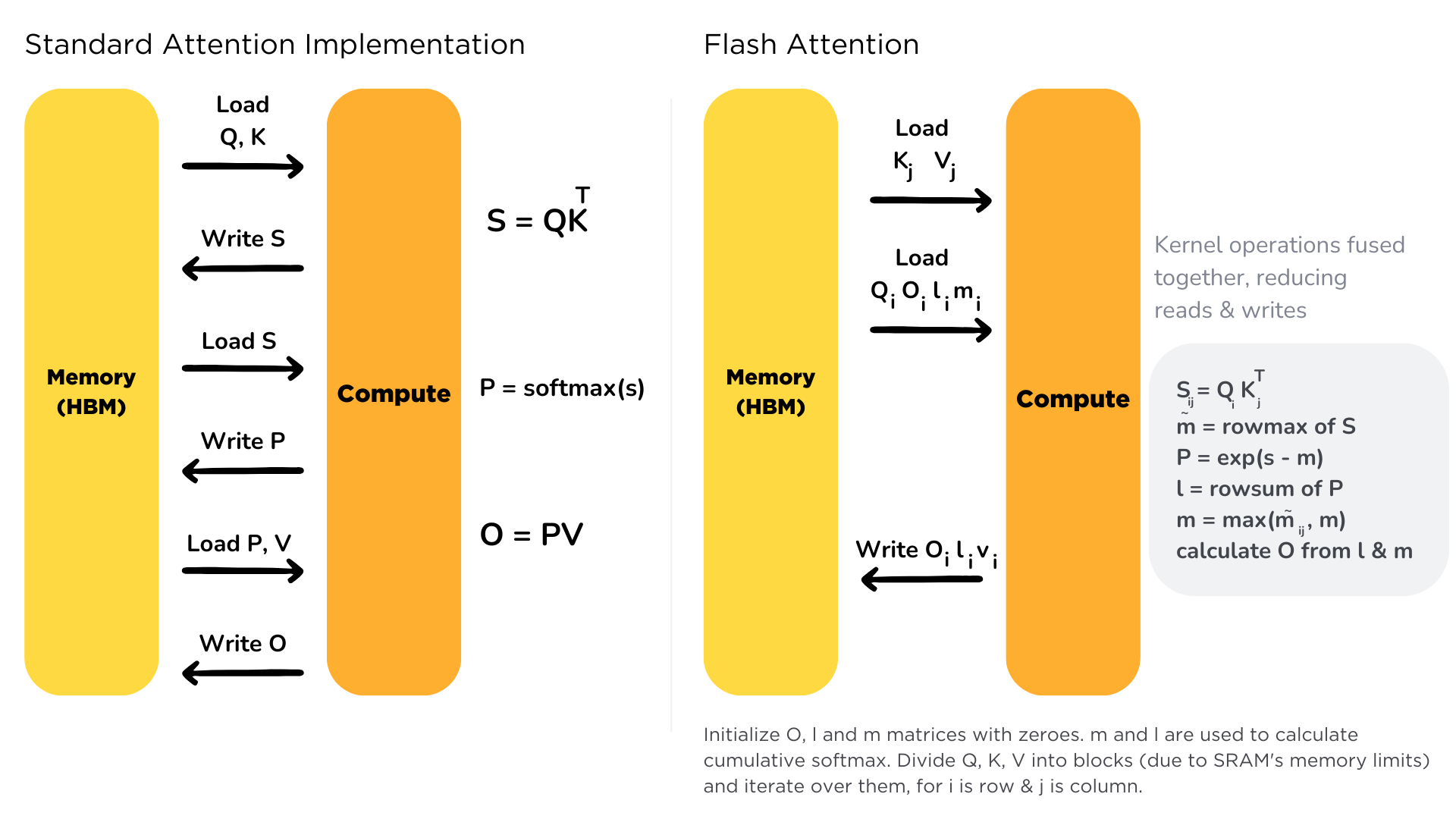
In the standard attention implementation, the cost of loading and writing keys, queries, and values from High Bandwidth Memory (HBM) is high. It loads key, query, and value from HBM to GPU on-chip SRAM, performs a single step of the attention mechanism, writes it back to HBM, and repeats this for every single attention step. Instead, Flash Attention loads keys, queries, and values once, fuses the operations of the attention mechanism, and writes them back.
|
||||
It is implemented for models with custom kernels. You can check out the complete list of models that support Flash Attention [here](https://github.com/huggingface/text-generation-inference/tree/main/server/text_generation_server/models).
|
||||
Scaling the transformer architecture is heavily bottlenecked by the self-attention mechanism, which has quadratic time and memory complexity. Recent developments in accelerator hardware mainly focus on enhancing compute capacities and not memory and transferring data between hardware. This results in attention operation having a memory bottleneck. **Flash Attention** is an attention algorithm used to reduce this problem and scale transformer-based models more efficiently, enabling faster training and inference.
|
||||
|
||||
In the standard attention implementation, the cost of loading and writing keys, queries, and values from High Bandwidth Memory (HBM) is high. It loads keys, queries, and values from HBM to GPU on-chip SRAM, performs a single step of the attention mechanism, writes it back to HBM, and repeats this for every single attention step. Instead, Flash Attention loads keys, queries, and values once, fuses the operations of the attention mechanism, and writes them back.
|
||||
|
||||
|
||||
|
||||
It is implemented for supported models. You can check out the complete list of models that support Flash Attention [here](https://github.com/huggingface/text-generation-inference/tree/main/server/text_generation_server/models), for models with flash prefix.
|
||||
|
||||
You can learn more about Flash Attention by reading the paper in this [link](https://arxiv.org/abs/2205.14135).
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user