mirror of
https://github.com/huggingface/text-generation-inference.git
synced 2025-09-12 04:44:52 +00:00
Suggestions from Lucain.
This commit is contained in:
parent
98d66f0534
commit
552ee136d8
@ -1,13 +1,17 @@
|
||||
# Consuming Text Generation Inference
|
||||
|
||||
There are many ways to consume Text Generation Inference (TGI) server in your applications. After launching the server, you can use the [Messages API](https://huggingface.co/docs/text-generation-inference/en/messages_api) `/v1/chat/completions` route and make a `POST` request to get results from the server. You can also pass `"stream": true` to the call if you want TGI to return a stream of tokens. You can make the requests using the tool of your preference, such as curl, Python or TypeScript. For a final end-to-end experience, we have also open-sourced ChatUI, a chat interface for open-source models.
|
||||
There are many ways to consume Text Generation Inference (TGI) server in your applications. After launching the server, you can use the [Messages API](https://huggingface.co/docs/text-generation-inference/en/messages_api) `/v1/chat/completions` route and make a `POST` request to get results from the server. You can also pass `"stream": true` to the call if you want TGI to return a stream of tokens. While `/generate` and `/generate_stream` are still available, the Messages API is recommended as it automatically applies the chat template.
|
||||
|
||||
For more information on the API, consult the OpenAPI documentation of the `text-generation-inference` available [here](https://huggingface.github.io/text-generation-inference).
|
||||
|
||||
You can make the requests using any tool of your preference, such as curl, Python or TypeScript. For an end-to-end experience, we've open-sourced ChatUI, a chat interface for open-source models.
|
||||
|
||||
## curl
|
||||
|
||||
After a successful server launch, you can query the model using the `v1/chat/completions` route to get OpenAI Chat Completion API spec compliant responses:
|
||||
|
||||
```bash
|
||||
curl localhost:3000/v1/chat/completions \
|
||||
curl -N localhost:3000/v1/chat/completions \
|
||||
-X POST \
|
||||
-d '{
|
||||
"model": "tgi",
|
||||
@ -29,9 +33,17 @@ curl localhost:3000/v1/chat/completions \
|
||||
|
||||
You can update the `stream` parameter to `false` to get a non-streaming response.
|
||||
|
||||
## OpenAI Client
|
||||
## Python
|
||||
|
||||
You can directly use the OpenAI Python/ JS client to interact with TGI.
|
||||
### OpenAI Client
|
||||
|
||||
You can directly use the OpenAI [Python](https://github.com/openai/openai-python)/ [JS](https://github.com/openai/openai-node) client to interact with TGI.
|
||||
|
||||
Install the OpenAI Python package via pip.
|
||||
|
||||
```bash
|
||||
pip install openai
|
||||
```
|
||||
|
||||
```python
|
||||
from openai import OpenAI
|
||||
@ -56,10 +68,11 @@ for message in chat_completion:
|
||||
print(message)
|
||||
```
|
||||
|
||||
## Inference Client
|
||||
### Inference Client
|
||||
|
||||
[`huggingface-hub`](https://huggingface.co/docs/huggingface_hub/main/en/index) is a Python library to interact with the Hugging Face Hub, including its endpoints. It provides a nice high-level class, [`~huggingface_hub.InferenceClient`], which makes it easy to make calls to a TGI endpoint. `InferenceClient` also takes care of parameter validation and provides a simple to-use interface.
|
||||
You can simply install `huggingface-hub` package with pip.
|
||||
[`huggingface-hub`](https://huggingface.co/docs/huggingface_hub/main/en/index) is a Python library to interact with the Hugging Face Hub, including its endpoints. It provides a high-level class, [`~huggingface_hub.InferenceClient`], which makes it easy to make calls to TGI's Messages API. `InferenceClient` also takes care of parameter validation and provides a simple to-use interface.
|
||||
|
||||
Install `huggingface-hub` package via pip.
|
||||
|
||||
```bash
|
||||
pip install huggingface-hub
|
||||
@ -68,40 +81,35 @@ pip install huggingface-hub
|
||||
Once you start the TGI server, instantiate `InferenceClient()` with the URL to the endpoint serving the model. You can then call `text_generation()` to hit the endpoint through Python.
|
||||
|
||||
```python
|
||||
from huggingface_hub import InferenceClient
|
||||
- from openai import OpenAI
|
||||
+ from huggingface_hub import InferenceClient
|
||||
|
||||
client = InferenceClient(model="http://127.0.0.1:8080")
|
||||
client.text_generation(prompt="Write a code for snake game")
|
||||
- client = OpenAI(
|
||||
+ client = InferenceClient(
|
||||
base_url=...,
|
||||
api_key=...,
|
||||
)
|
||||
|
||||
|
||||
output = client.chat.completions.create(
|
||||
model="tgi",
|
||||
messages=[
|
||||
{"role": "system", "content": "You are a helpful assistant."},
|
||||
{"role": "user", "content": "Count to 10"},
|
||||
],
|
||||
stream=True,
|
||||
max_tokens=1024,
|
||||
)
|
||||
|
||||
for chunk in output:
|
||||
print(chunk.choices[0].delta.content)
|
||||
```
|
||||
|
||||
You can do streaming with `InferenceClient` by passing `stream=True`. Streaming will return tokens as they are being generated in the server. To use streaming, you can do as follows:
|
||||
You can check out more details [here](https://huggingface.co/docs/huggingface_hub/en/guides/inference#openai-compatibility). There is also an async version of the client, `AsyncInferenceClient`, based on `asyncio` and `aiohttp`. You can find docs for it [here](https://huggingface.co/docs/huggingface_hub/package_reference/inference_client#huggingface_hub.AsyncInferenceClient)
|
||||
|
||||
```python
|
||||
for token in client.text_generation("How do you make cheese?", max_new_tokens=12, stream=True):
|
||||
print(token)
|
||||
```
|
||||
## UI
|
||||
|
||||
Another parameter you can use with TGI backend is `details`. You can get more details on generation (tokens, probabilities, etc.) by setting `details` to `True`. When it's specified, TGI will return a `TextGenerationResponse` or `TextGenerationStreamResponse` rather than a string or stream.
|
||||
|
||||
```python
|
||||
output = client.text_generation(prompt="Meaning of life is", details=True)
|
||||
print(output)
|
||||
|
||||
# TextGenerationResponse(generated_text=' a complex concept that is not always clear to the individual. It is a concept that is not always', details=Details(finish_reason=<FinishReason.Length: 'length'>, generated_tokens=20, seed=None, prefill=[], tokens=[Token(id=267, text=' a', logprob=-2.0723474, special=False), Token(id=11235, text=' complex', logprob=-3.1272552, special=False), Token(id=17908, text=' concept', logprob=-1.3632495, special=False),..))
|
||||
```
|
||||
|
||||
You can see how to stream below.
|
||||
|
||||
```python
|
||||
output = client.text_generation(prompt="Meaning of life is", stream=True, details=True)
|
||||
print(next(iter(output)))
|
||||
|
||||
# TextGenerationStreamResponse(token=Token(id=267, text=' a', logprob=-2.0723474, special=False), generated_text=None, details=None)
|
||||
```
|
||||
|
||||
You can check out the details of the function [here](https://huggingface.co/docs/huggingface_hub/main/en/package_reference/inference_client#huggingface_hub.InferenceClient.text_generation). There is also an async version of the client, `AsyncInferenceClient`, based on `asyncio` and `aiohttp`. You can find docs for it [here](https://huggingface.co/docs/huggingface_hub/package_reference/inference_client#huggingface_hub.AsyncInferenceClient)
|
||||
|
||||
## Gradio
|
||||
### Gradio
|
||||
|
||||
Gradio is a Python library that helps you build web applications for your machine learning models with a few lines of code. It has a `ChatInterface` wrapper that helps create neat UIs for chatbots. Let's take a look at how to create a chatbot with streaming mode using TGI and Gradio. Let's install Gradio and Hub Python library first.
|
||||
|
||||
@ -154,16 +162,9 @@ You can check out the UI and try the demo directly here 👇
|
||||
</div>
|
||||
|
||||
|
||||
You can disable streaming mode using `return` instead of `yield` in your inference function, like below.
|
||||
|
||||
```python
|
||||
def inference(message, history):
|
||||
return client.text_generation(message, max_new_tokens=20)
|
||||
```
|
||||
|
||||
You can read more about how to customize a `ChatInterface` [here](https://www.gradio.app/guides/creating-a-chatbot-fast).
|
||||
|
||||
## ChatUI
|
||||
### ChatUI
|
||||
|
||||
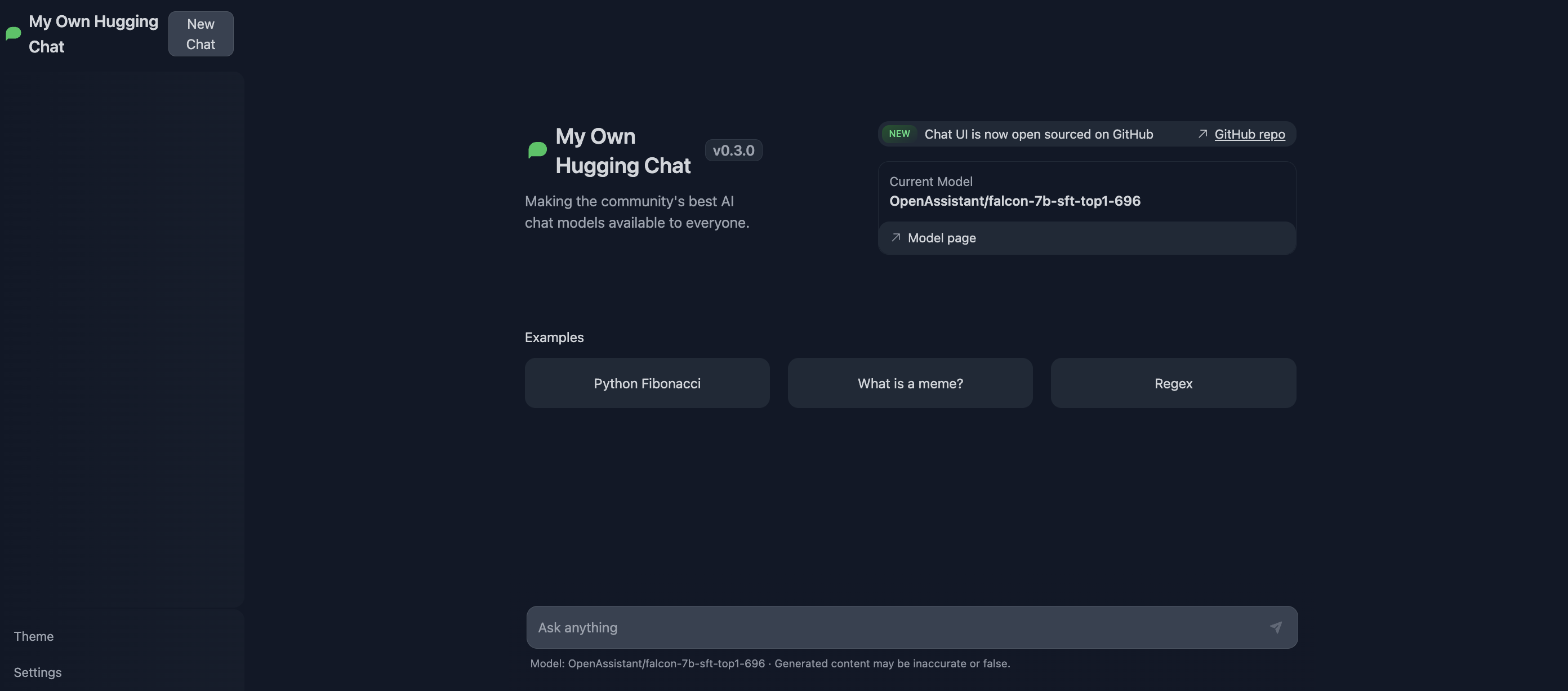
[ChatUI](https://github.com/huggingface/chat-ui) is an open-source interface built for consuming LLMs. It offers many customization options, such as web search with SERP API and more. ChatUI can automatically consume the TGI server and even provides an option to switch between different TGI endpoints. You can try it out at [Hugging Chat](https://huggingface.co/chat/), or use the [ChatUI Docker Space](https://huggingface.co/new-space?template=huggingchat/chat-ui-template) to deploy your own Hugging Chat to Spaces.
|
||||
|
||||
@ -176,8 +177,4 @@ To serve both ChatUI and TGI in same environment, simply add your own endpoints
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
## API documentation
|
||||
|
||||
You can consult the OpenAPI documentation of the `text-generation-inference` REST API using the `/docs` route. The Swagger UI is also available [here](https://huggingface.github.io/text-generation-inference).
|
||||

|
||||
Loading…
Reference in New Issue
Block a user