mirror of
https://github.com/huggingface/text-generation-inference.git
synced 2025-09-10 20:04:52 +00:00
Update consuming_tgi.md
This commit is contained in:
parent
bce5e22444
commit
452f8f3c2b
@ -75,6 +75,44 @@ To serve both ChatUI and TGI in same environment, simply add your own endpoints
|
||||
|
||||
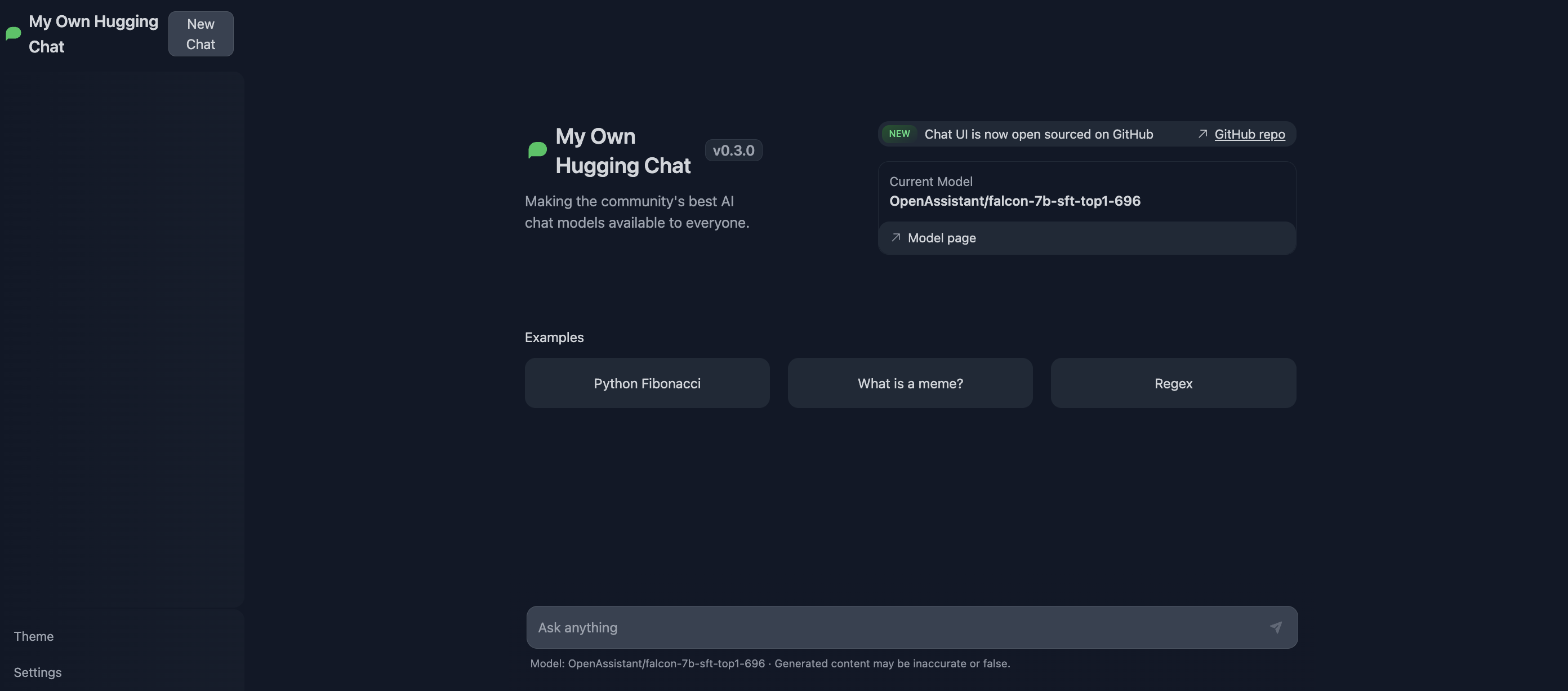
|
||||
|
||||
## Gradio
|
||||
|
||||
Gradio has a `ChatInterface` class to create neat UIs for chatbots. Let's take a look at how to create a chatbot with streaming mode using TGI and Gradio. Assume you are serving your model on port 8080.
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
from huggingface_hub import InferenceClient
|
||||
|
||||
# initialize InferenceClient
|
||||
client = InferenceClient(model="http://127.0.0.1:8080")
|
||||
|
||||
# query client using streaming mode
|
||||
def inference(message, history):
|
||||
partial_message = ""
|
||||
for token in client.text_generation(message, max_new_tokens=20, stream=True):
|
||||
partial_message += token
|
||||
yield partial_message
|
||||
|
||||
gr.ChatInterface(
|
||||
inference,
|
||||
chatbot=gr.Chatbot(height=300),
|
||||
textbox=gr.Textbox(placeholder="Chat with me!", container=False, scale=7),
|
||||
description="This is the demo for Gradio UI consuming TGI endpoint with Falcon model.",
|
||||
title="Gradio 🤝 TGI",
|
||||
examples=["Are tomatoes vegetables?"],
|
||||
retry_btn=None,
|
||||
undo_btn="Undo",
|
||||
clear_btn="Clear",
|
||||
).queue().launch()
|
||||
```
|
||||
|
||||
The UI looks like this 👇
|
||||
|
||||

|
||||
|
||||
You can disable streaming mode using `return` instead of `yield` in your inference function.
|
||||
You can read more about how to customize a `ChatInterface` [here](https://www.gradio.app/guides/creating-a-chatbot-fast).
|
||||
|
||||
## API documentation
|
||||
|
||||
You can consult the OpenAPI documentation of the `text-generation-inference` REST API using the `/docs` route. The Swagger UI is also available [here](https://huggingface.github.io/text-generation-inference).
|
||||
|
||||
Loading…
Reference in New Issue
Block a user